GPT-4推理能力暴涨32%,谷歌新型思维链效果超CoT,计算成本可降至1/40
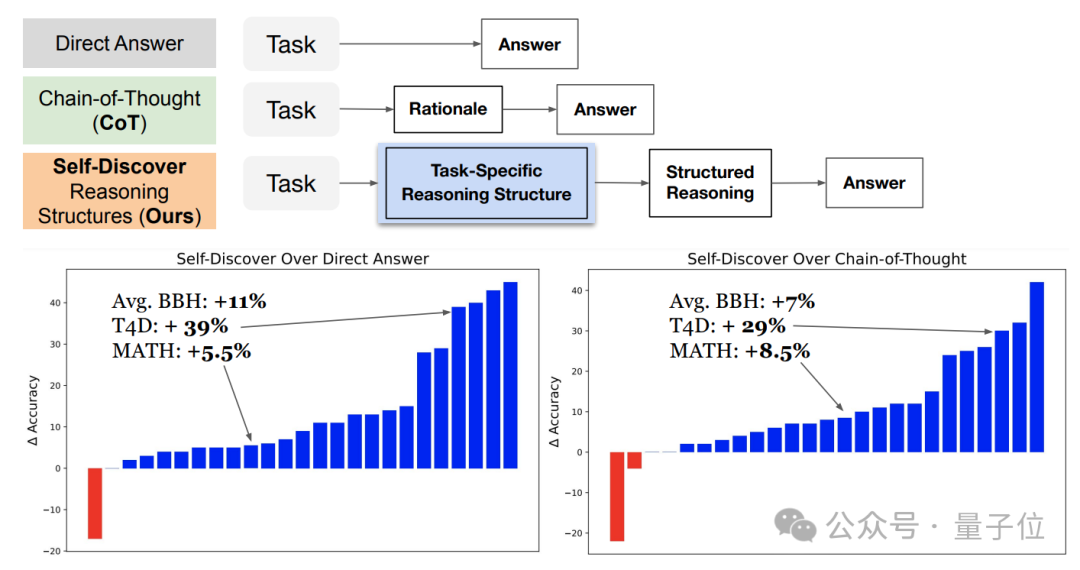
GPT-4推理能力暴涨32%,谷歌新型思维链效果超CoT,计算成本可降至1/40谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。
来自主题: AI技术研报
5589 点击 2024-02-08 19:44
 搜索
搜索
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。
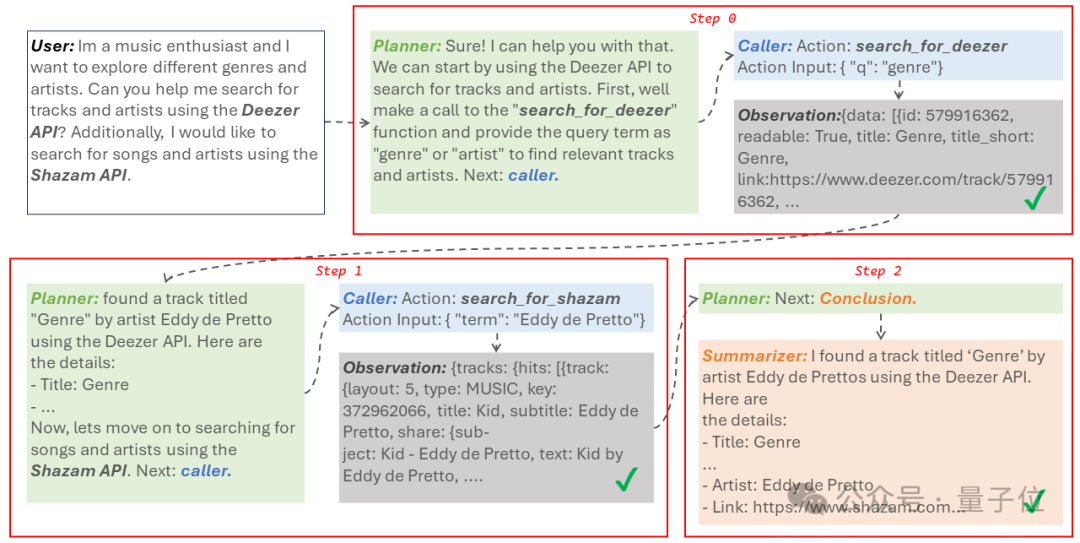

7B开源模型,数学能力超过了千亿规模的GPT-4!它的表现可谓是突破了开源模型的极限,连阿里通义的研究员也感叹缩放定律是不是失效了。
在上海人工智能实验室上周刚刚公布的测评榜单上,GPT-4依旧独领风骚,排名第一,不过国产阵营已经大踏步追了上来,差距逐步缩小。
MoE(混合专家)作为当下最顶尖、最前沿的大模型技术方向,MoE能在不增加推理成本的前提下,为大模型带来性能激增。比如,在MoE的加持之下,GPT-4带来的用户体验较之GPT-3.5有着革命性的飞升。
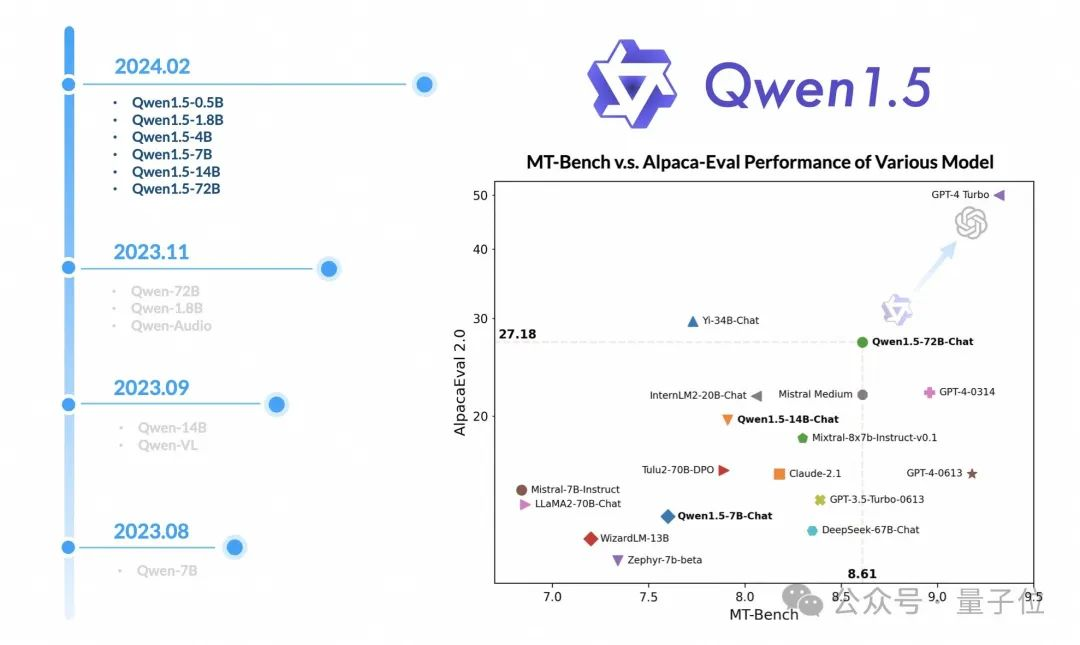
阿里大模型,再次开源大放送——发布Qwen1.5版本,直接放出六种尺寸。

「我向一位女生求婚,ChatGPT 已经和她交流了一年。为了走到这一步,AI 已经尝试了和 5239 名女生进行过沟通……」

最近,复旦、俄亥俄州立大学、Meta和宾夕法尼亚州立大学的研究者发现,GPT-4 Agent规划旅行只有0.6%成功率!离在人类复杂环境中做出规划,智能体还任重道远。
GPT-4变懒的问题,又有新进展。就在今天凌晨,奥特曼发推称,GPT-4这个毛病在新的一年应该好多了!

ChatGPT 等通用大模型支持的功能成百上千,但是对于普通日常用户来说,智能写作一定是最常见的,也是大模型最能真正帮上忙的使用场景之一。