
超越英伟达Describe Anything!中科院 & 字节联合提出「GAR」,为DeepSeek-OCR添砖加瓦
超越英伟达Describe Anything!中科院 & 字节联合提出「GAR」,为DeepSeek-OCR添砖加瓦近期,DeepSeek-OCR提出了“Vision as Context Compression”的新思路,然而它主要研究的是通过模型的OCR能力,用图片压缩文档。
来自主题: AI技术研报
9647 点击 2025-10-28 14:28
 搜索
搜索
近期,DeepSeek-OCR提出了“Vision as Context Compression”的新思路,然而它主要研究的是通过模型的OCR能力,用图片压缩文档。

整个Hugging Face的趋势版里,前4有3个OCR,甚至Qwen3-VL-8B也能干OCR的活,说一句全员OCR真的不过分。然后在我上一篇讲DeepSeek-OCR文章的评论区里,有很多朋友都在把DeepSeek-OCR跟PaddleOCR-VL做对比,也有很多人都在问,能不能再解读一下百度那个OCR模型(也就是PaddleOCR-VL)。
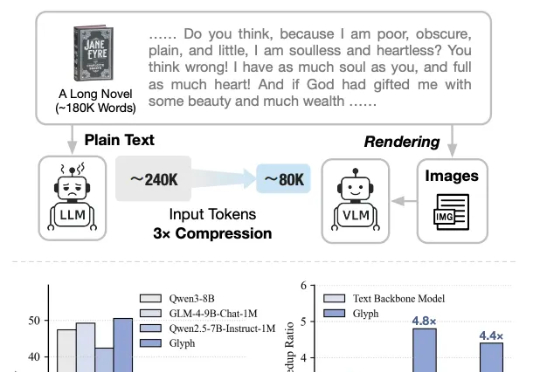
太卷了,DeepSeek-OCR刚发布不到一天,智谱就开源了自家的视觉Token方案——Glyph。既然是同台对垒,那自然得请这两天疯狂点赞DeepSeek的卡帕西来鉴赏一下:

DeepSeek最新开源的模型,已经被硅谷夸疯了!

AI新突破!DeepSeek-OCR以像素处理文本,压缩率小于1/10,基准测试领跑。开源一夜4.4k星,Karpathy技痒难耐,展望视觉输入的通用性。

刚刚,DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。 该模型最大的突破在于极高的压缩效率: 20 个节点每天可处理 3300 万页数据,硬件要求仅为 A100-40G。