阿里达摩院AI进展:做胸腹部CT,顺便筛了肠癌|独家对话和睦家医院朱刚主任
阿里达摩院AI进展:做胸腹部CT,顺便筛了肠癌|独家对话和睦家医院朱刚主任这是个一个月前的旧消息, 4月28日,达摩院联合广东省人民医院, 发布了一个叫DAMO COCA的, 肠癌筛查AI模型。
来自主题: AI资讯
9806 点击 2026-06-17 09:53
 搜索
搜索
这是个一个月前的旧消息, 4月28日,达摩院联合广东省人民医院, 发布了一个叫DAMO COCA的, 肠癌筛查AI模型。

AI能实现真正的沉浸式扮演了。
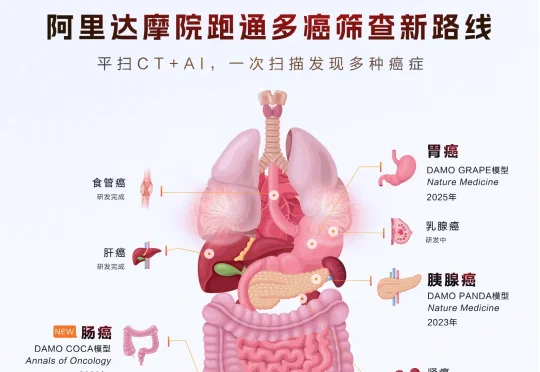
医生说平扫CT上看不见癌——AI找到了。 2021年5月,一位患者因突发腹痛被推进急诊,拍了一张平扫CT。 影像报告出来了——没有提及肠道有问题。 两年后,这位患者做了肠镜。确诊肠癌。肿瘤已经明显增大
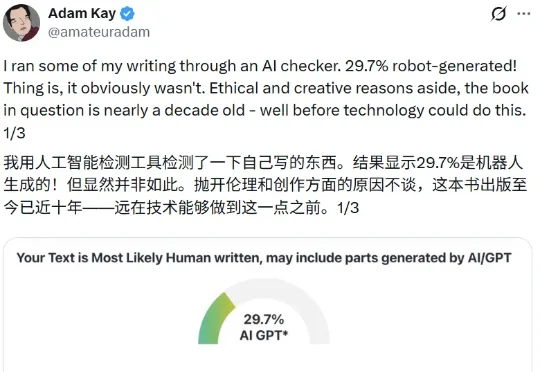
前两天,知名畅销书作家 Adam Kay 在社交媒体 X 分享了自己的经历:他心血来潮,把自己的作品丢进一款 AI 检测器里查重,结果系统信誓旦旦地判定其中有 29.7% 的内容由机器生成。
如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。

这个看似科幻的想法,正在被一家名为Simile的公司变成现实。他们刚刚完成了1亿美元的A轮融资,由Index Ventures领投,Hanabi、A星、Bain Capital Ventures参与投资,连人工智能领域的传奇人物Andrej Karpathy、Fei-Fei Li、Adam D'Angelo等都加入了投资行列。

大规模表格模型(LTM)而非大规模语言模型(LLM)的 Fundamental 公司 Nexus 模型,在多个重要方面突破了当代人工智能实践。该模型具有确定性——即每次被询问相同问题时都会给出相同答案——且不依赖定义当代大多数人工智能实验室模型的 Transformer 架构 。

Aishwarya Naresh Reganti 和 Kiriti Badam 曾在 OpenAI、Google、Amazon、Databricks 等公司参与构建并成功推出了 50 多个企业级 AI 产品。最近,他们在播客节目中,与主持人 Lenny 细致分享了当前 AI 产品开发中的常见陷阱与成功路径。基于该播客视频,InfoQ 进行了部分删改。

多语言大模型(MLLM)在面对多语言任务时,往往面临一个选择难题:是用原来的语言直接回答,还是翻译成高资源语言去推理?

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。