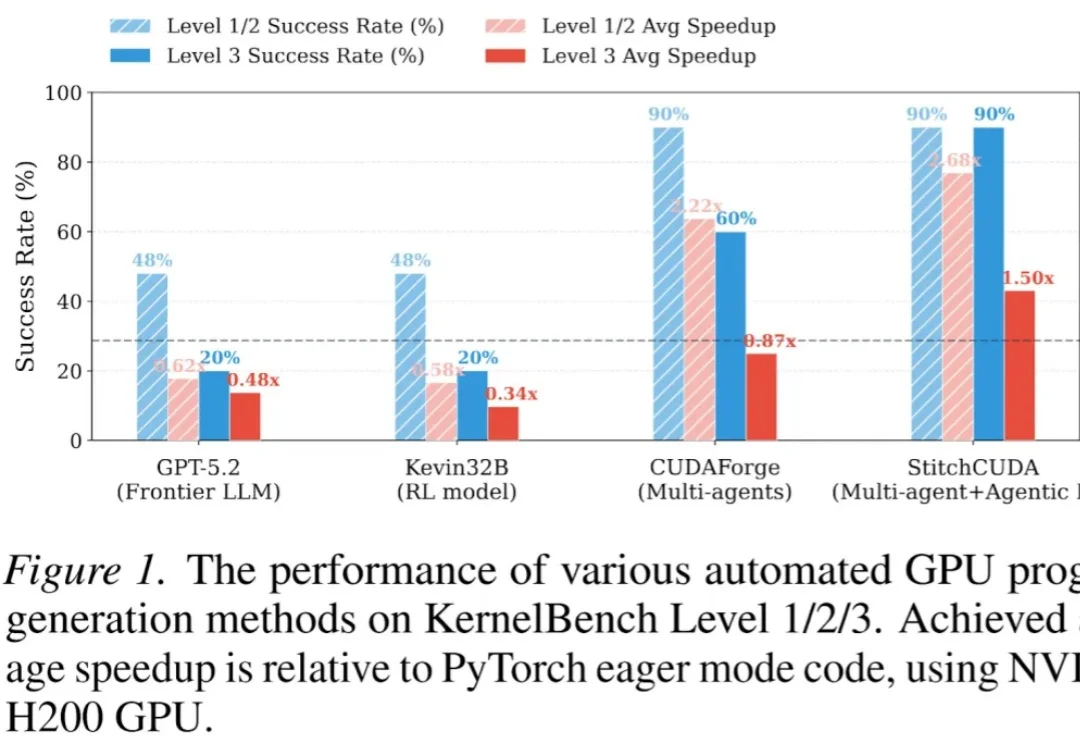
还在手写CUDA内核?CODA来了!LLM和新手也能让Transformer跑出光速
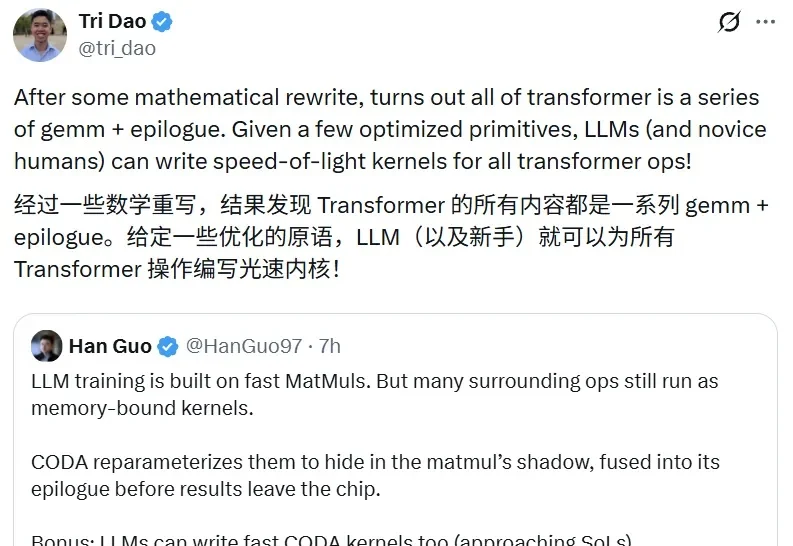
还在手写CUDA内核?CODA来了!LLM和新手也能让Transformer跑出光速5 月 22 日,Tri Dao 在社交媒体上转发了 Han Guo 的一条推文。他还写道:「经过一些数学重写,结果发现 Transformer 的所有内容都是一系列 GEMM + epilogue(矩阵乘法加尾声)。给定一些优化的原语,LLM(以及新手)就可以为所有 Transformer 操作编写光速内核!」
来自主题: AI技术研报
8898 点击 2026-05-25 10:13