
实测小米最快1T大模型:吞吐量每秒1000+ Tokens,Vibe Coding七秒交付
实测小米最快1T大模型:吞吐量每秒1000+ Tokens,Vibe Coding七秒交付全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。
来自主题: AI产品测评
5636 点击 2026-06-11 09:58
 搜索
搜索
全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。
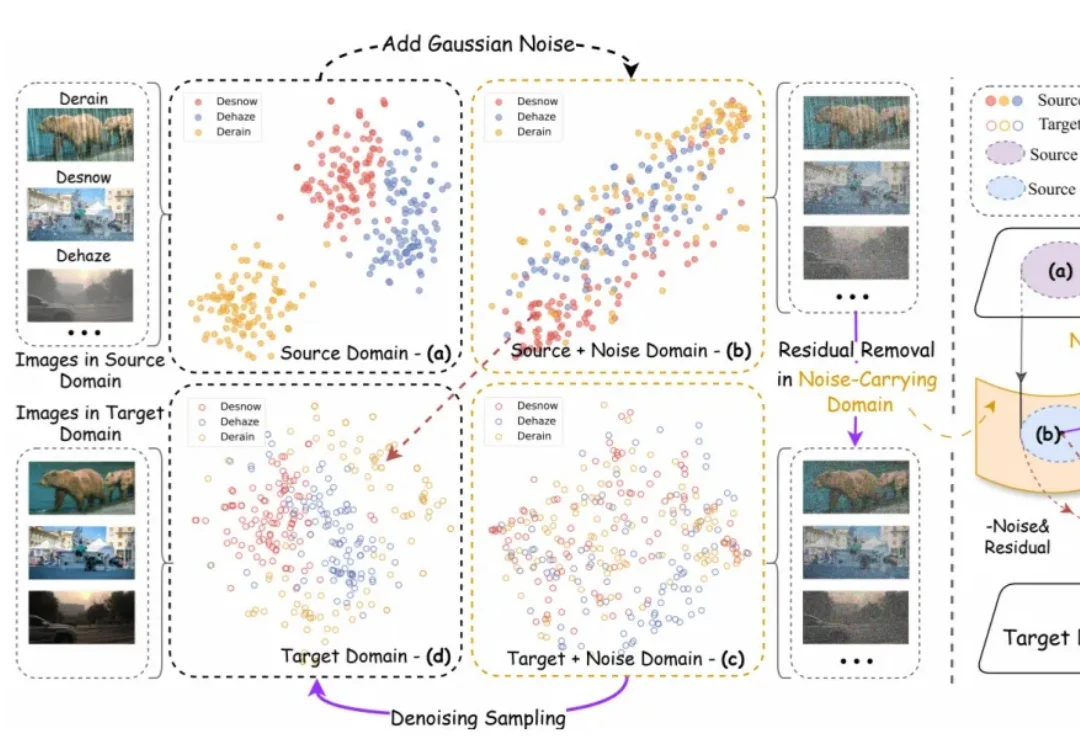
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。
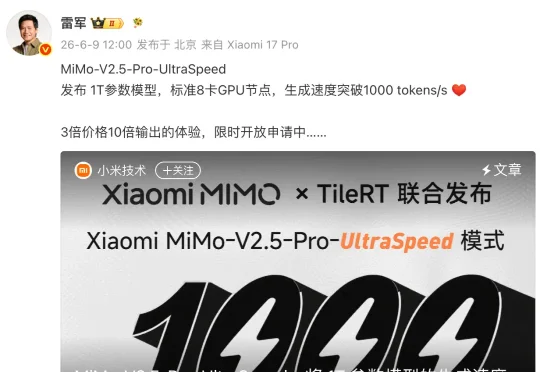
今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。
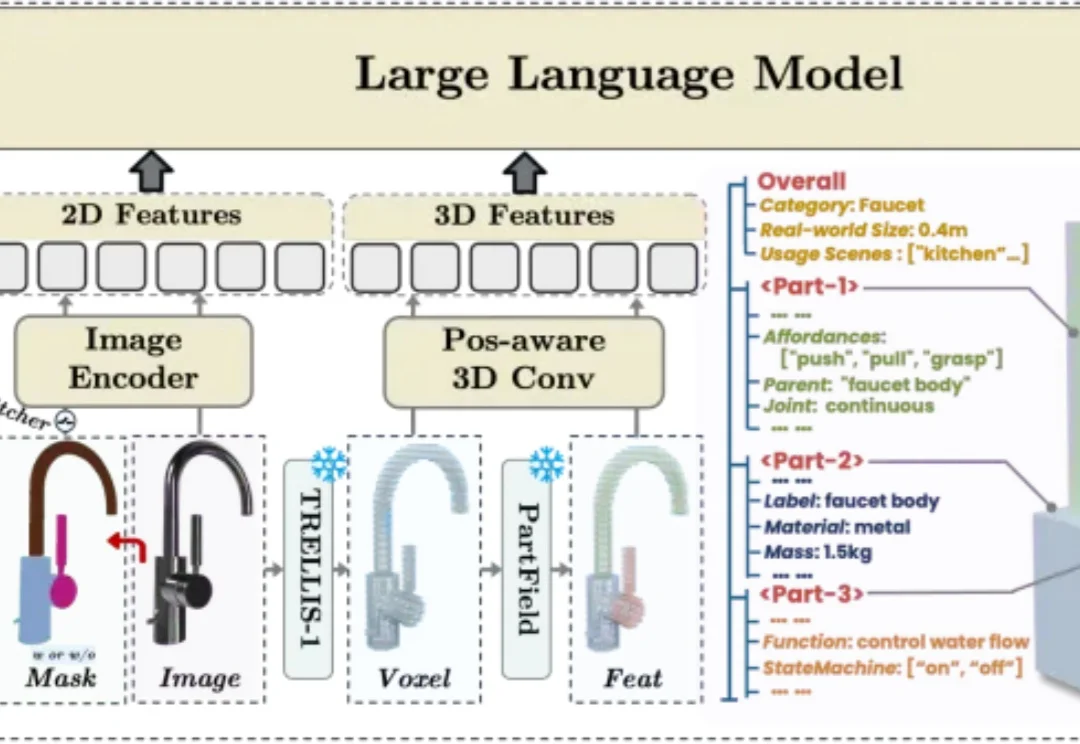
在交互式虚拟世界和具身智能快速发展的今天,高质量 3D 资产已经不再只是 “看起来像” 就足够。一个柜门不仅要有柜门的外观,还需要知道绕哪条轴旋转;一个按钮不仅要有按钮的形状,还需要具备 “按下 / 弹起” 的状态;一个抽屉不仅要有完整几何,还需要拥有滑动方向、运动范围、材质和质量等物理属性。该研究已被 ICML 2026 接收。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。
CVPR 2026全部奖项揭晓!最佳学生论文荣誉提名颁给了ChordEdit,一作和通讯都是广东工业大学本科在读生。他们用一块7年半前的老Titan,跑完了全部实验。

我在 2025 年年度总结的文章《Attention is all you need》里,提到在关注 AI 时代的投资机会,看了很多硅谷的播客和视频,一直想来硅谷看看,但自己认识的这边的人不多,恰好看到Linkloud 组织“创业加速营”,安排了不少硅谷当地的华人创业者、大厂从业人员的交流,就报名了,同去的其他人,还有想要 AI 转型或者就在 AI 领域创业的创始人或者中高管等。
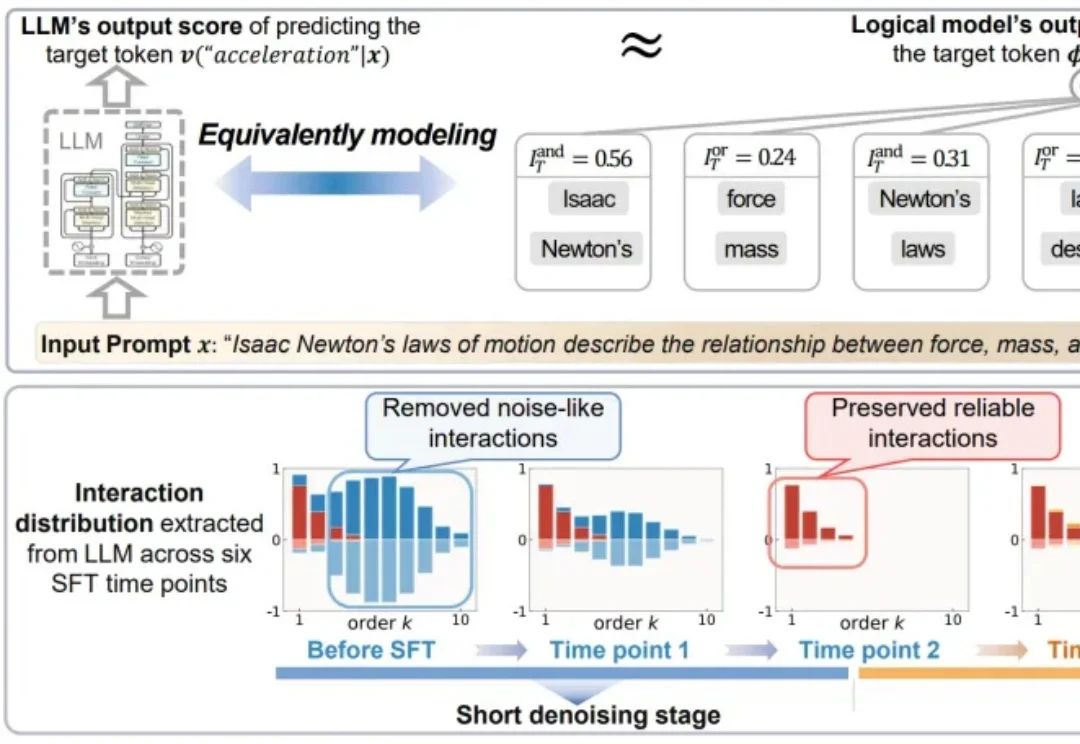
长期以来,监督微调(Supervised Fine-Tuning,SFT)一直是深度神经网络中最常用的模型适配手段。在中小规模的传统神经网络中,SFT 通常能够稳定提升下游任务表现。

如果模型能力断层领先,那么买单的人自然会出现。

独家获悉,字节跳动多模态负责人周畅管理范围再次扩大,原由李航负责的 Seed Robotics 团队已向周畅汇报月余,李航现以顾问身份负责学术合作方向。字节也正在招聘具身智能技术负责人,负责机器人业务整体规划,职级定位为 L8,对标阿里 P10-P11,将向周畅汇报。该岗位候选人主要来自头部具身智能创业公司技术负责人。