第一个吃到DeepSeek红利的AI图像产品出现了?
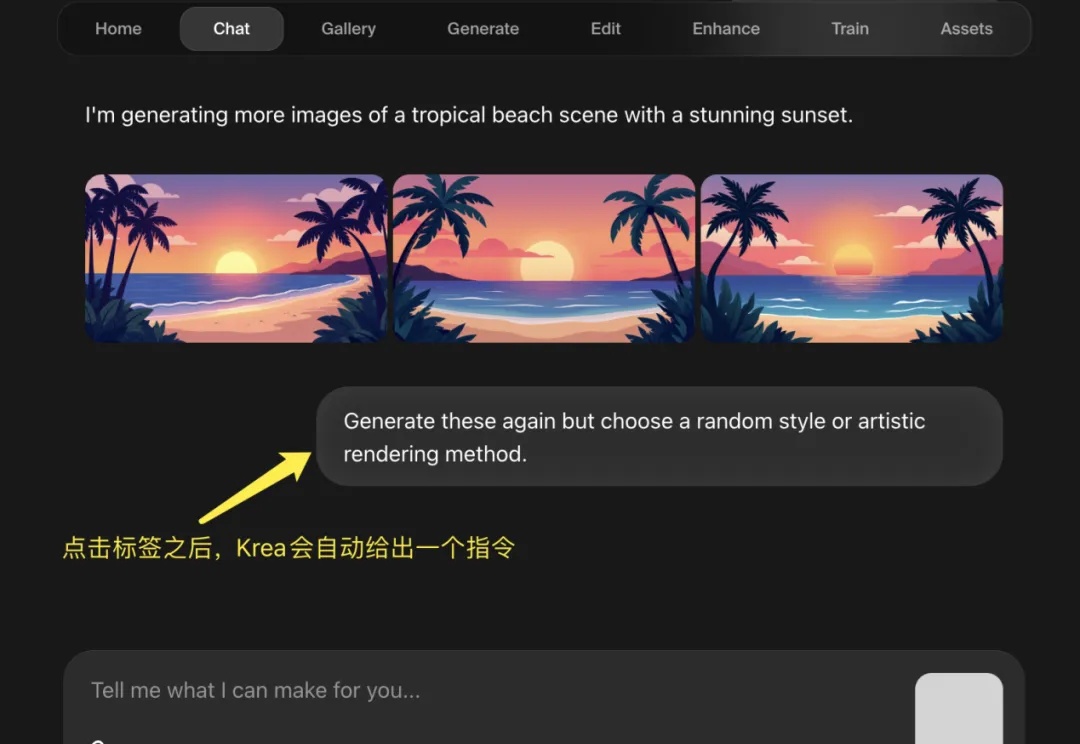
第一个吃到DeepSeek红利的AI图像产品出现了?在 R1 推理模型大火之后,全民接力集成 DeepSeek,有硅基流动这样的大模型云服务平台、有腾讯元宝这样的 Chatbot,甚至微信这样的顶流。但是,AI 图片类产品却鲜少有接入 DeepSeek R1 的新闻,而从 DeepSeek-R1 发布到 Krea 宣布上线新功能仅仅 10 天,这个反应应该是图像产品中最快的。
来自主题: AI资讯
5301 点击 2025-03-05 10:16