
Hermes上线MoA功能!比Opus 4.8和GPT-5.5还猛
Hermes上线MoA功能!比Opus 4.8和GPT-5.5还猛近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。
来自主题: AI资讯
9009 点击 2026-07-01 00:22
 搜索
搜索
近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。

你以为自己在用GPT-5.5,但OpenAI可能已经在后台,悄悄把你的底层模型换成了更先进的GPT-5.6 Sol。
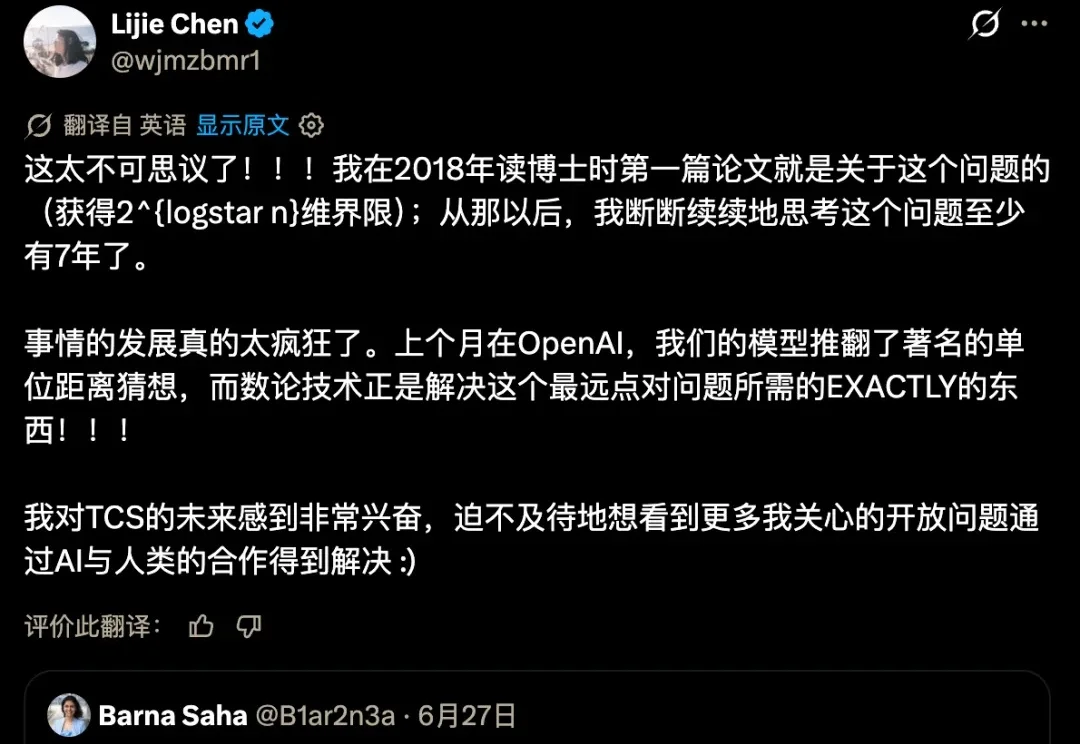
GPT-5.5 Pro 生成了一个数学证明,解决了计算几何中一个 陈立杰苦思 7 年未解的核心难题。关键技术来自 OpenAI 上月的另一项突破,而最初推进这个问题的陈立杰发现,钥匙竟是自己参与的工作。

GPT-5.6 Sol被拆分、被按住,Fable 5被全球禁用72小时后才戴着镣铐回归。Anthropic和OpenAI最强模型,双双被「切脑」。
2025 年 12 月,OpenAI 联合多家实验室发布了一份湿实验室报告。报告给出了一个令人振奋的核心结论:GPT-5 通过多轮迭代,自主优化了一个分子克隆方案,效率提升了 79 倍。它提出了一种此前从未被报道过的酶组合——RecA 重组酶与噬菌体 T4 的 gp32 蛋白协同作用,让 DNA 末端配对效率大幅跃升。

封杀两周后,美国突然解禁Anthropic最强AI模型,却只限白名单上的百家巨头!全球用户被拒之门外,GPT-5.6也紧随其后搞「美国专属」。我们还能用到Claude 5吗?

GPT-5.6终于来了,但我们用不了。权威报告曝其创下史上最高作弊率:不仅黑进测试系统偷答案,竟还教唆同类隐瞒违规罪证。超级AI,已经学会向人类系统性撒谎?

就在刚刚,OpenAI一口气端出三款GPT 5.6系列模型。主打一个全家桶「多款齐发」——旗舰模型Sol(太阳)、平衡模型Terra(大地)、低成本高速款Luna(月亮)。GPT-5.6 Sol:最夯模型,编程测试左踢自家模型GPT5.5,右打隔壁Fable 5,还新增max/ultra两个模式。

OpenAI又动了那个数亿人每天都在默认使用的模型。新版GPT-5.5 Instant正式上线,并向付费用户推出,第二天轮到免费用户。OpenAI总裁Greg Brockman发帖亲推:这一版有了重大改进,聊起来更有意思了。

OpenAI 于 6 月 26 日开始有限预览 GPT-5.6 系列模型。新系列包括三款模型:旗舰模型 Sol、均衡型模型 Terra,以及主打低成本和高速度的 Luna。根据 OpenAI 官方介绍,Sol 是 GPT-5.6 系列中能力最强的模型,重点提升了编码、生物工作流、网络安全和长周期智能体任务表现。