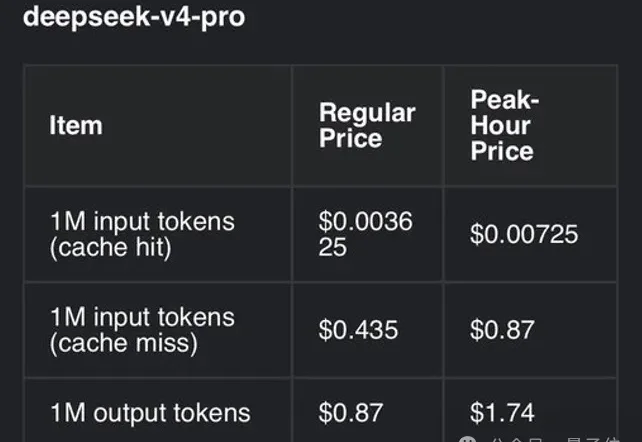
破天荒!DeepSeek V4正式版居然要涨价,而且翻着倍地涨
破天荒!DeepSeek V4正式版居然要涨价,而且翻着倍地涨也是神奇,价格屠夫DeepSeek,破天荒要涨价了!
来自主题: AI资讯
9553 点击 2026-06-30 15:43
 搜索
搜索
也是神奇,价格屠夫DeepSeek,破天荒要涨价了!

近期,DeepSeek发布DSpark让大模型推理效率再次成为行业焦点。
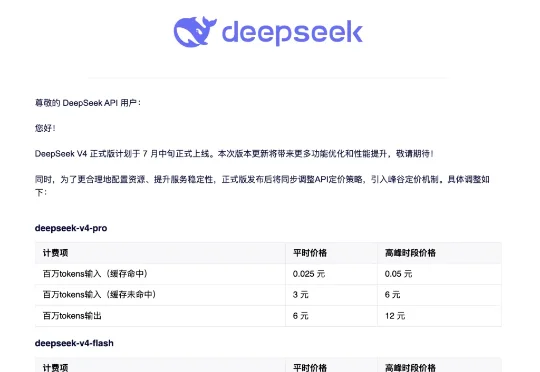
记者获悉,DeepSeek宣布价格调整,引入峰谷计费机制:以DeepSeek-v4-pro为例,其输入价格(缓存命中)平时为0.025元/百万tokens,高峰时期为0.05元/百万tokens;输入价格(缓存未命中)平时为3元/百万tokens,高峰时期为6元/百万tokens;输出价格平时为6元/百万tokens,高峰时期为12元/百万tokens。

你有没有想过一个问题: 我们平时选模型,到底有多少是因为它真的好用,又有多少是因为它便宜?

什么是DeepSeek开启融资的直接导火索?
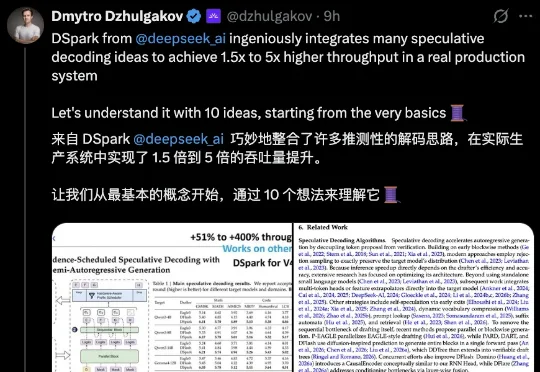
Fireworks AI的联合创始人兼CTO、PyTorch核心维护者Dmytro Dzhulgakov将整篇论文梳理成了10个概念,从最底层的GPU访存特性讲到最上层的在线自适应调度。DeepSeek这套方案真正的精髓在于系统工程和模型协同设计。

刚刚,DeepSeek V4 进行了一次更新。新推出了投机解码(Speculative Decoding)框架 DSpark,并同步开源了支撑该版本的全栈推测性解码框架 DeepSpec。DeepSeek-V4-Pro-DSpark 并非全新架构模型,而是在 DeepSeek-V4-Pro 基础上引入了推测性解码模块。此次更新的重点在于工程落地,而非模型能力本身的迭代。
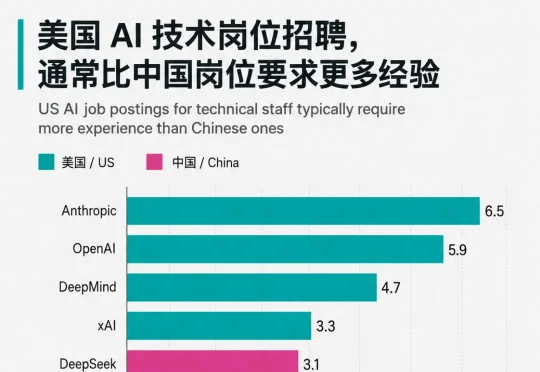
同样是进顶尖 AI 公司当工程师,在中国你只要 1.6 年经验,在美国却得熬到 5.5 年。换句话说,一个中国应届生刚拿到毕业证,就可能坐在 DeepSeek 的工位上调大模型;而他的美国同行还得在别的公司再「实习」四年,才够格投一份前沿 AI 实验室的简历。

当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?
6月17日,X 上 OpenAI Codex 团队负责人 Tibo(@thsottiaux)发了一条推文,提醒大家 Codex App、CLI 和 SDK 现在可以接任何开源模型,不只限于 OpenAI 自己的模型。