
中国大模型首登Nature封面!DeepSeek首次披露:R1训练只花了200万
中国大模型首登Nature封面!DeepSeek首次披露:R1训练只花了200万就在最新的Nature新刊中,DeepSeek一举成为首家登上《Nature》封面的中国大模型公司,创始人梁文锋担任通讯作者。纵观全球,之前也只有极少数如DeepMind者,凭借AlphaGo、AlphaFold有过类似荣誉。
来自主题: AI资讯
10526 点击 2025-09-18 16:35
 搜索
搜索
就在最新的Nature新刊中,DeepSeek一举成为首家登上《Nature》封面的中国大模型公司,创始人梁文锋担任通讯作者。纵观全球,之前也只有极少数如DeepMind者,凭借AlphaGo、AlphaFold有过类似荣誉。
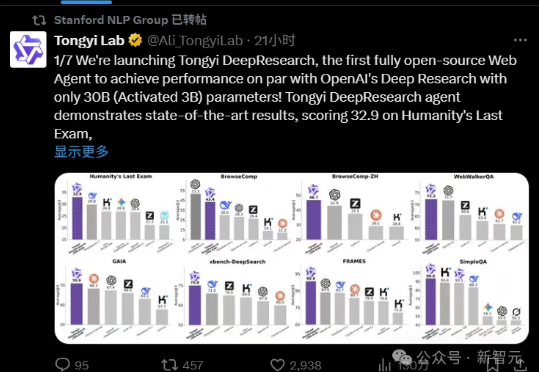
阿里昨晚放大招,正式开源通义DeepResearch,一举登顶碾压OpenAI、DeepSeek。模型、框架、方案全部开源,背后核心技术报告一同公开了。

DeepSeek荣登Nature封面,实至名归!今年1月,梁文锋带队R1新作,开创了AI推理新范式——纯粹RL就能激发LLM无限推理能力。Nature还特发一篇评论文章,对其大加赞赏。
这个世界,终于魔幻到我看不懂的程度了。故事是这样的。我最近刷淘宝挺多,然后昨天,鬼使神差的,在淘宝上,搜了一下DeepSeek。没有特定的理由,就是心血来潮,就是单纯的,想看看现在的生态。

“闭源人工智能在阻碍我们探索真正的科学。”
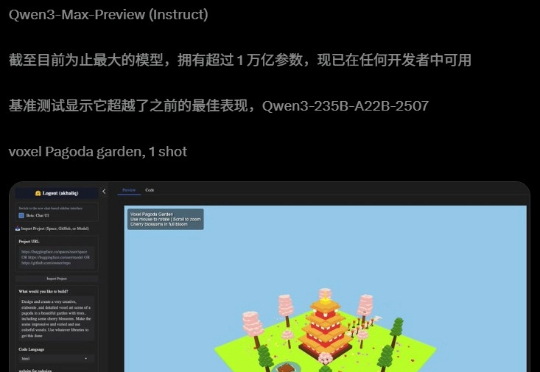
阿里迄今为止,参数最大的模型诞生了!昨夜,Qwen3-Max-Preview(Instruct)官宣上线,超1万亿参数性能爆表。在全球主流权威基准测试中,Qwen3-Max-Preview狂揽非推理模型「C」位,直接碾压Claude-Opus 4(Non-Thinking)、Kimi-K2、DeepSeek-V3.1。
为了“骗”过模型,有人每天陪AI聊天,摸透模型的脾气和规则;有人在图片里用透明字体写上诱导语,扰乱模型答案排序。

DeepSeek下一步,被曝剑指智能体。 知情人士透露,DeepSeek正在开发具有更强大AI Agent能力的新模型,预计在今年年底就会推出。

存款60美元、欠债1.5万美元,82岁的Luis正在积极学习提示词策略,创办科技公司,他想用AI为自己的人生来一场漂亮的收官;年近80的Scalettar,教会了96岁丈夫使用AI编辑。AI为许多美国老年人打开了一个新世界,他们比许多年轻人更接受,也更会用AI。

您对“思维链”(Chain-of-Thought)肯定不陌生,从最早的GPT-o1到后来震惊世界的Deepseek-R1,它通过让模型输出详细的思考步骤,确实解决了许多复杂的推理问题。但您肯定也为它那冗长的输出、高昂的API费用和感人的延迟头疼过,这些在产品落地时都是实实在在的阻碍。