
DeepSeek大招曝光?梁文峰督战超级智能体:能自主学习,或年底发布
DeepSeek大招曝光?梁文峰督战超级智能体:能自主学习,或年底发布DeepSeek再次出招,直接对标OpenAI!据彭博社最新独家爆料,DeepSeek正开发AI智能体:打造无需复杂指令、可自主学习与执行的下一代AI系统,年底重磅发布!
来自主题: AI资讯
11198 点击 2025-09-04 22:06
 搜索
搜索
DeepSeek再次出招,直接对标OpenAI!据彭博社最新独家爆料,DeepSeek正开发AI智能体:打造无需复杂指令、可自主学习与执行的下一代AI系统,年底重磅发布!

用过才知道,「快」不是万能药。
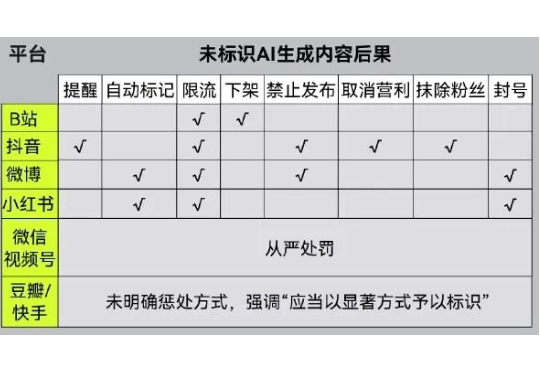
被AI糟蹋的互联网,靠AI标识重回清净? 过去几年,AI生成内容大量涌入我们的生活,但AI往往“隐身”幕后,这种“看不见的存在”自9月1日起就要被终结了。
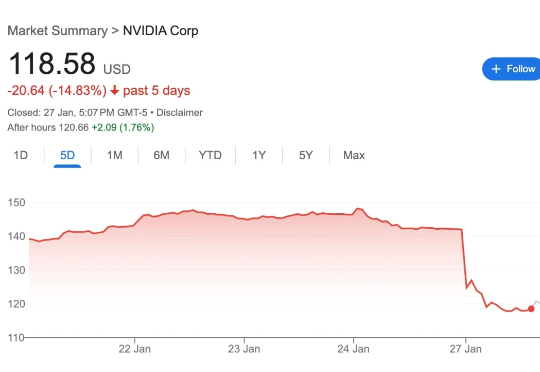
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。
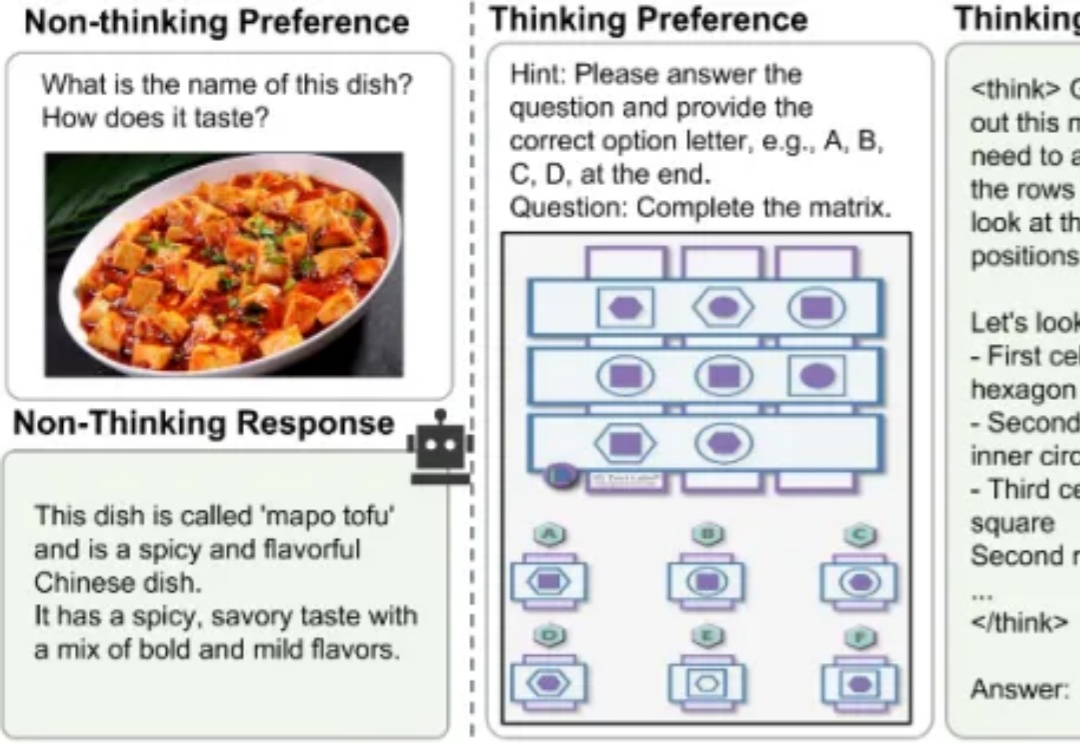
当前,业界顶尖的大模型正竞相挑战“过度思考”的难题,即无论问题简单与否,它们都采用 “always-on thinking” 的详细推理模式。无论是像 DeepSeek-V3.1 这种依赖混合推理架构提供需用户“手动”介入的快慢思考切换,还是如 GPT-5 那样通过依赖庞大而高成本的“专家路由”机制提供的自适应思考切换。

DeepSeek发布DeepSeek-V3.1,使用的UE8M0 FP8 Scale针对下一代国产芯片设计
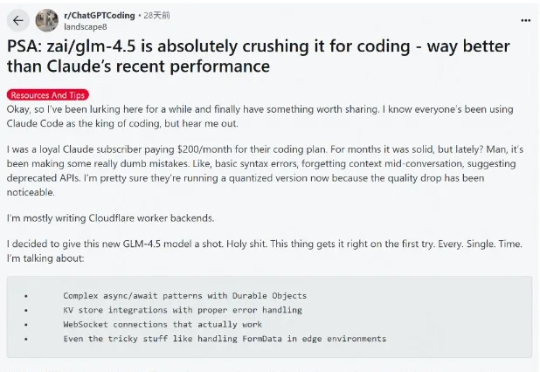
这段时间 AI 编程的热度完全没退,一个原因是国内接连推出开源了不少针对编程优化的大模型,主打长上下文、Agent 智能体、工具调用,几乎成了标配,成了 Claude Code 的国产替代,比如 GLM-4.5、DeepSeek V3.1、Kimi K2。

不止贴「AI生成」标签
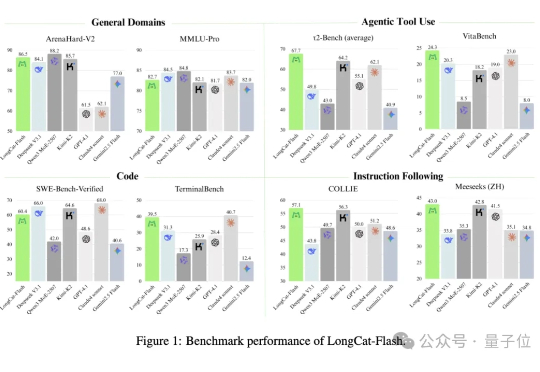
没想到啊,最新SOTA的开源大模型…… 来自一个送外卖(Waimai)的——有两个AI,确实不一样。 这个最新开源模型叫:Longcat-Flash-Chat,美团第一个开源大模型,发布即开源,已经在海内外的技术圈子里火爆热议了。
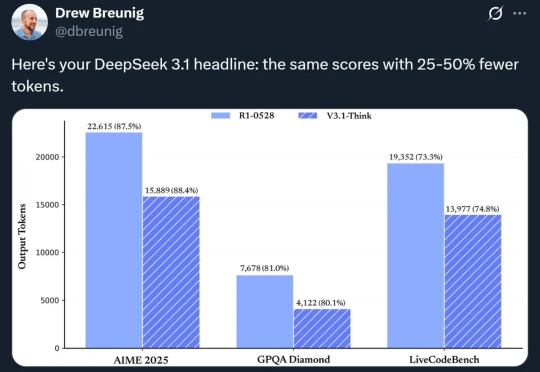
在最近的一档脱口秀节目中,演员张俊调侃 DeepSeek 是一款非常「内耗」的 AI,连个「1 加 1 等于几」都要斟酌半天。