
这11个小技巧,GPT-5.5和Claude 4.7的Token 烧得更值 | 附官方指南
这11个小技巧,GPT-5.5和Claude 4.7的Token 烧得更值 | 附官方指南OpenAI 和 Anthropic 几乎在同一时间发布自己的提示词文档,在 OpenAI 官网,从 GPT-4.1 到 GPT 5.5,每次新模型发布都有一份完整的提示词指南,告诉我们怎么用新的模型。
来自主题: AI资讯
9564 点击 2026-05-02 21:45
 搜索
搜索
OpenAI 和 Anthropic 几乎在同一时间发布自己的提示词文档,在 OpenAI 官网,从 GPT-4.1 到 GPT 5.5,每次新模型发布都有一份完整的提示词指南,告诉我们怎么用新的模型。

一份绝密备忘录爆出,Dario Amodei彻底撕碎了OpenAI,怒喷「安全作秀」做样子给所有人看。但不可否认的是,美国务院正大面积抛弃Claude,接入GPT-4.1。
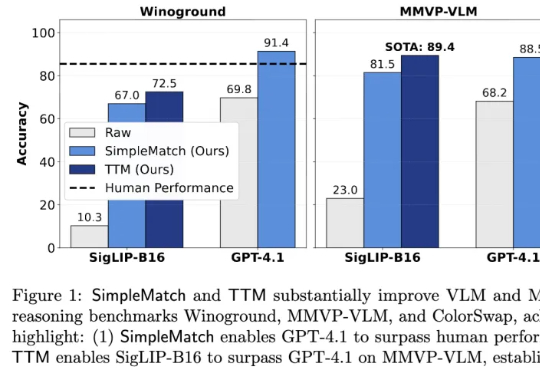
加州大学河滨分校团队发现,AI组合推理表现不佳部分源于评测指标过于苛刻。他们提出新指标GroupMatch和Test-Time Matching算法,挖掘模型潜力,使GPT-4.1在Winoground测试中首次超越人类,0.2B参数的SigLIP-B16在MMVP-VLM基准测试上超越GPT-4.1并刷新最优结果。这表明模型的组合推理能力早已存在,只需合适方法在测试阶段解锁。

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。
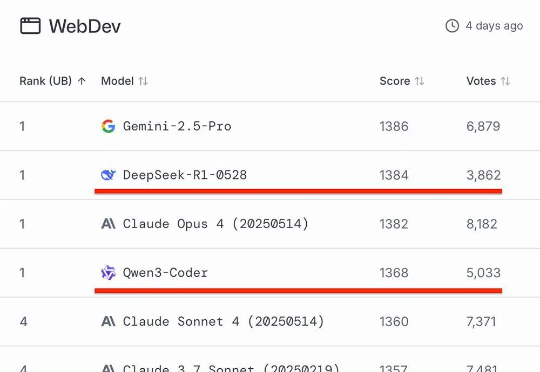
知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。
总是“死记硬背”“知其然不知其所以然”?

AI两天爆肝12年研究,精准吊打人类!多大、哈佛MIT等17家机构联手放大招,基于GPT-4.1和o3-mini,筛选文献提取数据,效率飙3000倍重塑AI科研工作流。

SemiAnalysis全新硬核爆料,意外揭秘了OpenAI全新模型的秘密?据悉,新模型介于GPT-4.1和GPT-4.5之间,而下一代推理模型o4将基于GPT-4.1训练,而背后最大功臣,就是强化学习。
近年来,语言模型技术迅速发展,然而代表性成果如Gemini 2.5Pro和GPT-4.1,逐渐被谷歌、OpenAI等科技巨头所垄断。