
一代版本一代神?新神是 GPT-2 还是 Uni-1?
一代版本一代神?新神是 GPT-2 还是 Uni-1?让AI理解人的想法,而不是让人适应AI。
来自主题: AI资讯
10474 点击 2026-04-23 15:20
 搜索
搜索
让AI理解人的想法,而不是让人适应AI。
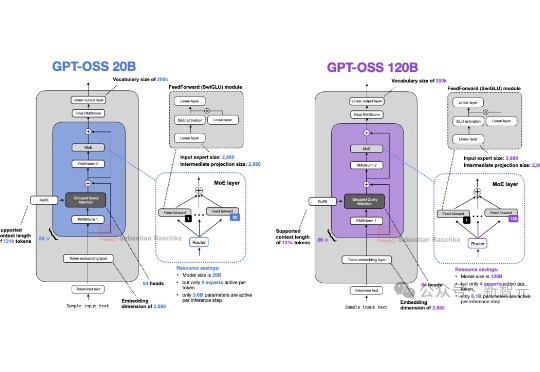
自GPT-2以来,大模型的整体架构虽然未有大的变化,但从未停止演化的脚步。借OpenAI开源gpt-oss(120B/20B),Sebastian Raschka博士将我们带回硬核拆机现场,回溯了从GPT-2到gpt-oss的大模型演进之路,并将gpt-oss与Qwen3进行了详细对比。

昨天是个热闹的日子,OpenAI 和 Anthropic 几乎在同一时间发布了自家的新款模型:前者是自 GPT-2 以来重新开源的两款模型 gpt-oss(120b 和 20b),后者是 Claude 系列最强的 Opus 4.1。
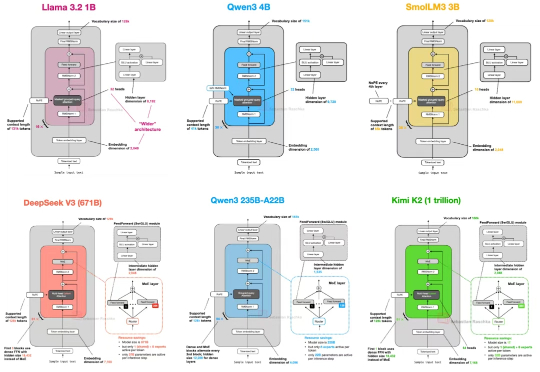
自首次提出 GPT 架构以来,转眼已经过去了七年。 如果从 2019 年的 GPT-2 出发,回顾至 2024–2025 年的 DeepSeek-V3 和 LLaMA 4,不难发现一个有趣的现象:尽管模型能力不断提升,但其整体架构在这七年中保持了高度一致。
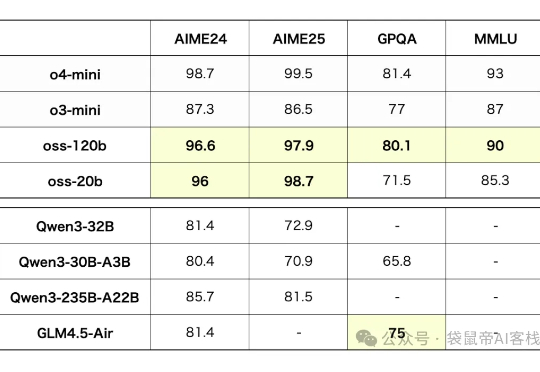
一直被称为"CloseAI"的OpenAI,终于舍得发布了他们继GPT-2之后的第一个开源模型:GPT-OSS
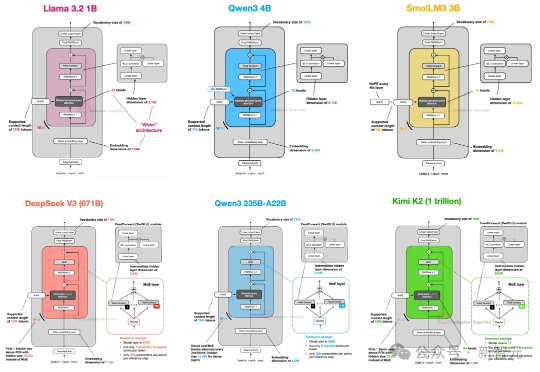
从GPT-2到DeepSeek-V3和Kimi K2,架构看似未变,却藏着哪些微妙升级?本文深入剖析2025年顶级开源模型的创新技术,揭示滑动窗口注意力、MoE和NoPE如何重塑效率与性能。
从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?

OpenAI真的要开源了!奥特曼官宣,即将开源自GPT-2以来的首款推理模型,可在消费级硬件上运行。同时,OpenAI又拿到了最高400亿单轮融资,估值直冲3000亿。

一夜之间,OpenAI更新三大动向,开源、融资、用户暴增。第一,将开源一个具备推理能力的大语言模型,包含参数权重那种。上一次这样开源还是6年前推出GPT-2。

DeepSeek彻底引爆大模型应用落地。