
谷歌DeepMind设立首个AI哲学家岗位,解决AGI伦理困境
谷歌DeepMind设立首个AI哲学家岗位,解决AGI伦理困境当奥特曼两次遇袭后,谷歌 DeepMind 悄悄做了一个反常规的决定:招一位哲学家。这是头部 AI 实验室第一次变相承认,AGI 已经不再只是工程问题。
来自主题: AI资讯
9760 点击 2026-04-15 10:07
 搜索
搜索
当奥特曼两次遇袭后,谷歌 DeepMind 悄悄做了一个反常规的决定:招一位哲学家。这是头部 AI 实验室第一次变相承认,AGI 已经不再只是工程问题。
月薪30K,去草原给DeepSeek运维机房。

Google DeepMind调查了一万个人,结果让整个AI安全评估体系汗颜:AI做了三倍多的「坏事」,但造成的实际伤害几乎一样。这意味着,我们现在用来证明AI安全的那套逻辑,可能从一开始就是错的。

我每次翻《天龙八部》,翻到少林寺藏经阁那一段,都要停下来。
2023 年,AI 生成的成人内容数量暴涨了 500%。同年,所有新增的成人素材里,有 25% 是 AI 造的。根据经济学人数据,AI 成人行业的规模在 2025 年大概 25 亿美元,这个数字往回倒 1 年是 1.5 亿美元,一年暴增 20 倍以上。AI 成人妥妥的「高速暴增品类」。

五年内实现AGI,算力是最大瓶颈。

硅谷「华人地图第一人」入局具身数据赛道。
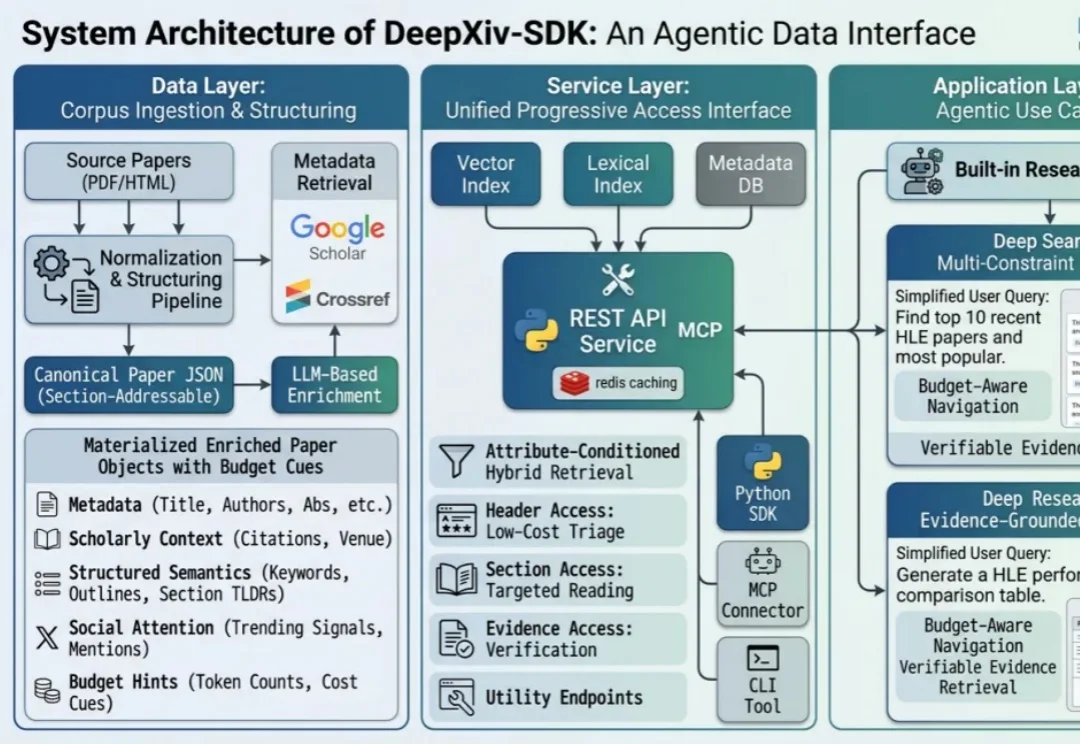
DeepXiv 是专为智能体设计的科技文献基础设施,把论文搜索、渐进式阅读、热点追踪和深度调研变成可调用、可编排、可自动化的能力。
不更是不更,一更就是个大动作,DeepSeek V4可能真的要来了!

谷歌Deep Think横扫亚欧多语种竞赛,AI科研工具的语言壁垒正在被拆掉,数学与科学发现进入AI驱动新时代。