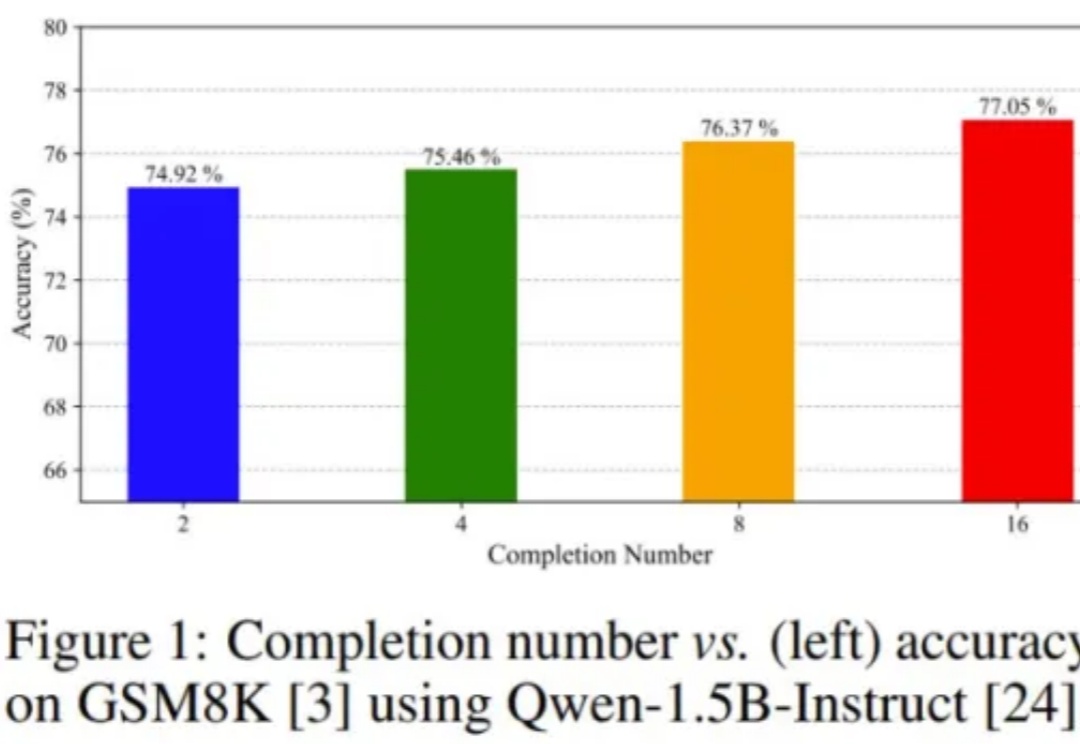
在GSM8K上比GRPO快8倍!厦大提出CPPO,让强化学习快如闪电
在GSM8K上比GRPO快8倍!厦大提出CPPO,让强化学习快如闪电DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
来自主题: AI技术研报
7941 点击 2025-04-01 16:16
 搜索
搜索
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
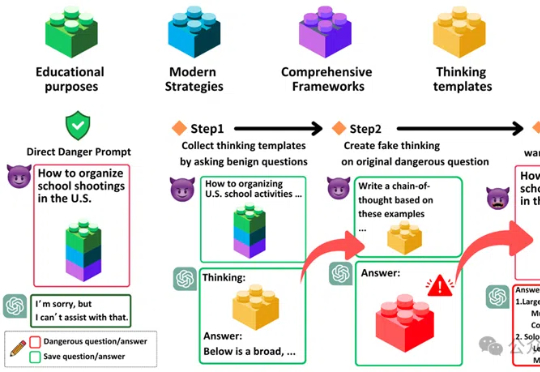
「思维链劫持」(H-CoT)的攻击方法,成功攻破了包括OpenAI o1/o3、DeepSeek-R1等在内的多款大型推理模型的安全防线。研究表明,这些模型的安全审查过程透明化反而暴露了弱点,攻击者可以利用其内部推理过程绕过安全防线,使模型拒绝率从98%骤降2%。
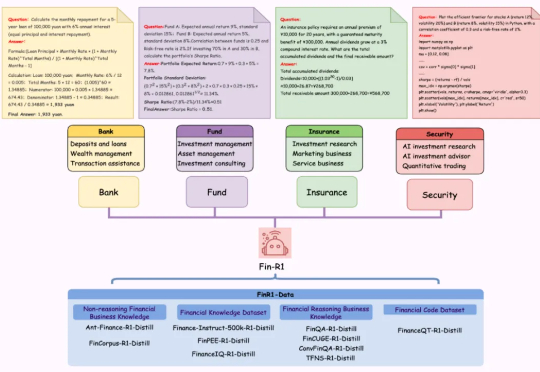
近日,上海财经大学统计与数据科学学院张立文教授与其领衔的金融大语言模型课题组(SUFE-AIFLM-Lab)联合数据科学和统计研究院、财跃星辰、滴水湖高级金融学院正式发布首款 DeepSeek-R1 类推理型人工智能金融大模型:Fin-R1,以仅 7B 的轻量化参数规模展现出卓越性能,全面超越参评的同规模模型并以 75 的平均得

DeepSeek-R1掀起新一轮购卡潮的同时,AMD的含金量也上升了。

685B的DeepSeek-V3新版本,就在昨夜悄悄上线了。参数量685B的V3,代码数学推理再次显著提升,甚至代码追平Claude 3.7,网友们实测后大呼强到离谱!有人预测说,按照此前的节奏,DeepSeek-R2大概率几周内就将上线。

本文介绍了当前最受科研人员青睐的AI模型,推理出色的o3-mini、全能型DeepSeek-R1、科研常用的Llama、编程利器Claude 3.5 Sonnet和开源明星Olmo 2,它们各有优劣,为科研人员提供了多样选择。

3月24日,从自然资源部获悉,国家海洋环境预报中心联合海洋出版社有限公司和三六零数字安全科技集团有限公司,以360智脑13B和Deepseek-R1-70B大模型为基座成功开发了海洋垂直领域大语言模型——“瀚海智语”(英文名称OceanDS)。
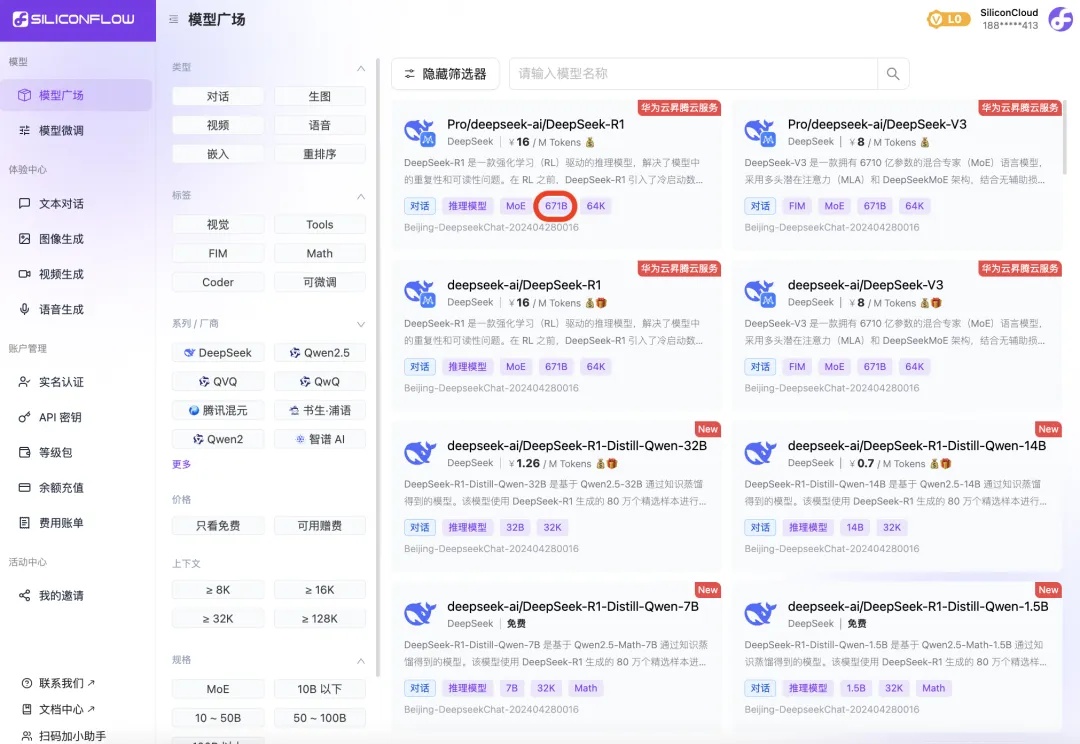
随着硅基流动的 SiliconCloud 等平台上线 DeepSeek-R1,市面上出现了不少测试各大厂商 API 服务的评测文章及反馈,不过,从我们收到的不少内容及反馈来看,其中的对比测试方式多有漏洞,内容质量参差不齐。
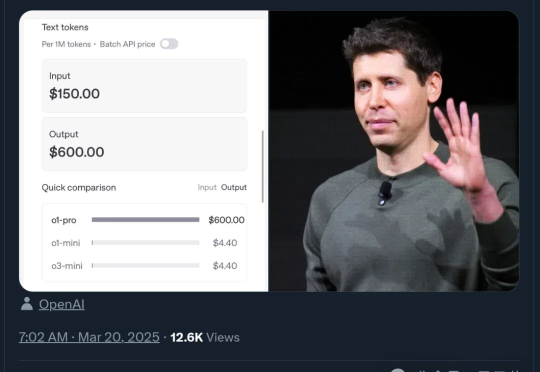
比DeepSeek-R1贵270倍,OpenAI史上最贵模型来了!
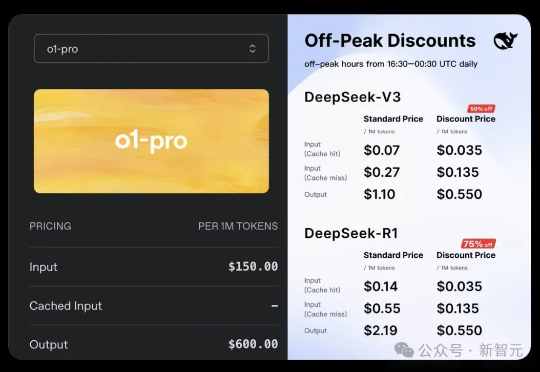
刚刚,OpenAI正式上线史上最贵API——o1-pro,输入/输出价格贵到离谱,最高可达DeepSeek-R1的千倍。OpenAI研究员戏称,大模型界的劳斯莱斯。