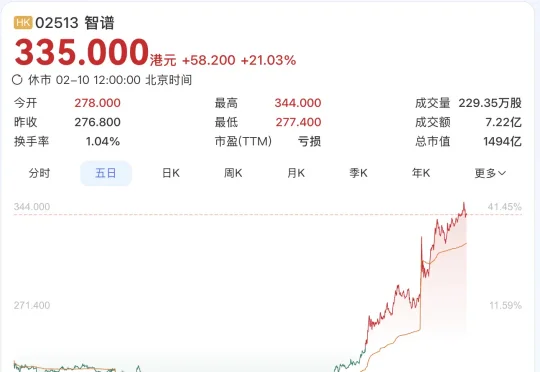
GLM-5架构曝光,智谱两日涨60%:采用DeepSeek同款稀疏注意力
GLM-5架构曝光,智谱两日涨60%:采用DeepSeek同款稀疏注意力不管Pony Alpha是不是智谱的,下一代旗舰大模型GLM-5都要来了。GLM-5采用了DeepSeek-V3/V3.2架构,包括稀疏注意力机制(DSA)和多Token预测(MTP),总参数量745B,是上一代GLM-4.7的2倍。
来自主题: AI资讯
9852 点击 2026-02-10 16:27
 搜索
搜索
不管Pony Alpha是不是智谱的,下一代旗舰大模型GLM-5都要来了。GLM-5采用了DeepSeek-V3/V3.2架构,包括稀疏注意力机制(DSA)和多Token预测(MTP),总参数量745B,是上一代GLM-4.7的2倍。
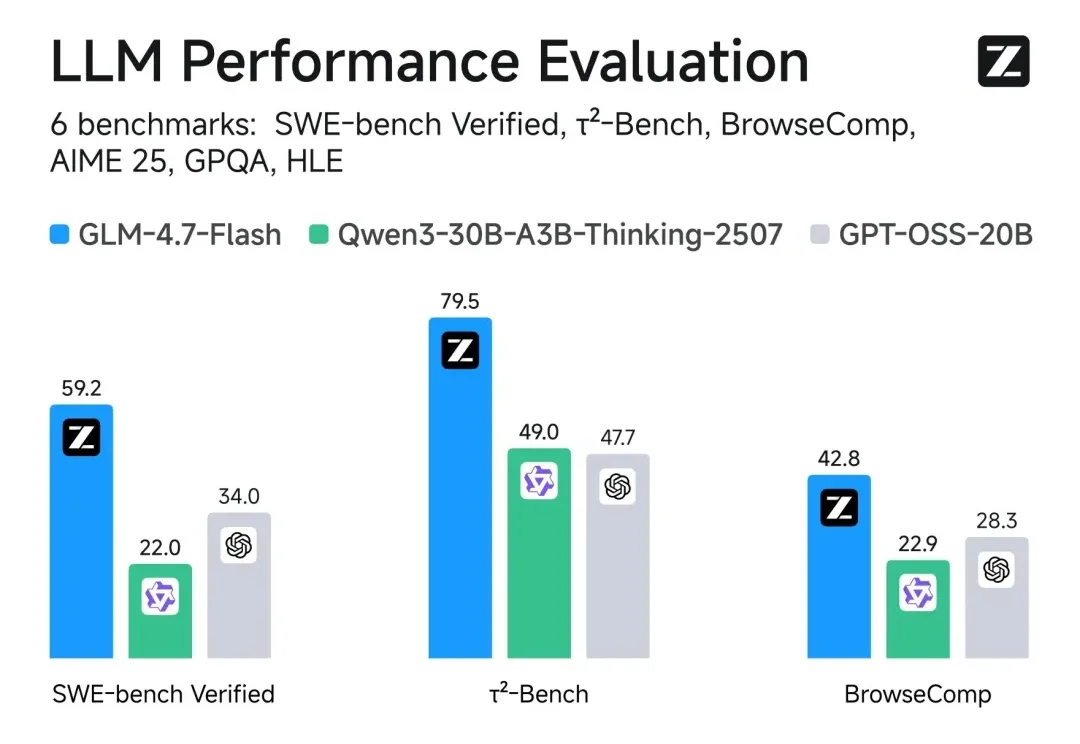
智谱AI上市后,再发新成果。
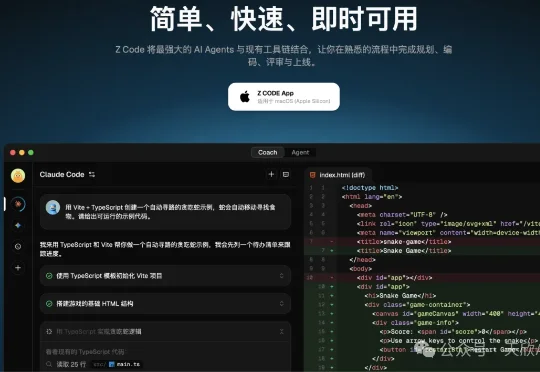
在 GLM-4.7 模型发布后不久,智谱又上线了一款全新理念的 AI 编程工具 Z Code。目前 Z Code 仍处于测试阶段,但在实际上手过程中,能感受到它与传统 AI 编程工具明显不同的设计思路。下载地址:https://zcode-ai.com/cn
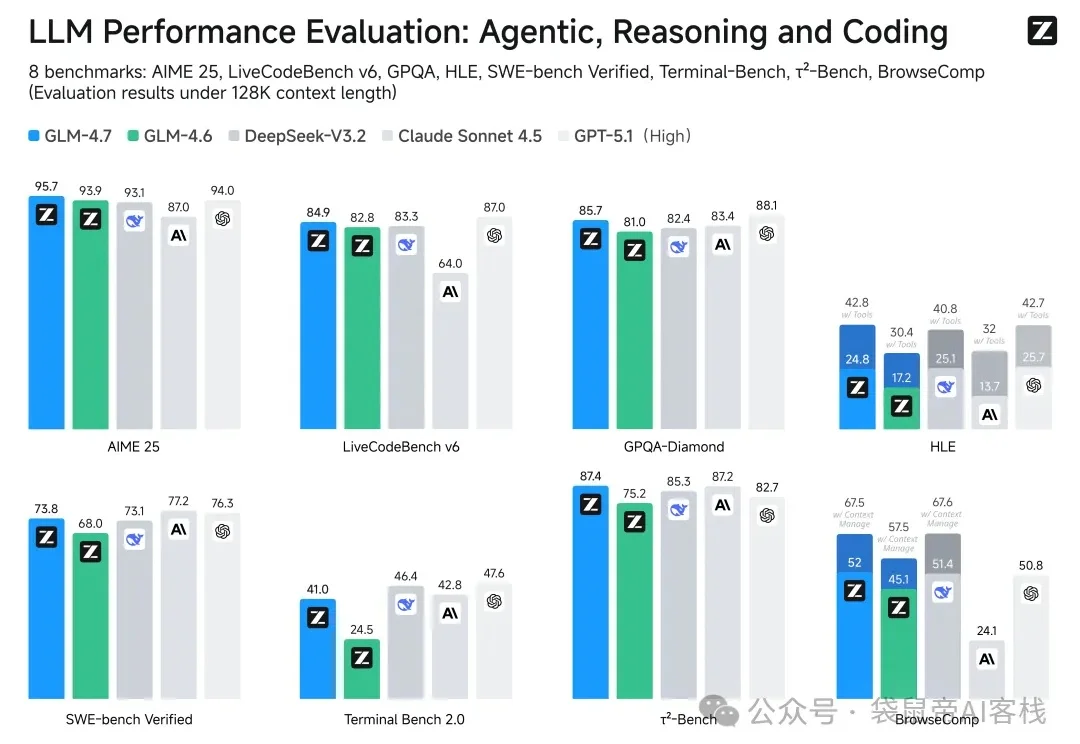
大家好,我是被智谱卷到的袋鼠帝。 昨天智谱刚把GLM-4.7放出来,群里就有老哥找我写文章了..
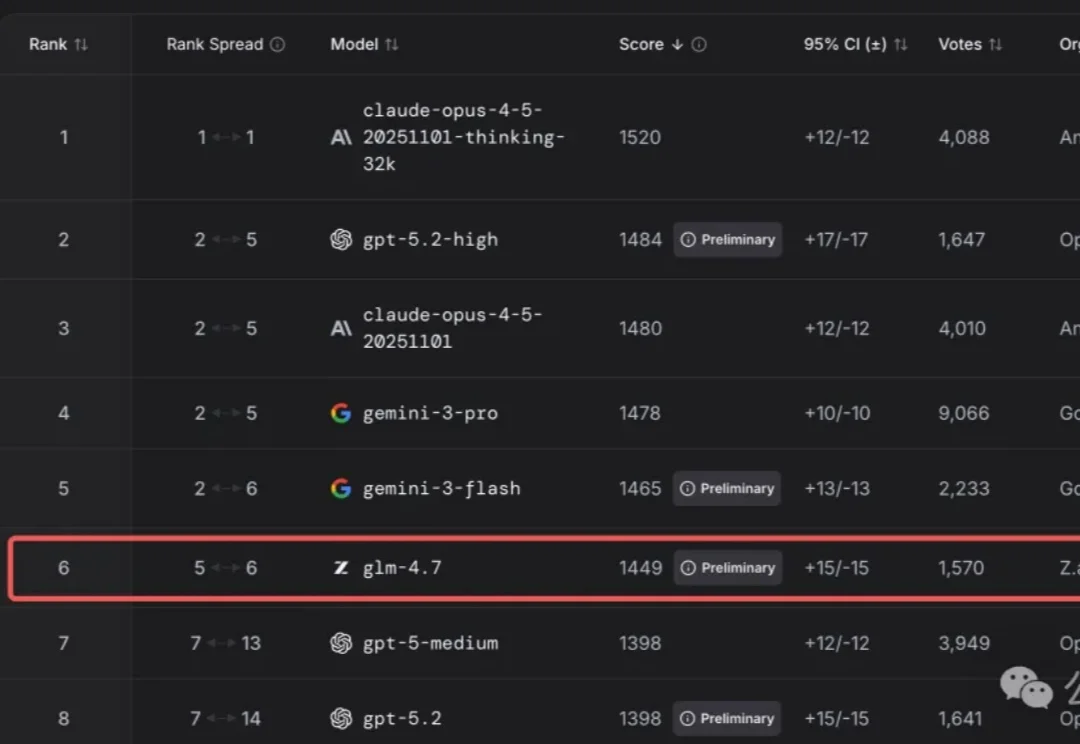
真是越到年底,越是神仙打架。

智谱作为「大模型第一股」赴港上市前夕,直接掏出了旗舰模型GLM-4.7并开源!
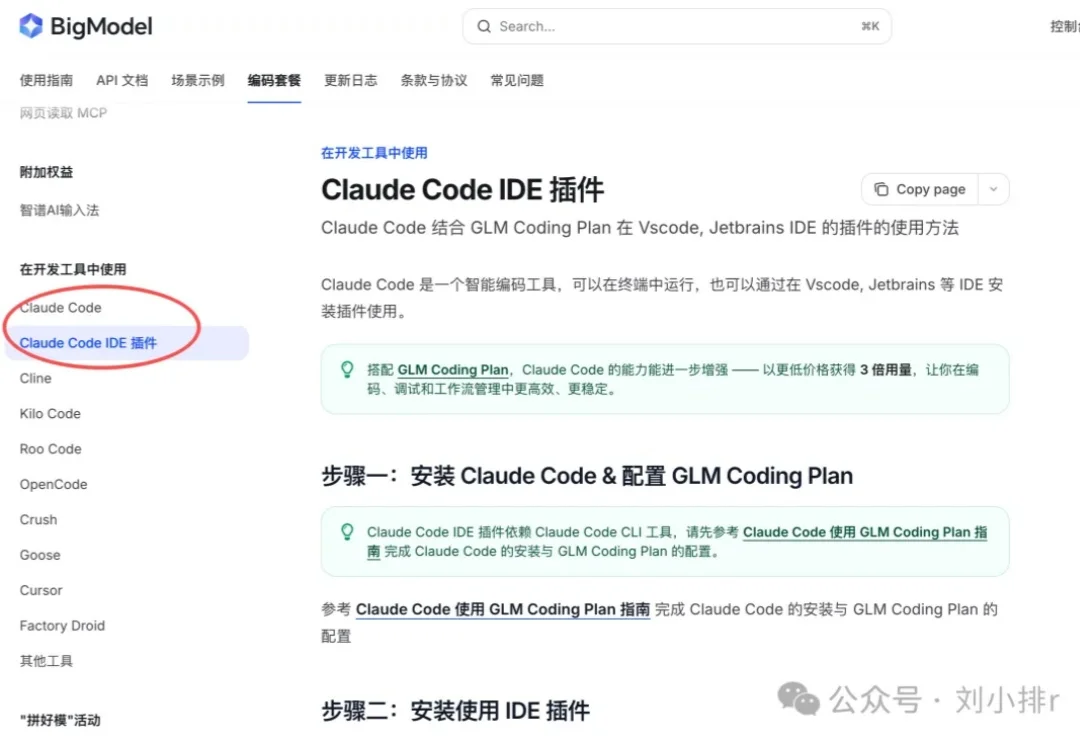
哈喽,大家好,我是刘小排。 GLM 4.7发布了,从客观数据看,编程方面进步很大。
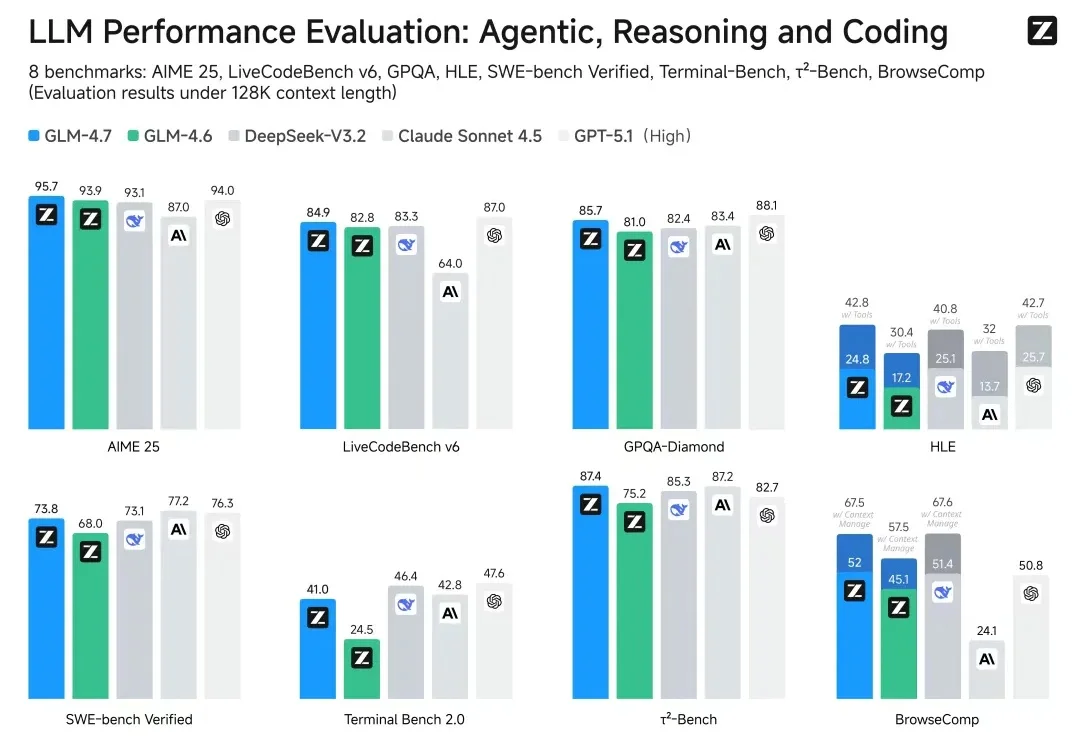
今天,我又要来得罪人了。 甚至可以说,这篇文章发出来,可能会直接断了很多人的财路。

2025倒计时,新SOTA模型涌现没有放缓迹象。一夜之间,编程SOTA模型易主,而且上线即开源,依然来自中国大模型公司——智谱AI,GLM-4.7。

拥有一台AI手机,竟能如此简单。这个AI手机,正是最近全面开源的、能让手机自己动起来的AutoGLM。这个方法要用到的工具组合是Claude Code + GLM-4.6。