一口气读完《沙丘》 ,零一万物宝藏API正式开箱!酷炫Demo实测,多模态中文图表体验超越GPT-4V
一口气读完《沙丘》 ,零一万物宝藏API正式开箱!酷炫Demo实测,多模态中文图表体验超越GPT-4V国产大模型独角兽送福利来了,千万token免费用!最近,零一万物API正式开放,三款模型都非常能打,开发者们赶快来开箱吧。零一万物API开放平台,正式向开发者开放了!
来自主题: AI资讯
5107 点击 2024-03-22 16:46
 搜索
搜索
国产大模型独角兽送福利来了,千万token免费用!最近,零一万物API正式开放,三款模型都非常能打,开发者们赶快来开箱吧。零一万物API开放平台,正式向开发者开放了!
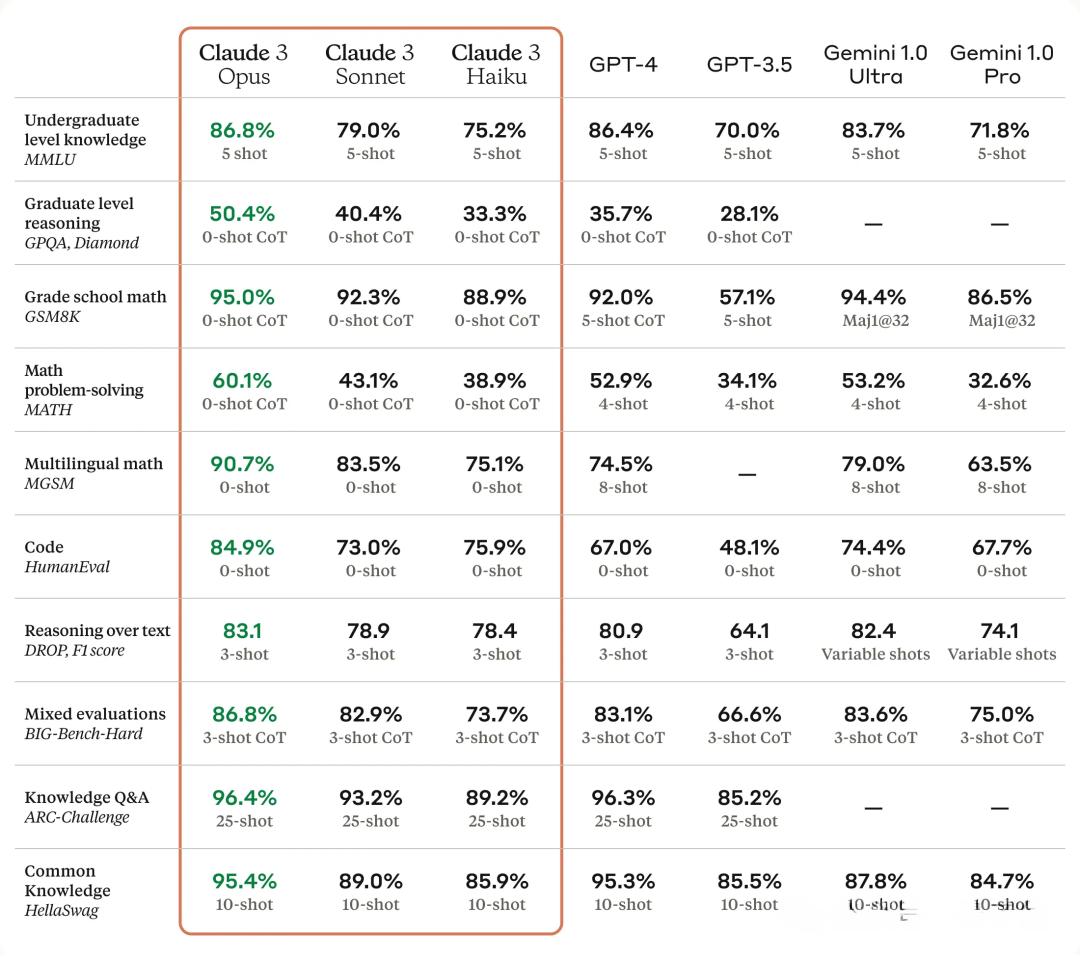
Claude3凭什么这么强?春天到了,和万物一起竞发的,还有愈发火热的AI。自2月以来,国外头部AI企业大招连出,纷纷推出了一系列强大的AI模型或技术。除了在AI圈刷屏刷到爆的Sora以外,另一匹黑马Claude 3也在三月份杀出,直接夺取了GPT-4最强大模型的地位。

距离ChatGPT、GPT-4等引爆新一轮人工智能变革的时刻,已经过去了整整一年的时间。在这一年里,国内外大量公司涌入大模型的“斗兽场”,加速大模型技术的迭代与跃迁。

今年 2 月随着 Sora 的横空出世,大家再一次把目光聚集到 OpenAI。不仅如此,去年亮相的 ChatGPT、GPT-4,更是把 AI 直接带入到生成式人工智能领域。作为一家引领科技潮流的机构,大家自然对其方方面面都产生好奇。

整个AI圈最想知道的秘密,被老黄在PPT某页的小字里写出来了?

Fast-DetectGPT 同时做到了高准确率、高速度、低成本、通用,扫清了实际应用的障碍!

全球首个AI程序员Devin的横空出世,可能成为软件和AI发展史上一个重要的节点。

全球首个AI程序员Devin诞生之后,让码农纷纷恐慌。没想到,微软同时也整出了一个AI程序员——AutoDev,能够自主生成、执行代码等任务。网友惊呼,AI编码发展太快了。
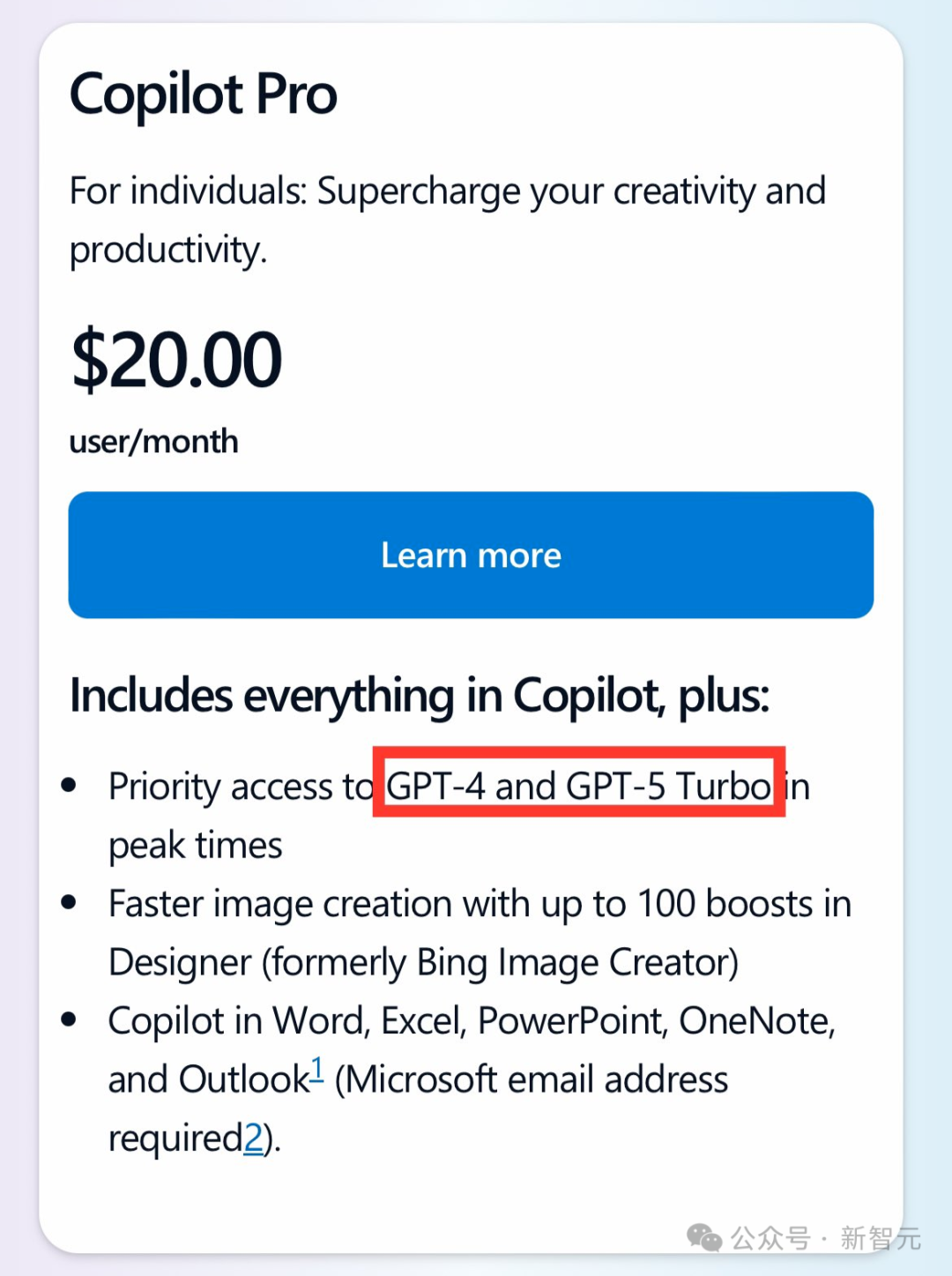
GPT-5「如来」,网上的小道消息已经传得漫天飞。然而,无论是GPT-4.5还是GPT-5,实际上未必适用于所有场景。

AI世界的进化快的有点跟不上了。刚刚,全球最强最大AI芯片WSE-3发布,4万亿晶体管5nm工艺制程。更厉害的是,WSE-3打造的单个超算可训出24万亿参数模型,相当于GPT-4/Gemini的十倍大。