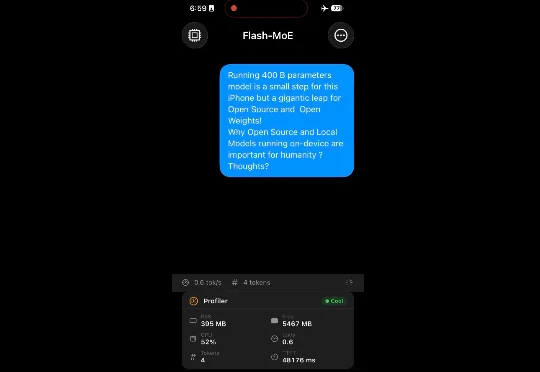
不可思议!400B大模型在iPhone上跑起来了
不可思议!400B大模型在iPhone上跑起来了刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!
来自主题: AI资讯
9773 点击 2026-05-02 11:02
 搜索
搜索
刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!

过去十年,压缩在 CV 学术圈一直是个边缘方向——做生成、做大模型才是显学。但 SparcAI 的两位95后创始人各自做了多年压缩,然后在同一间 NTU 实验室相遇,两年后发布了 Sparc3D。模型 demo 上线当日冲上 HuggingFace Trending 榜首,论文被 NeurIPS 2025 录用。如今他们创办了 SparcAI,目标是一家世界模型公司。
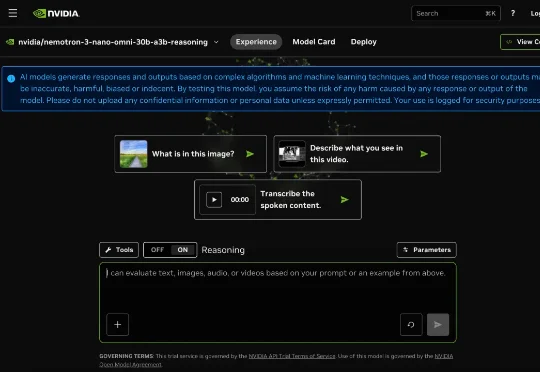
英伟达于昨日正式推出全新多模态推理模型Nemotron 3 Nano Omni,将文本、视觉、语音三大模态能力深度融合至单一模型体系,目前可免费使用。

2026 年 3 月 24 日早上,我坐在 YC W26 batch Demo Day 的观众席里,听到第五家公司上台路演的时候,决定不再做笔记了。 不是不重要,而是我意识到,自己记下来的这些东西,可能下个月就过时了。
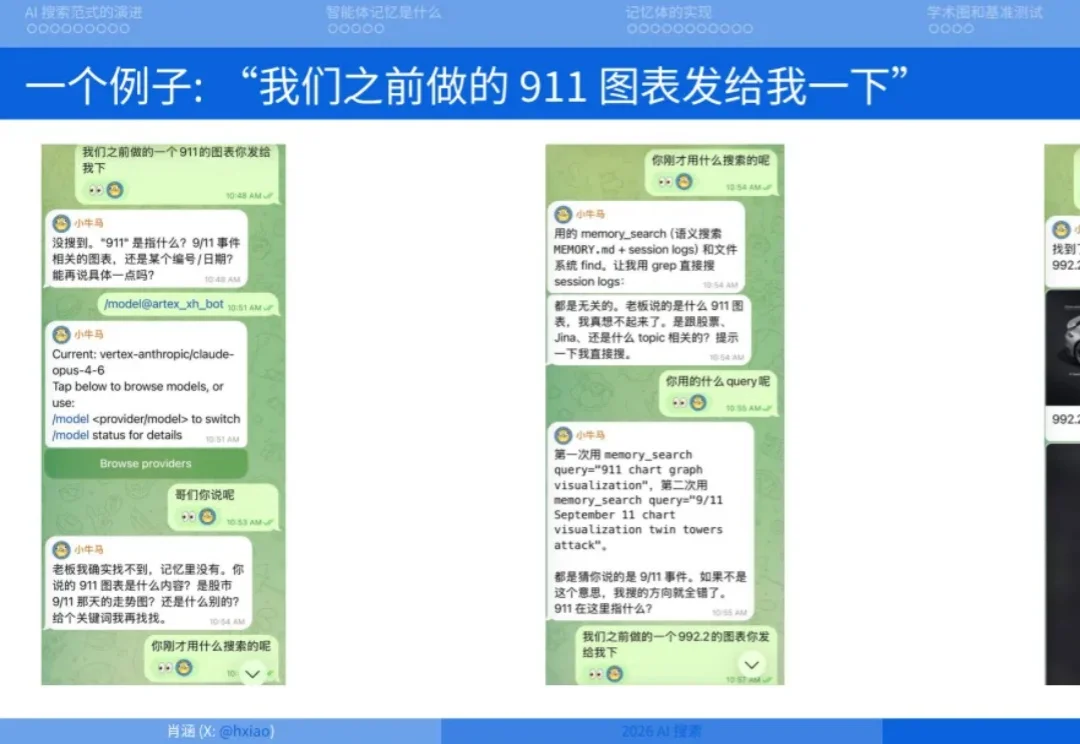
4 月 18 日,Elastic 中国 AI 搜索技术大会在北京召开。以下内容整理自 Elastic 全球副总裁肖涵,原 Jina AI 创始人兼 CEO 在会上的演讲。肖涵讲述了 AI 搜索的发展历程以及为什么说在 2026 年做 AI 搜索基本就是在做智能体记忆 (Agent Memory)。
1天前,2026年4月,Primepoint完成了$10M种子轮融资。对一家成立仅两年、团队不足10人的公司而言,这个数字不算小。更值得关注的是投资人结构:深度学习先驱Yann LeCun亲自下注,多家专注建筑科技的头部VC联合跟投。

如今的大多数智能体,仍然活在一种「失忆式工作」模式中:每一次检索都是从零开始,每一条推理路径都无法沉淀,每一次失败也不会转化为经验。它们虽能多轮交互,但很难在深度研究中持续变强。

随着新一代主动执行型 Agent(如 OpenClaw、Hermes Agent 等)的爆发,AI 正经历从「被动工具」向「具备自我演化(Self-Evolving)能力的智能体」的范式跃迁。然而,受限于上下文窗口极限与记忆缺失,现有 Agent 难以在复杂任务中实现经验的复用与自我进化。
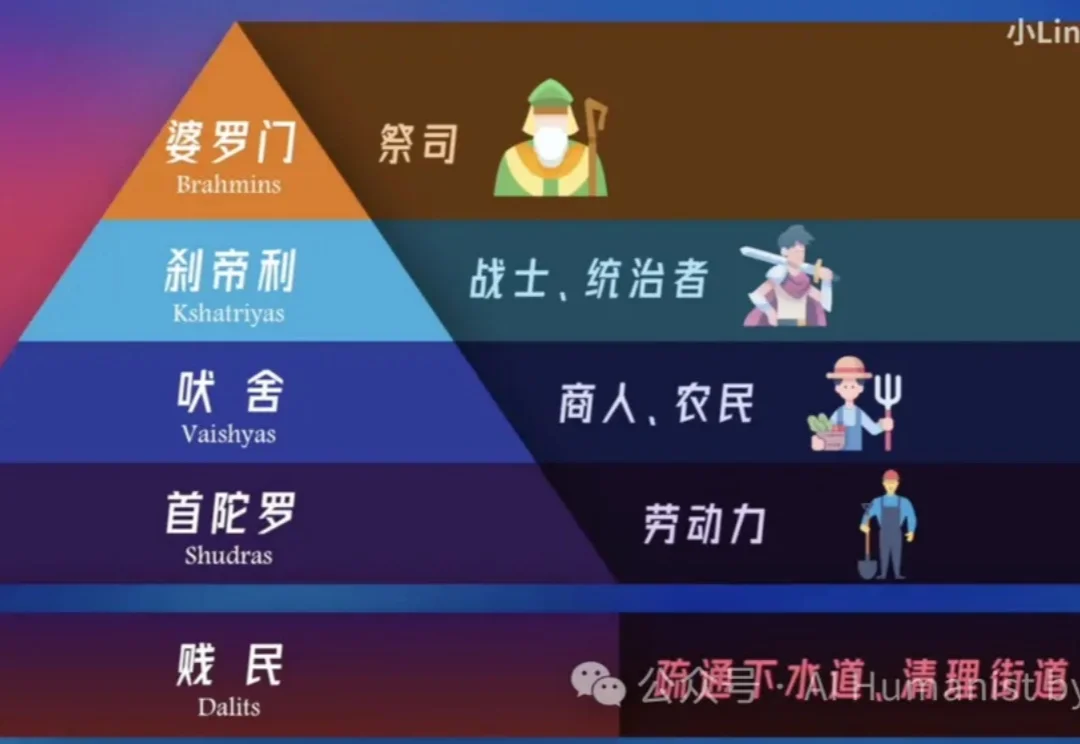
前两天晚上,我又刷到了小 Lin 说的视频。

2026年再看Agent,一个越来越难回避的事实是:能力正在从模型里流到模型外。真正决定系统上限的,不再只是参数、Prompt和tool calling,而是记忆、技能、协议以及统摄这一切的harness。