
Hermes上线MoA功能!比Opus 4.8和GPT-5.5还猛
Hermes上线MoA功能!比Opus 4.8和GPT-5.5还猛近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。
来自主题: AI资讯
9013 点击 2026-07-01 00:22
 搜索
搜索
近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。

你有没有想过,以后人们做购买决定的地方,可能不再是搜索框,而是一个对话框?

AI圈彻底进入生死时速!OpenAI和Anthropic极限狂飙,平均51天空降一个新模型,直接把谷歌甩在了身后。

今年初,ChatGPT 开始小范围测试卖广告。半年过去,我们很好奇:那些真正把预算投进去的人,看到了什么?

你以为自己在用GPT-5.5,但OpenAI可能已经在后台,悄悄把你的底层模型换成了更先进的GPT-5.6 Sol。
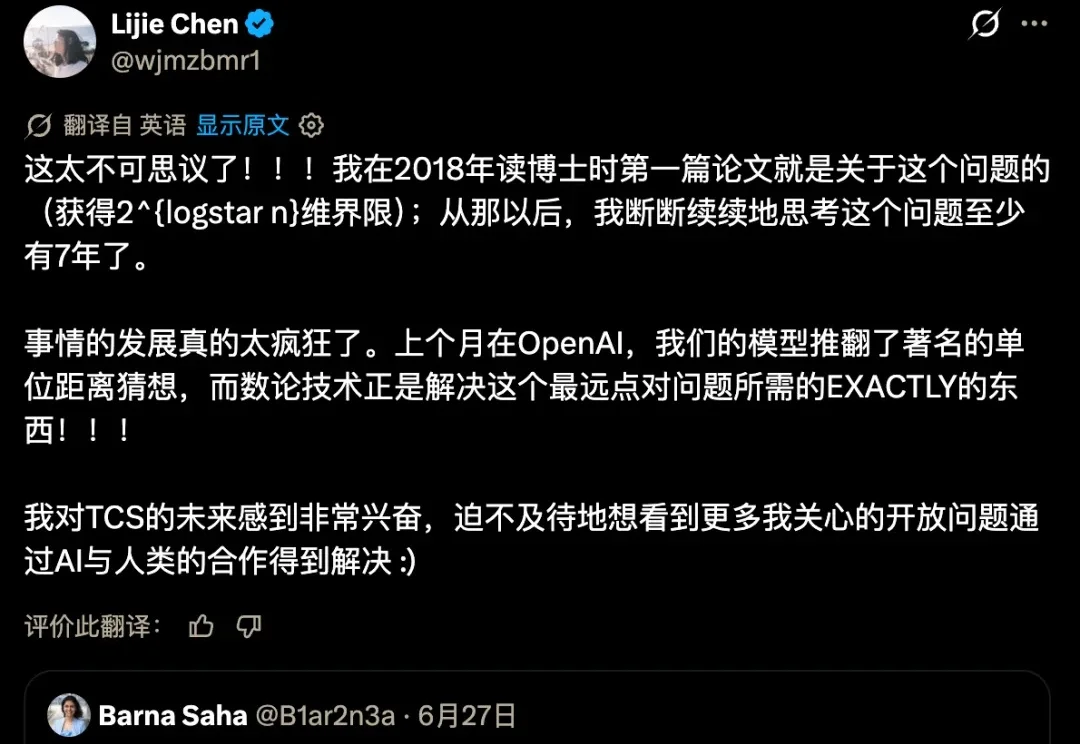
GPT-5.5 Pro 生成了一个数学证明,解决了计算几何中一个 陈立杰苦思 7 年未解的核心难题。关键技术来自 OpenAI 上月的另一项突破,而最初推进这个问题的陈立杰发现,钥匙竟是自己参与的工作。

最后一个GPT-4走了。4个半月,OpenAI清空整个GPT-4家族,GPT-4.5是其中最后一个退场的。没有告别,只有一行更新日志——一个模型的退役,正在变成AI圈的日常。

GPT-5.6 Sol被拆分、被按住,Fable 5被全球禁用72小时后才戴着镣铐回归。Anthropic和OpenAI最强模型,双双被「切脑」。

就在最近,英国前首相府数据科学家Liam Wilkinson,花一个周末搭了76个MCP工具,把Claude、GPT、Gemini等四个顶尖模型扔进了《文明VI》。结果,23场对局打完,其中一个AI造了核弹炸了法国——然后输了。

大家都会以为,AI 会重构电商,甚至会完成自身的闭环交易,取代传统电商。但事实看起来却不是这样,ChatGPT 上线的 checkout 功能并没有获得预期的成功,Shopify、Amazon 这些电商平台依旧活得很好。