曝DeepSeek春节不发大招,友商疯狂偷家
曝DeepSeek春节不发大招,友商疯狂偷家就在刚刚,据《南华早报》援引知情人士最新消息,智谱 AI 计划在未来两周内,也就是春节前发布其新旗舰模型 GLM-5。与此同时,MiniMax 也预计将于春节前发布 M2.2 模型,这是在原有 M2.1 基础上进行的小幅更新,重点提升编程能力。
来自主题: AI资讯
14888 点击 2026-02-02 23:07
 搜索
搜索
就在刚刚,据《南华早报》援引知情人士最新消息,智谱 AI 计划在未来两周内,也就是春节前发布其新旗舰模型 GLM-5。与此同时,MiniMax 也预计将于春节前发布 M2.2 模型,这是在原有 M2.1 基础上进行的小幅更新,重点提升编程能力。
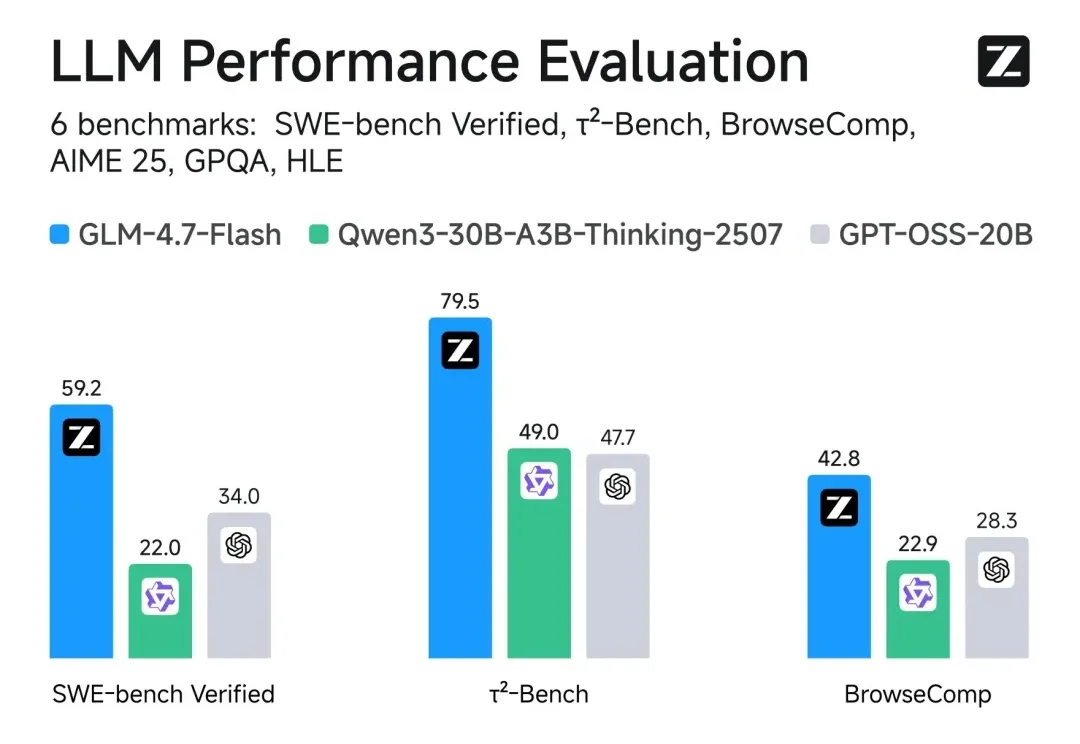
智谱AI上市后,再发新成果。
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
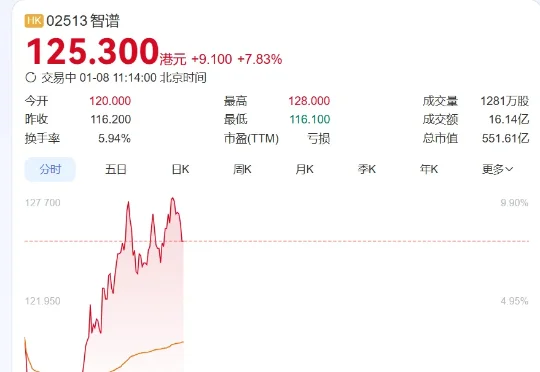
1月8日,大模型六小龙第一股,智谱上市了,市值直超551亿港元,而且一路涨幅超已逾7%。而就在上市前一天,小编注意到,智谱创立发起人兼首席科学家唐杰在微博上发布了一条充满预告意味的帖子,称:“AA(artificialanalysis)换了几个benchmark,基本是把原来刷爆的都换了,现在评估越来越难,新增加的Physical Reasoning貌似还很难。。。。”
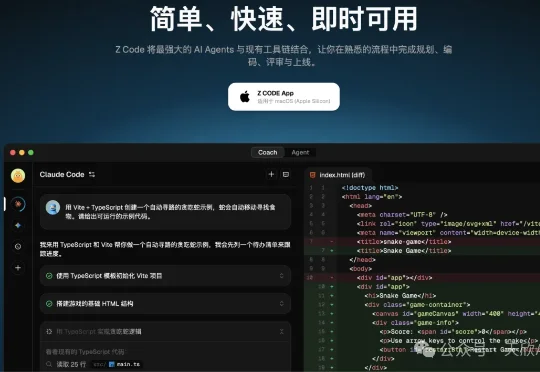
在 GLM-4.7 模型发布后不久,智谱又上线了一款全新理念的 AI 编程工具 Z Code。目前 Z Code 仍处于测试阶段,但在实际上手过程中,能感受到它与传统 AI 编程工具明显不同的设计思路。下载地址:https://zcode-ai.com/cn
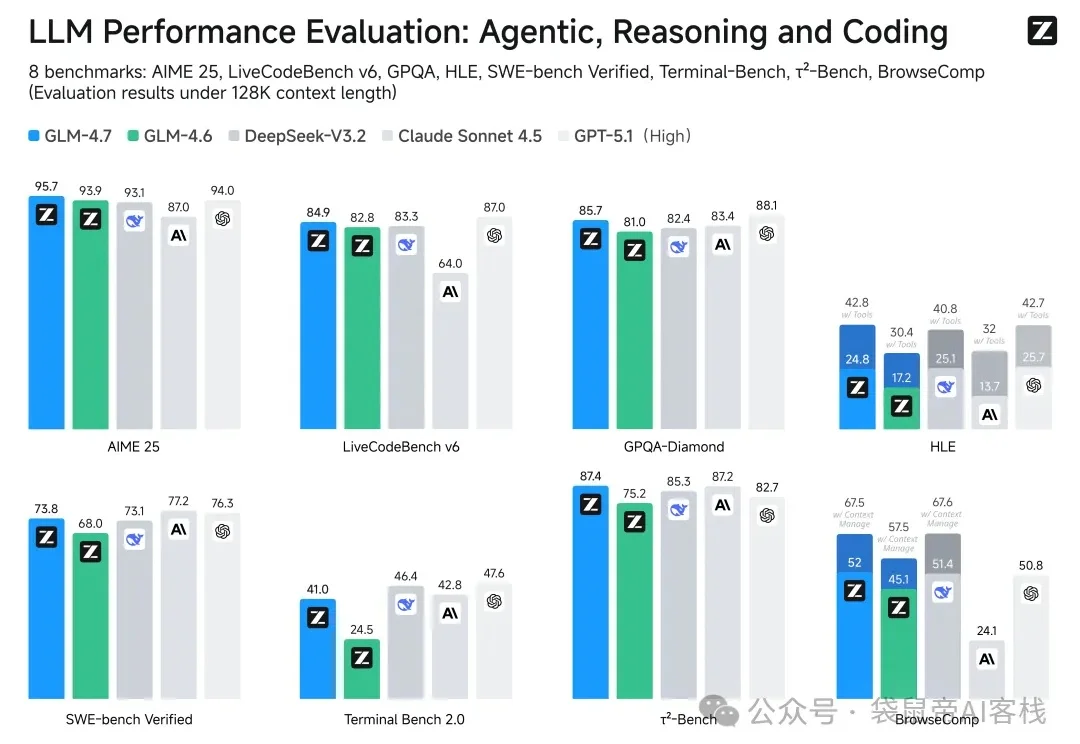
大家好,我是被智谱卷到的袋鼠帝。 昨天智谱刚把GLM-4.7放出来,群里就有老哥找我写文章了..
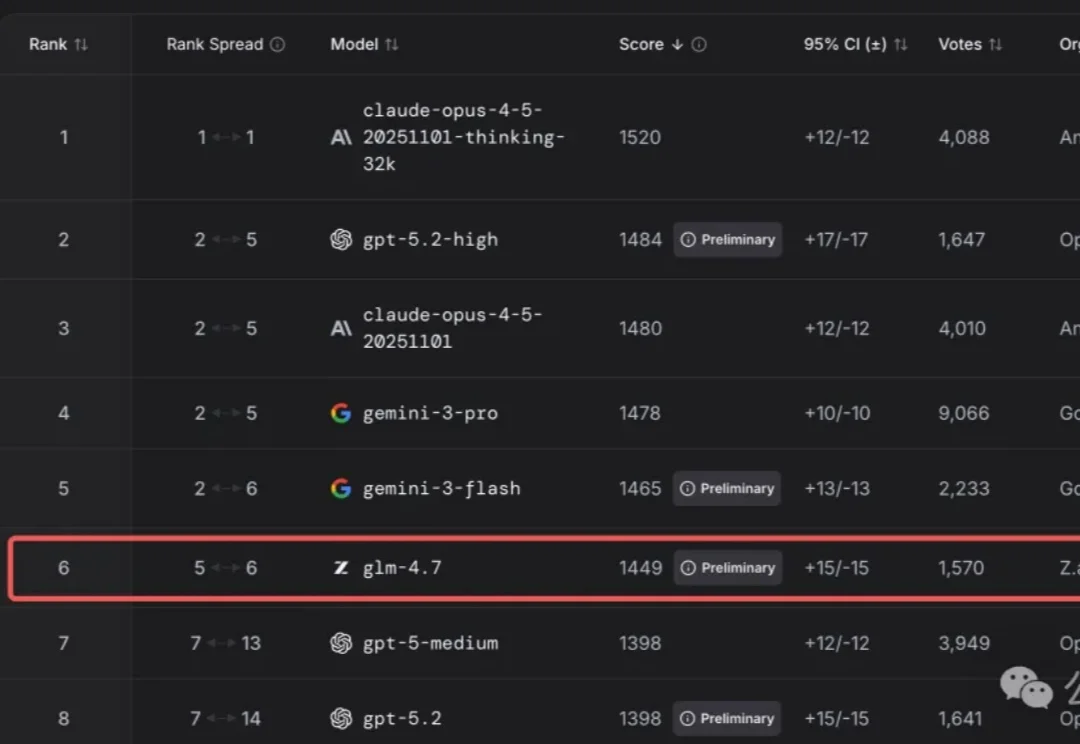
真是越到年底,越是神仙打架。

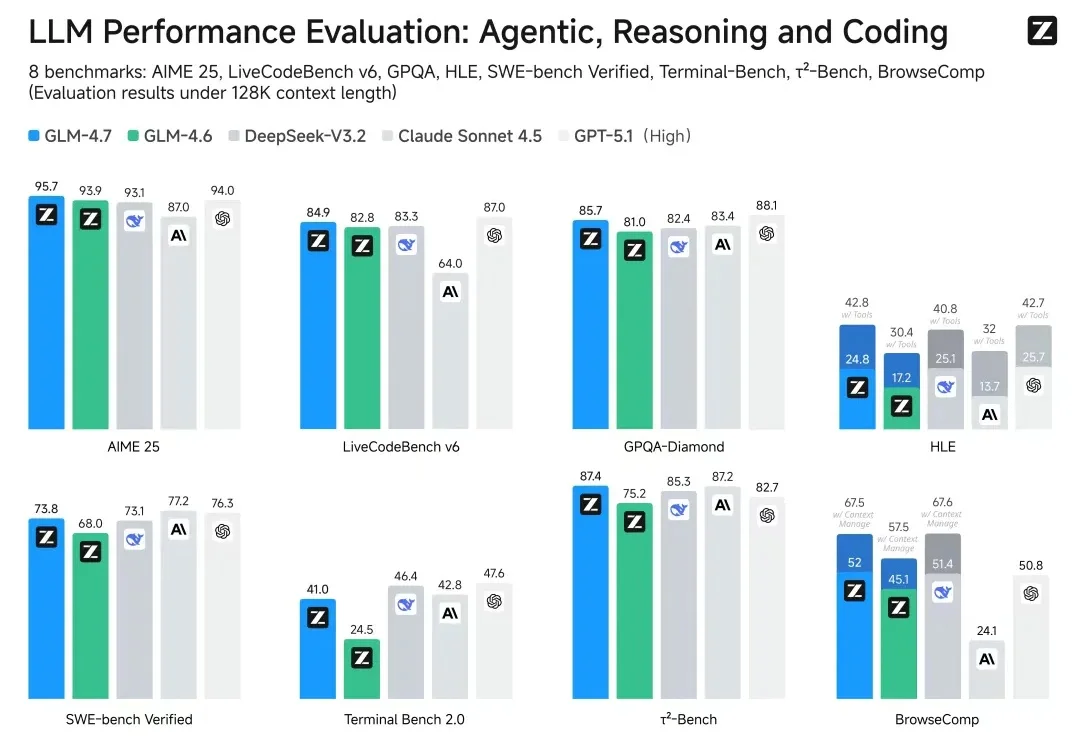
智谱作为「大模型第一股」赴港上市前夕,直接掏出了旗舰模型GLM-4.7并开源!
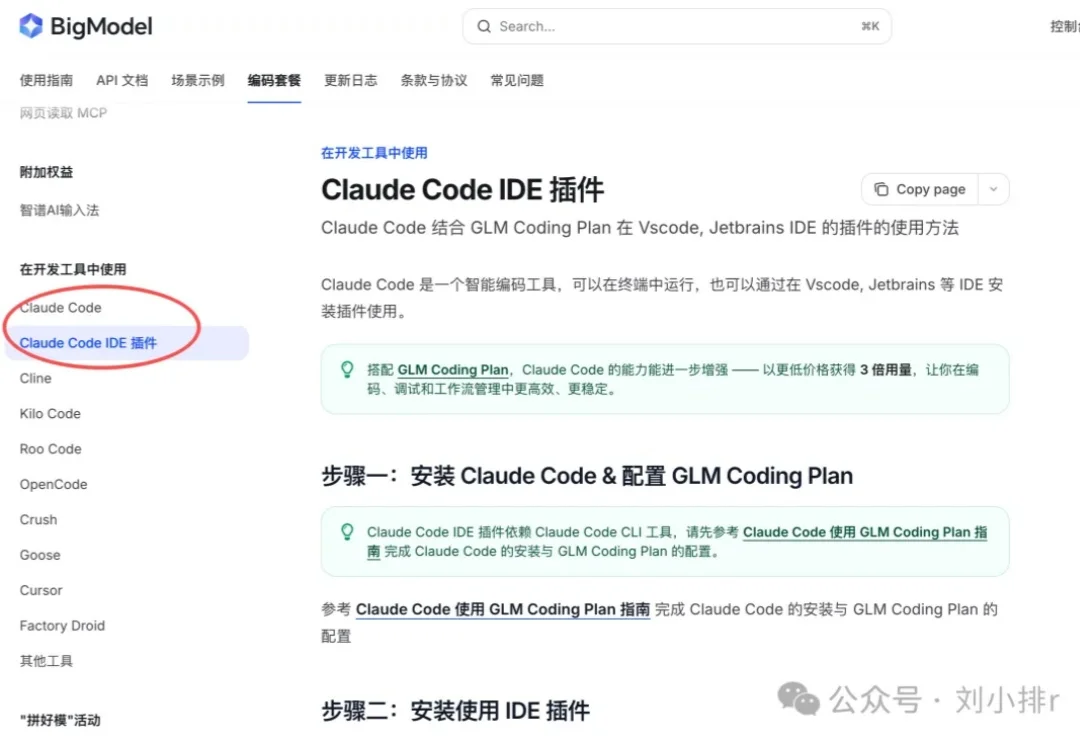
哈喽,大家好,我是刘小排。 GLM 4.7发布了,从客观数据看,编程方面进步很大。
今天,我又要来得罪人了。 甚至可以说,这篇文章发出来,可能会直接断了很多人的财路。