
腾讯开源最强3D生成模型,消费级显卡就能跑 | CVPR
腾讯开源最强3D生成模型,消费级显卡就能跑 | CVPR就在刚刚的CVPR上,鹅厂3D生成模型混元3D 2.1正式宣布开源!
来自主题: AI技术研报
9334 点击 2025-06-14 15:15
 搜索
搜索
就在刚刚的CVPR上,鹅厂3D生成模型混元3D 2.1正式宣布开源!

视频生成技术正以前所未有的速度革新着当前的视觉内容创作方式,从电影制作到广告设计,从虚拟现实到社交媒体,高质量且符合人类期望的视频生成模型正变得越来越重要。
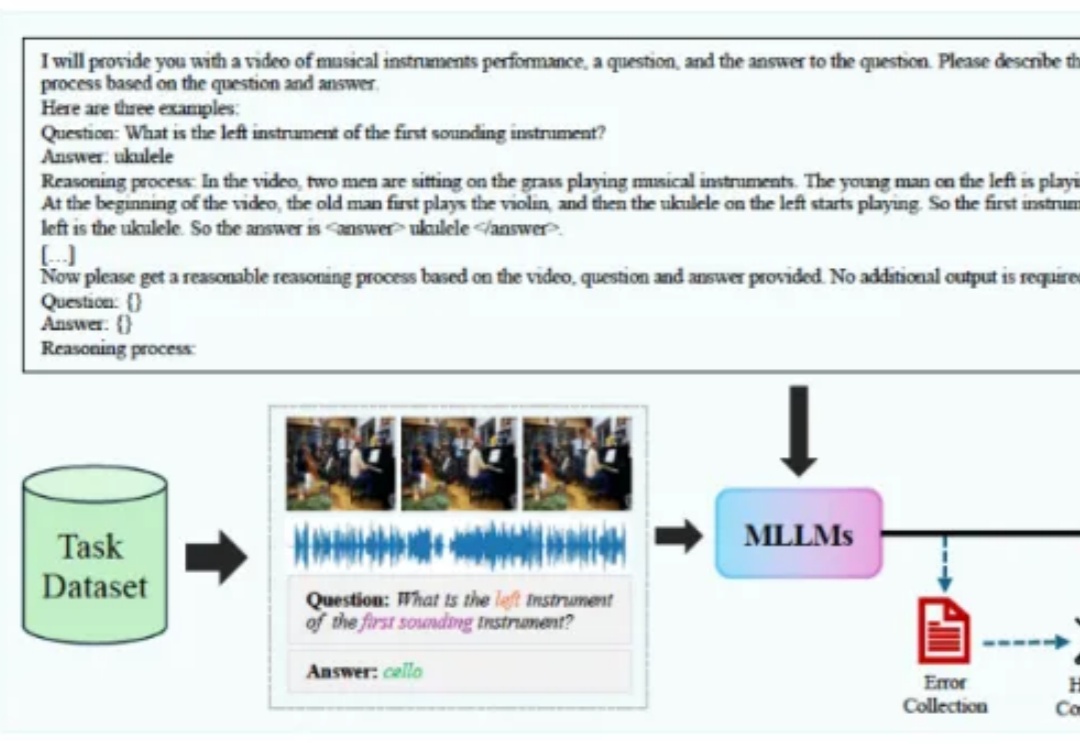
我们人类生活在一个充满视觉和音频信息的世界中,近年来已经有很多工作利用这两个模态的信息来增强模型对视听场景的理解能力,衍生出了多种不同类型的任务,它们分别要求模型具备不同层面的能力。
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。

AI模型用于工业异常检测,再次取得新SOTA!

研究者针对 few-shot 图像编辑提出一个新的自回归模型结构 ——InstaManip,并创新性地提出分组自注意力机制(group self-attention),在此任务上取得了优异的效果。
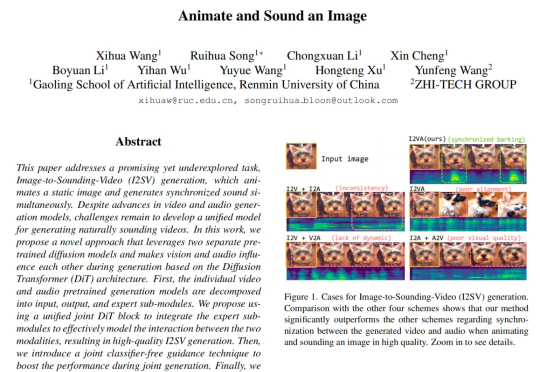
来自中国人民大学高瓴人工智能学院与值得买科技 AI 团队在 CVPR 2025 会议上发表了一项新工作,首次提出了一种从静态图像直接生成同步音视频内容的生成框架。其核心设计 JointDiT(Joint Diffusion Transformer)框架实现了图像 → 动态视频 + 声音的高质量联合生成。

在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:
来自香港中文大学(深圳)等单位的学者们提出了一种名为 DriveGEN 的无训练自动驾驶图像可控生成方法。该方法无需额外训练生成模型,即可实现训练图像数据的可控扩充,从而以较低的计算资源成本提升三维检测模型的鲁棒性。