
谷歌突然开源Agent OKF新标准!Karpathy力推的AI知识库终于有了通用格式了
谷歌突然开源Agent OKF新标准!Karpathy力推的AI知识库终于有了通用格式了谷歌今天发布了一个叫 Open Knowledge Format(OKF)的开放规范。
来自主题: AI技术研报
8773 点击 2026-06-18 11:27
 搜索
搜索
谷歌今天发布了一个叫 Open Knowledge Format(OKF)的开放规范。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

昨晚,字节新模型Seedance 2.0 Mini深夜来袭,该模型主打性价比,侧重于提供更低的价格以及更快的生成速度。Seedance 2.0 Mini虽然定价更低,但保留了核心能力参考生成,用户可以通过融合提示词与最多12个多种模态的参考素材(包括6张图片、3段音频、3段视频)来锁定人物一致性、精细化控制运动轨迹、卡准剧情节奏。
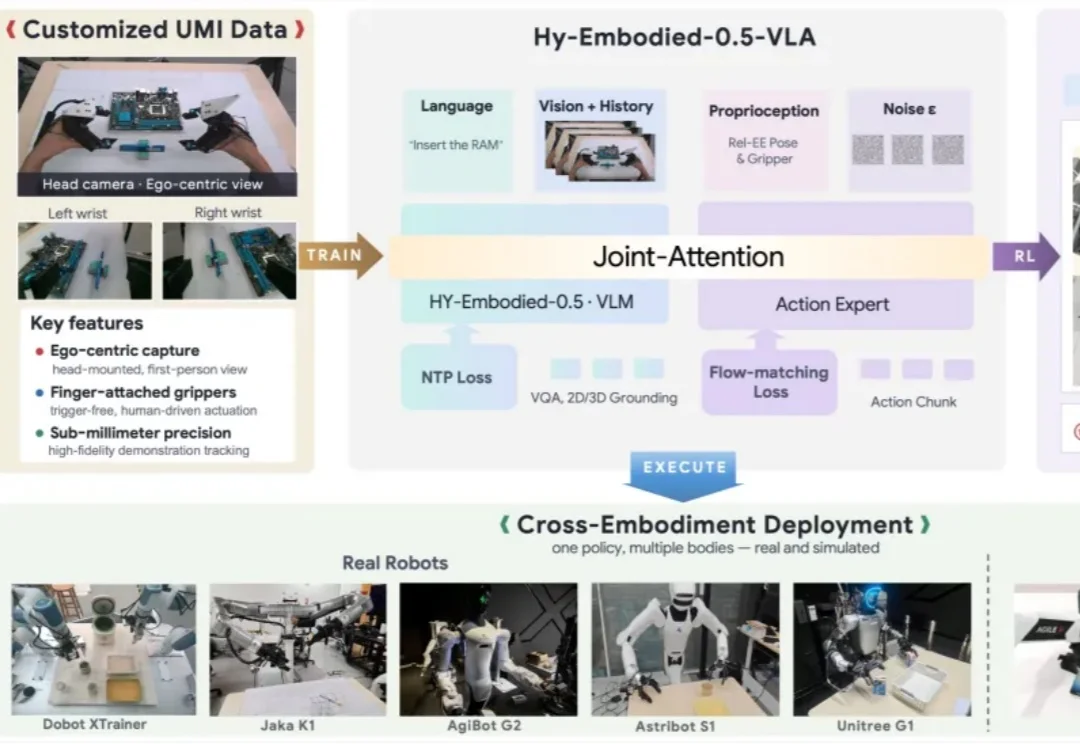
6 月 15 日,腾讯 Robotics X、福田实验室与混元团队联合发布面向真实世界机器人操作任务的端到端具身智能模型 Hy-Embodied-0.5-VLA(简称 HyVLA-0.5)。

就在昨天,外媒The Information爆料——前阿里巴巴千问大模型负责人林俊旸创办的AI实验室已经完成首轮融资,融资总额达数亿美元,投后估值达20亿美元!其中,红杉中国、高榕资本各投1亿美元领投,互联网巨头腾讯狂掷2000万美元跟投。
你为什么选了做视觉有关的方向呢?跟你对市场、对成都的观察有关吗?我们现在用的很多传统的 APP,包括很多操作系统,我觉得未来会被替代掉的。因为很多是很“反人类”的设计。这些东西的本质是“系统状态的流转”,没有一个正常人喜欢用这些系统。而这部分,数据的流转,是 Agent 能替我们做的。最终一定会剩下一些简洁的信息要呈现给人——我们做的,反而应该是这个部分。

硬氪获悉,具身智能世界模型公司「千诀科技」日前完成数亿元A轮融资,本轮由京铭资本领投,山东新动能、山东财金资本、元禾厚望、芯能创投、南创投、英诺天使基金、尚势资本、仁爱集团、玄素投资等机构共同投资,投资方阵容汇集了国家队、产业方、市场化基金及家族办公室。Maple Pledge枫承资本长期出任私募股权融资顾问。
《读佳》获知,腾讯“TDream”带着“创造可玩的世界”的定位低调开启内测。“说句肺腑之言,这个产品,我觉得打破了我对腾讯的认知。”一位用户看了TDream生成《山月》视频作品后,十分感慨。他觉得,这个产品可以和字节的Seedance2.0、HappyHorse掰掰手腕。

视频生成,早已不止于视觉。

最近几个月,海外主流社交平台X、YouTube、Instagram、LinkedIn、Facebook等的头部内容创作者,开始高频地提及同一个名字——AhaCreator 3.0。从科技博主、消费电子达人,到跨境电商品牌主理人,再到拥有百万粉丝的内容创作者,越来越多人在自己的内容中分享使用体验。