360智脑开源Light-R1!1000美元数学上首次从零超越DeepSeek-R1-Distill
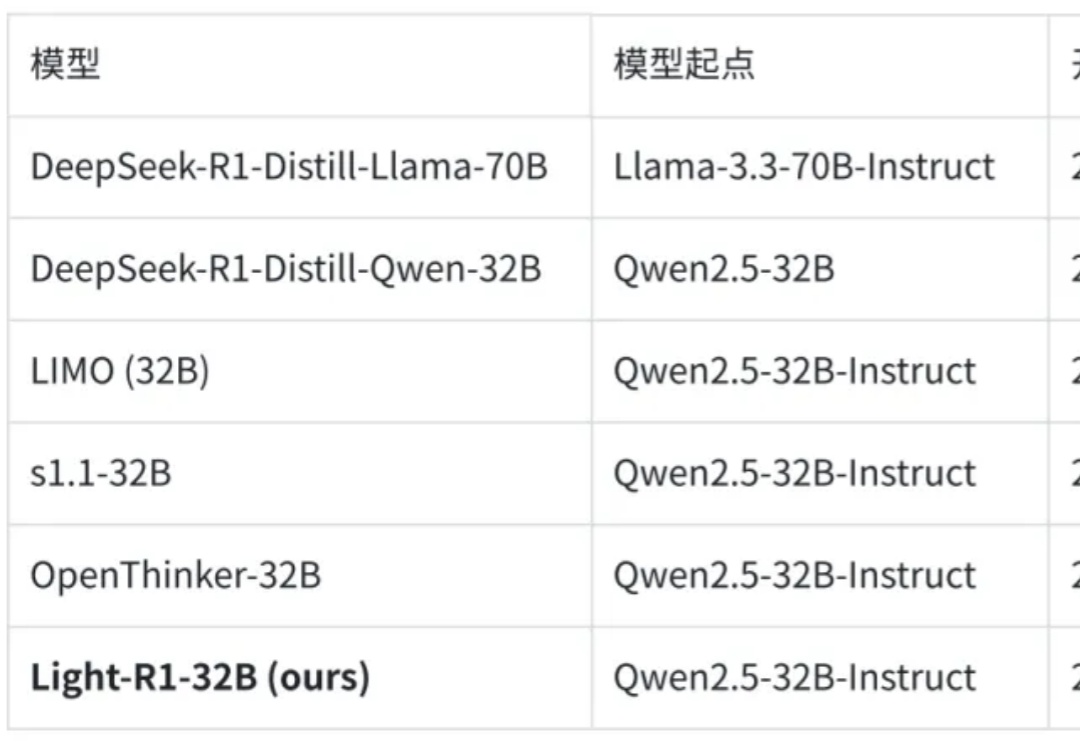
360智脑开源Light-R1!1000美元数学上首次从零超越DeepSeek-R1-Distill2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B
来自主题: AI技术研报
7191 点击 2025-03-06 11:13