# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型越来越大,参数量动辄千亿,但真要在实际场景里做到“高精度+高效率”,却并不容易。
上海人工智能实验室发布新一代文档解析大模型——MinerU2.5。
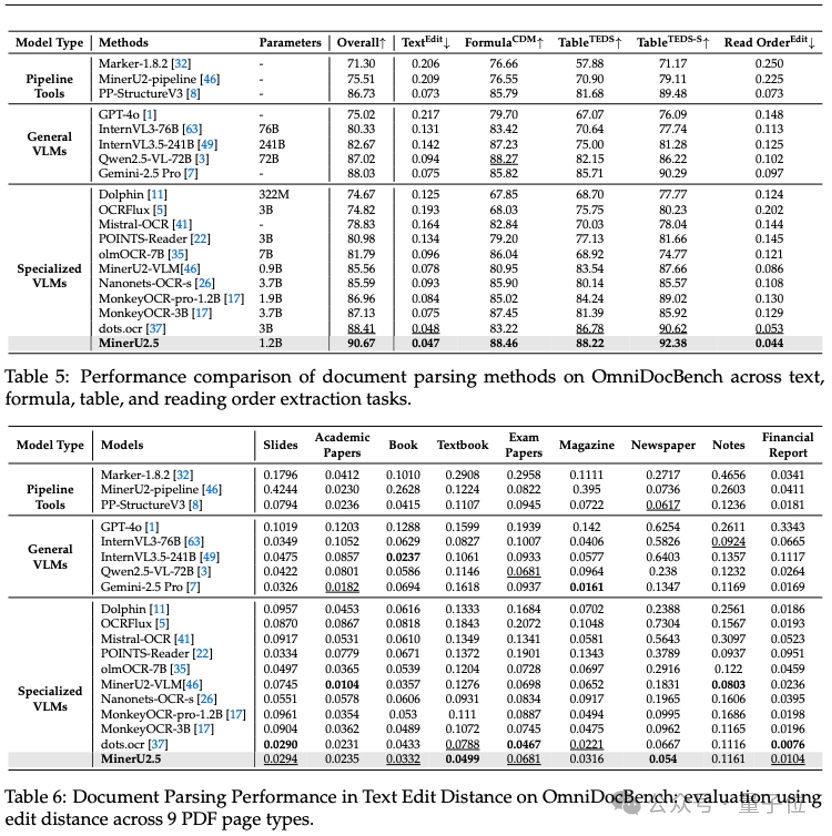
作为MinerU系列最新成果,该模型仅以1.2B参数规模,就在OmniDocBench、olmOCR-bench、Ocean-OCR等权威评测上,全面超越Gemini2.5-Pro、GPT-4o、Qwen2.5-VL-72B等主流通用大模型,以及dots.ocr、MonkeyOCR、PP-StructureV3等专业文档解析工具。
凭借高精度、多模态的文档理解与结构化输出能力,MinerU2.5尤其适合构建RAG知识库与大规模文档提取等实际应用场景。
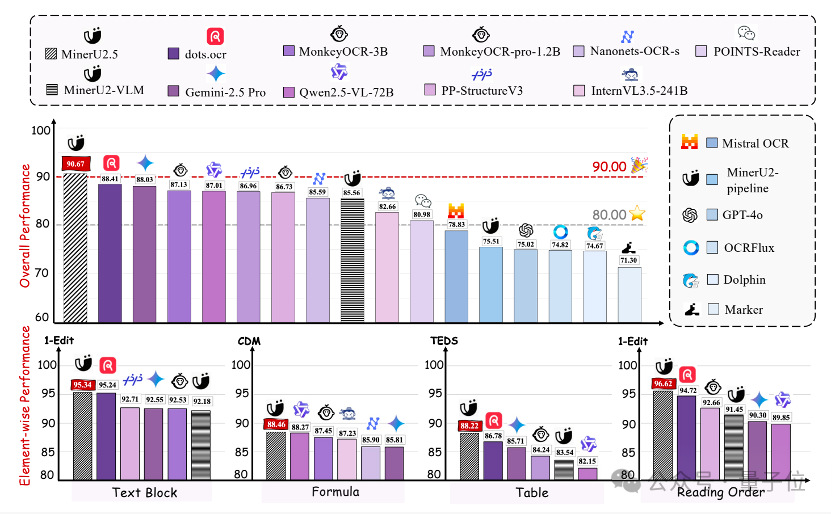
△OmniDocBench文档解析评测结果
从上图可以看出,MinerU2.5在整体解析能力及单元素解析能力维度上全面第一。不仅如此,在技术报告中,无论是文本、公式、表格,还是阅读顺序等核心解析任务,MinerU2.5都展现出卓越的技术性能。
除了在指标上全面领先外,团队还对不同类型文档的解析结果进行了人工评估。
结果显示,MinerU2.5在解析精度和用户体验上均实现显著提升,在布局检测、表格识别、公式识别、文本识别等关键任务上取得全面突破。
凭借1.2B精巧参数,MinerU2.5在大规模语料提取等生产力场景中兼顾高精度与高效率,体现出“小身材、大能量”的独特优势,展现出强大的应用价值。
为了保证模型能够轻松处理不同来源、不同难度、包含不同元素的文档,科研团队精心设计了文档解析数据引擎,为模型预训练和微调阶段提供多样性、高质量数据。
针对文档解析的预训练阶段,团队考虑从文档多样性、元素多样性、中英文数量均衡保证预训练数据的多样性,并通过多阶段模型筛选保证数据质量。
在模型微调阶段,团队采用了基于推理一致性的迭代挖掘策略,针对一阶段预训练模型挖掘困难样本,并结合智能化标注及专家修正保证数据足够复杂、精准,有效提升模型在复杂样本上的解析能力。
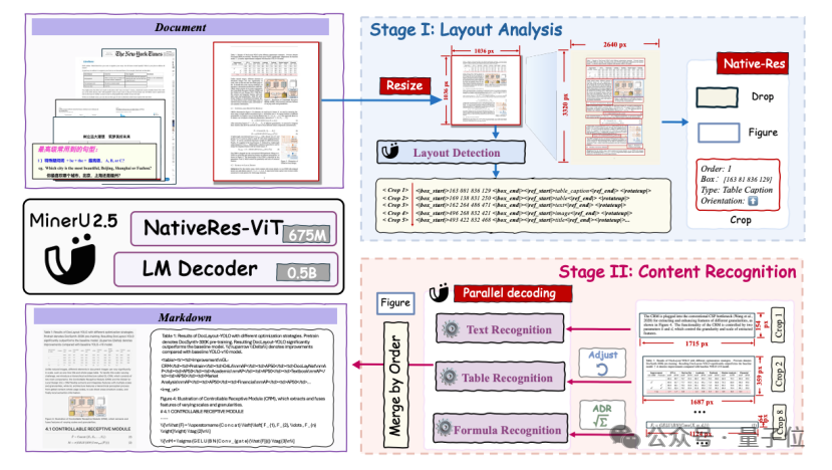
△MinerU2.5文档解析大模型技术架构
最终模型在复杂排版、复杂公式及复杂表格上性能显著提升,在其他普通样本上的解析精度更是达到了媲美人工标注员的水平。
在解析效率方面,MinerU2.5采用了QwenVL2系列的原生分辨率视觉编码器(675M)及0.5B的语言解码器,模型总参数量接近1.2B。
在布局分析阶段,MinerU2.5将高分辨率文档图像下采样到1036*1036 从而实现高效解析。在内容识别阶段,MinerU2.5仅需将切割的小区域元素进行原生分辨率编码解析,解析速度快、精度高、幻觉少。
配合vLLM参数优化及工程优化,MinerU2.5在消费级显卡4090(48G)上达到每秒1.7页的解析速度,远超其他大模型解析方案,让高质量、低成本的解析成为现实。

在出图方面,模型鲁棒性得到增强,可轻松处理各类文档:在论文、数据、考题、课本、研报、财报、PPT等多样性文档上均表现出精准的解析结果。
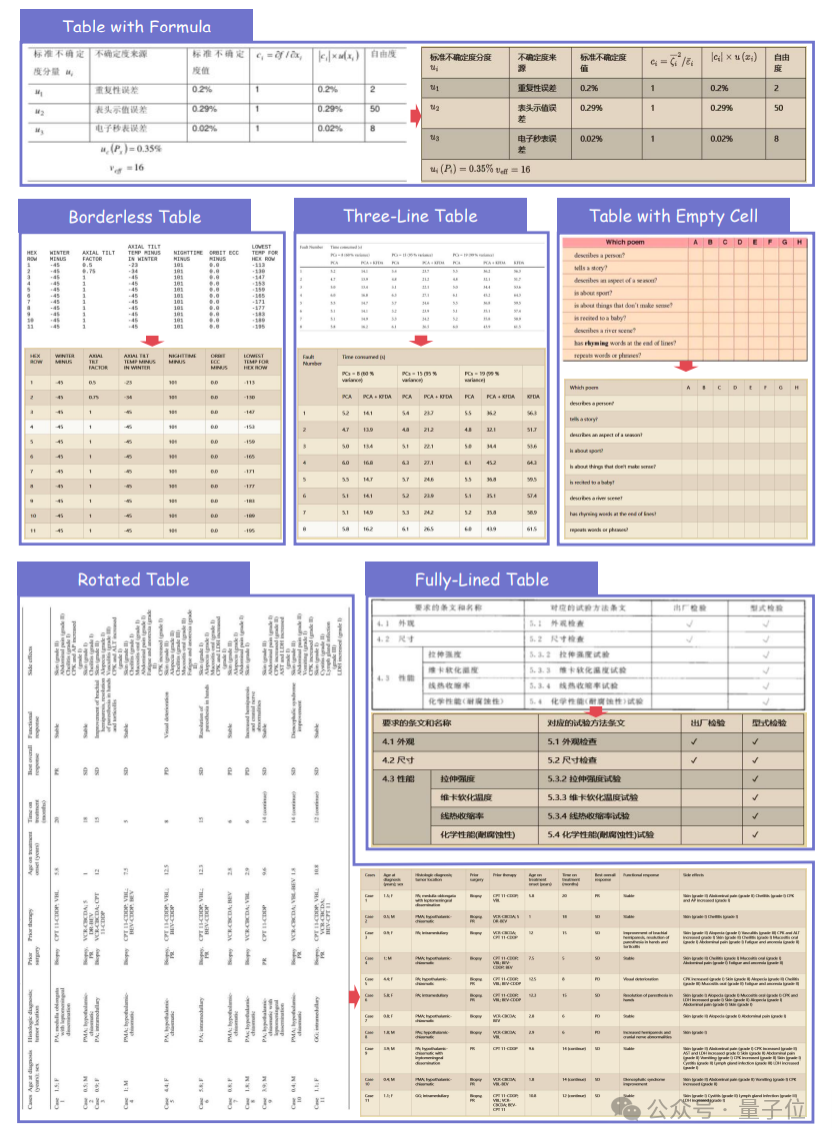
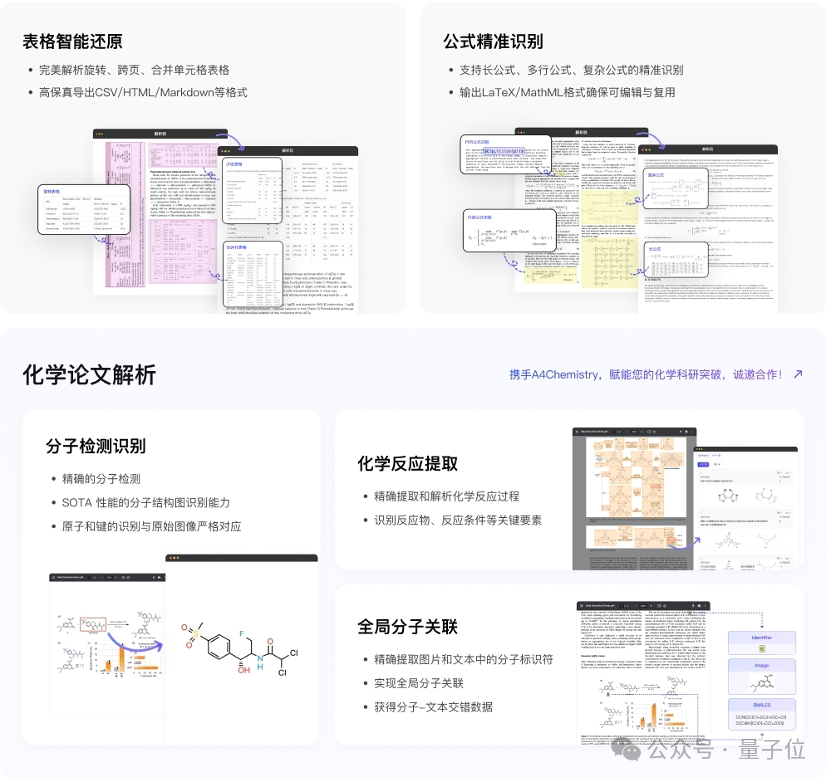
此外,表格解析能力也得到了大幅提升:在各种类别的表格上,解析能力优秀,特别是旋转表格、无线表、少线表和复杂表格上,相比于之前进步显著。
在公式解析任务上,模型对各类公式均能输出准确结果。特别地,MinerU2.5创新性地将复合公式解耦为多个原子公式进行解析,从而显著提升了针对复杂长公式的解析能力。
MinerU2.5已经全面上线,包括HuggingFace、ModelScope和GitHub在内的多平台均可获取模型下载、源码及在线Demo,科研人员和开发者都能轻松下载、运行和复现模型效果。
依托MinerU2.5多模态大模型核心能力,MinerU在线产品功能实现全面升级。
本次迭代新增了表格旋转识别、无线或少线表格解析、跨格式文档无损复制以及参考文献识别等功能,并对中文公式、复杂数学公式以及嵌套表格的解析精度进行了优化。
所有新增功能已完整融入JSON/Markdown导出、复制、翻译等重要操作,实现开箱即用、流畅无缝的使用体验。
值得一提的是,导出的JSON文件保留了页眉、页脚、页码、脚注及侧边文本等全部信息,为开发者提供了更便捷的二次处理条件,同时大幅提升了文档解析的准确性与适用范围。
△MinerU在线版已全部上架MinerU2.5最新模型能力
在国产算力生态建设方面,OpenDataLab团队采取“自主可控+开放协同”双轨策略,持续推动国产化适配与算力优化。通过与DeepLink的联合攻关,依托其开放计算体系实现多后端算力的打通,MinerU2.5得以在国产千卡级平台上稳定高效运行。
同时,MinerU2.5正在与昇腾、沐曦、摩尔线程、寒武纪、海光等国产平台完成深度适配,相关技术成果将以开源方式共享,为高性能应用场景提供可靠的产业化支撑。
在应用落地方面,MinerU已率先开发出面向N8n、扣子、FastGP、BISHENG等主流Agent平台的插件,并为钉钉、Cherry Studio、Sider等知名AI工具提供接入与技术保障。
未来,团队将继续扩展国内外主流平台及开发工具的适配范围,推动技术与重点行业应用深度融合,构建开放、兼容且可持续发展的生态体系。
技术报告:https://arxiv.org/abs/2509.22186
开源项目:https://github.com/opendatalab/MinerU
开源模型:https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B
在线使用:https://mineru.net
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
