
拾象科技李广密:硅谷大模型的融资由巨头主导、复现GPT-4是大模型竞赛的关键门槛
拾象科技李广密:硅谷大模型的融资由巨头主导、复现GPT-4是大模型竞赛的关键门槛拾象科技及其公众号「海外独角兽」一直关注海外大模型产品的技术和商业进展,近日,拾象科技 CEO 李广密和商业作者张小珺一起讨论了 2023 年全球大模型竞赛,以及接下来大模型格局会如何演进、GPT-4 的超越难度、以及需要解决的关键问题等。
来自主题: AI资讯
11882 点击 2024-01-03 10:32
 搜索
搜索
拾象科技及其公众号「海外独角兽」一直关注海外大模型产品的技术和商业进展,近日,拾象科技 CEO 李广密和商业作者张小珺一起讨论了 2023 年全球大模型竞赛,以及接下来大模型格局会如何演进、GPT-4 的超越难度、以及需要解决的关键问题等。

谷歌放出的Gemini,在对标GPT的道路上似乎一直处于劣势,Gemini真的比GPT-4弱吗?最近,斯坦福和Meta的学者发文为Gemini正名。

大型语言模型(LLM)虽然在诸多下游任务上展现出卓越的能力,但其实际应用还存在一些问题。其中,LLM 的「幻觉(hallucination)」问题是一个重要缺陷。

最近由UCSC的研究人员发表论文,证明大模型的零样本或者少样本能力,几乎都是来源于对于训练数据的记忆。
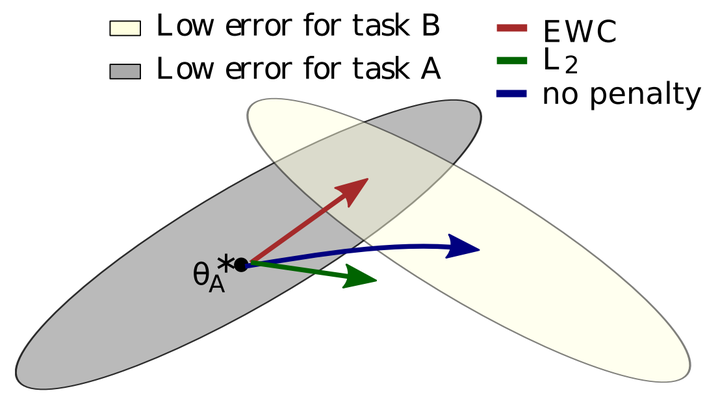
所谓灾难性遗忘,就是一个在原始任务上训练好的神经网络在训练完新任务后,在原始任务上的表现崩溃式的降低。
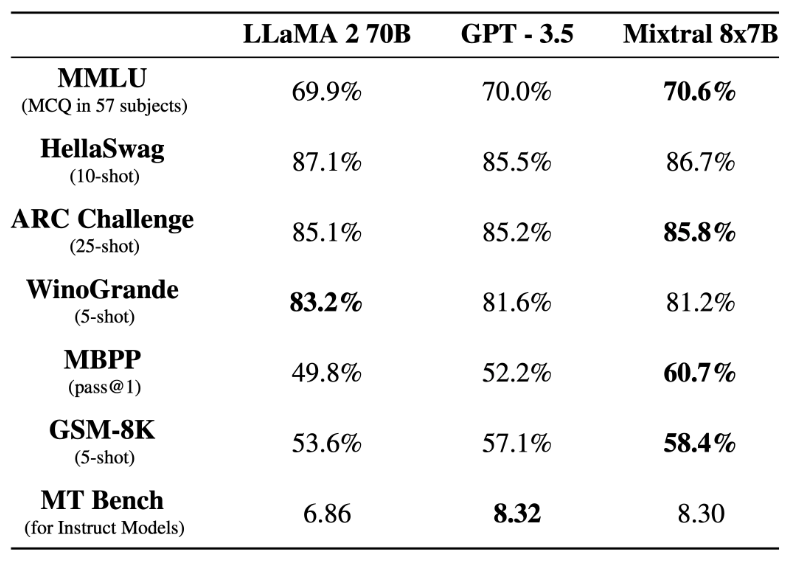
前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。

文明模拟器第二弹来了!在全面升级的GPT-4的带动下,我们将「看到」过去,更加沉浸式地体验过去的历史。

混合专家模型(MoE)成为最近关注的热点。

在2023年的科技版图上,生成式AI无疑标志着一个重要的转折点。它的发展不仅引起了业界广泛的关注,也对全球经济、社会结构乃至我们对未来的预期产生了深远的影响。

今天,纽约时报对OpenAI和微软正式提起诉讼,指控其未经授权就使用纽约时报内容训练人工智能模型。此案可能是人工智能使用知识版权纠纷的分水岭。