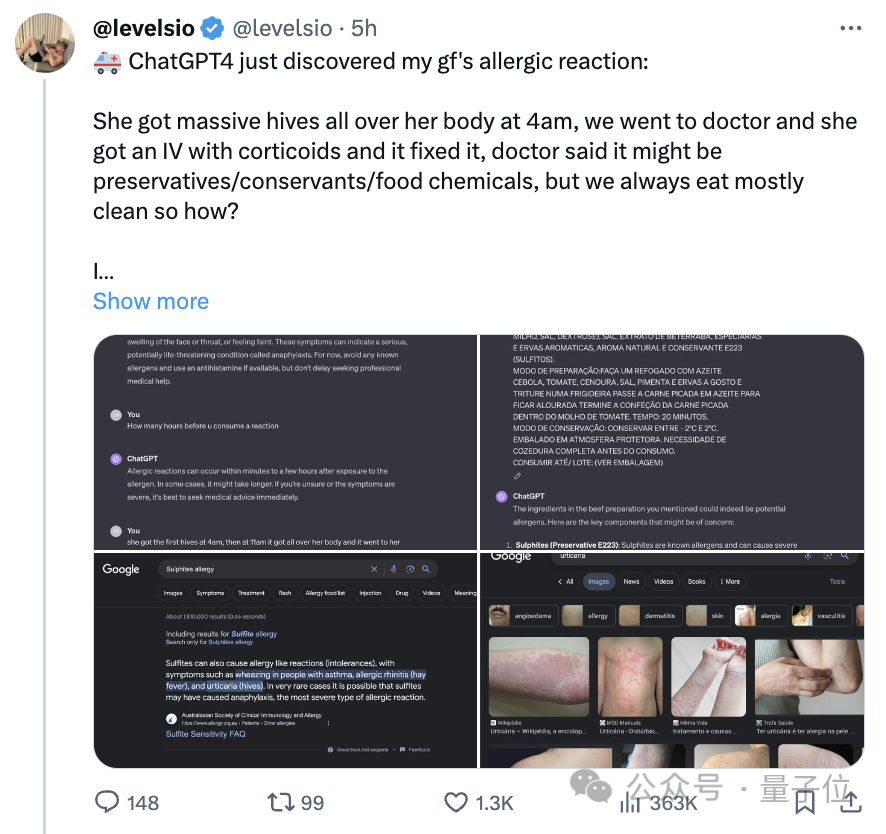
GPT-4找到我女朋友的过敏原
GPT-4找到我女朋友的过敏原GPT-4这位“江湖郎中”又被拉出来看病了,成功找到一小伙女朋友的过敏原。
来自主题: AI资讯
10700 点击 2024-01-10 09:52
 搜索
搜索
GPT-4这位“江湖郎中”又被拉出来看病了,成功找到一小伙女朋友的过敏原。
不知不觉,LangChain 已经问世一年了。作为一个开源框架,LangChain 提供了构建基于大模型的 AI 应用所需的模块和工具,大大降低了 AI 应用开发的门槛,使得任何人都可以基于 GPT-4 等大模型构建自己的创意应用。

近日,艾伦人工智能研究所发布了Unified-IO 2,——第一代Unified-IO曾预测了GPT-4等模型的能力,所以我们可以从新一代的模型中一窥GPT-5的真面目

不久之前,《纽约时报》指控 OpenAI 涉嫌违规使用其内容用于人工智能开发的事件引起了社区极大的关注与讨论。

机器人的ChatGPT时刻,真来了!初创公司Figure自家机器人看了10小时视频,学会了煮咖啡。另一边,东京大学GPT-4加持的Alter3机器人,能够模仿人类做出任何动作。而人类只需发出自然语言指令即可,完全不需要编程!

最近,来自NUS、斯坦福、谷歌DeepMind等机构的研究人员,尝试开发了一个评估人类和AI的创造力的框架。而当人类用尽所有手段来逼迫AI把创造力发挥到极限,发现GPT-4几乎对于所有事物认知的极限都是无尽的宇宙空间。

2023年3月,OpeAI以雷霆之势推出了ChatGPT,为AI产业带来了颠覆性的进展,让所有人为之震惊。其中有一项对于ChatGPT的测试还引起了了不小的轰动,当时美国伊利诺伊理工大学芝加哥肯特法学院称,GPT-4通过了美国律师资格考试,更令人感到意外的是,GPT-4的成绩堪称优异,可以超过90%的考生。

ChatGPT发布一年多,已经在全世界累积了超过1.8亿用户。而随着越来越多的人们开始频繁使用它,近几个月关于GPT-4在“变笨”、“变懒”的说法不绝于耳。

大模型固有的幻觉问题严重影响了LLM的表现。斯坦福最新研究利用维基百科数据训练大模型,得到的WikiChat成为首个几乎不产生幻觉的聊天机器人。

GPT-4V的开源替代方案来了!极低成本,性能却类似,清华、浙大等中国顶尖学府,为我们提供了性能优异的GPT-4V开源平替。