速递|Deepseek引入峰谷定价,变相涨价
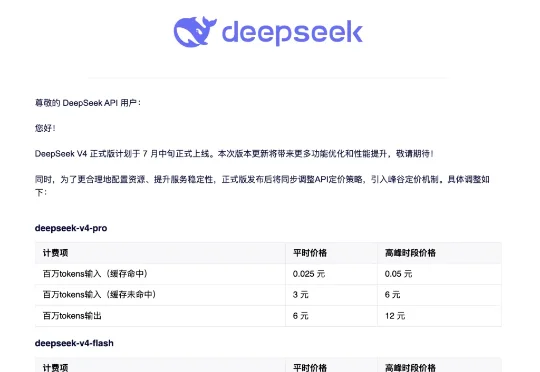
速递|Deepseek引入峰谷定价,变相涨价记者获悉,DeepSeek宣布价格调整,引入峰谷计费机制:以DeepSeek-v4-pro为例,其输入价格(缓存命中)平时为0.025元/百万tokens,高峰时期为0.05元/百万tokens;输入价格(缓存未命中)平时为3元/百万tokens,高峰时期为6元/百万tokens;输出价格平时为6元/百万tokens,高峰时期为12元/百万tokens。
来自主题: AI资讯
8852 点击 2026-06-30 10:33