
中兴发了一篇论文,洞察AI更前沿的探索方向
中兴发了一篇论文,洞察AI更前沿的探索方向当大模型参数量冲向万亿级,GPT-4o、Llama4 等模型不断刷新性能上限时,AI 行业也正面临前所未有的瓶颈。Transformer 架构效率低、算力消耗惊人、与物理世界脱节等问题日益凸显,通用人工智能(AGI)的实现路径亟待突破。
来自主题: AI技术研报
8406 点击 2025-11-26 13:47
 搜索
搜索
当大模型参数量冲向万亿级,GPT-4o、Llama4 等模型不断刷新性能上限时,AI 行业也正面临前所未有的瓶颈。Transformer 架构效率低、算力消耗惊人、与物理世界脱节等问题日益凸显,通用人工智能(AGI)的实现路径亟待突破。
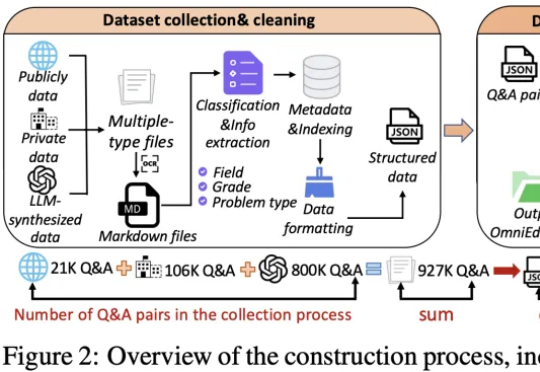
华东师范大学智能教育学院发布OmniEduBench,首次从「知识+育人」双维度评测大模型教育能力。测评2.4万道中文题后,实验结果显示:GPT-4o等顶尖AI会做题,却在启发思维、情感支持等育人能力上远不及人类,暴露AI当老师的关键短板。

AI看视频也能划重点了!
生成式AI技术的成熟,让智能编程逐渐成为众多开发者的日常,然而一个大模型API选型的“不可能三角”又随之而来:追求顶级、高速的智能(如GPT-4o/Claude 3.5),就必须接受高昂的调用成本;追求低成本,又往往要在性能和稳定性上做出妥协。开发者“既要又要”的正义,谁能给?

传统智能体系统难以兼顾稳定性和学习能力,斯坦福等学者提出AgentFlow框架,通过模块化和实时强化学习,在推理中持续优化策略,并使小规模模型在多项任务中超越GPT-4o,为AI发展开辟新思路。
OpenAI完成史上最重要的一次组织架构调整后,紧接着开了一场直播。首次公开了内部研究目标的具体时间表,其中最引人注目的是“在2028年3月实现完全自主的AI研究员”,具体到月份。
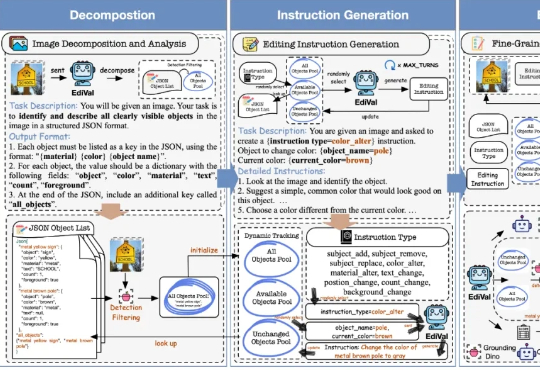
在 AIGC 的下一个阶段,图像编辑(Image Editing)正逐渐取代一次性生成,成为检验多模态模型理解、生成与推理能力的关键场景。我们该如何科学、公正地评测这些图像编辑模型?

斯坦福等新框架,用在线强化学习让智能体系统“以小搏大”,领先GPT-4o—— AgentFlow,是一种能够在线优化智能体系统的新范式,可以持续提升智能体系统对于复杂问题的推理能力。
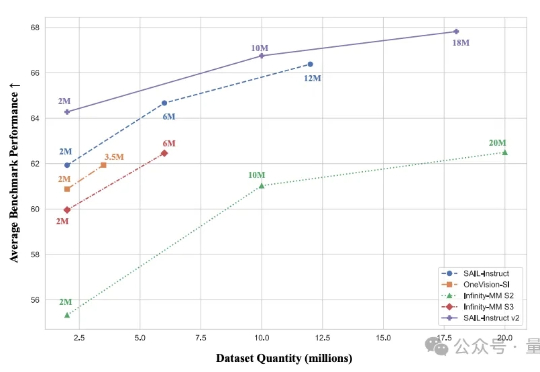
2B模型在多个基准位列4B参数以下开源第一。 抖音SAIL团队与LV-NUS Lab联合推出的多模态大模型SAIL-VL2。

游戏理解领域模型LynkSoul VLM v1,在游戏场景中表现显著超过了包括GPT-4o、Claude 4 Sonnet、Gemini 2.5 Flash等一众顶尖闭源模型。背后厂商逗逗AI,亦在现场吸引了不少关注的目光。