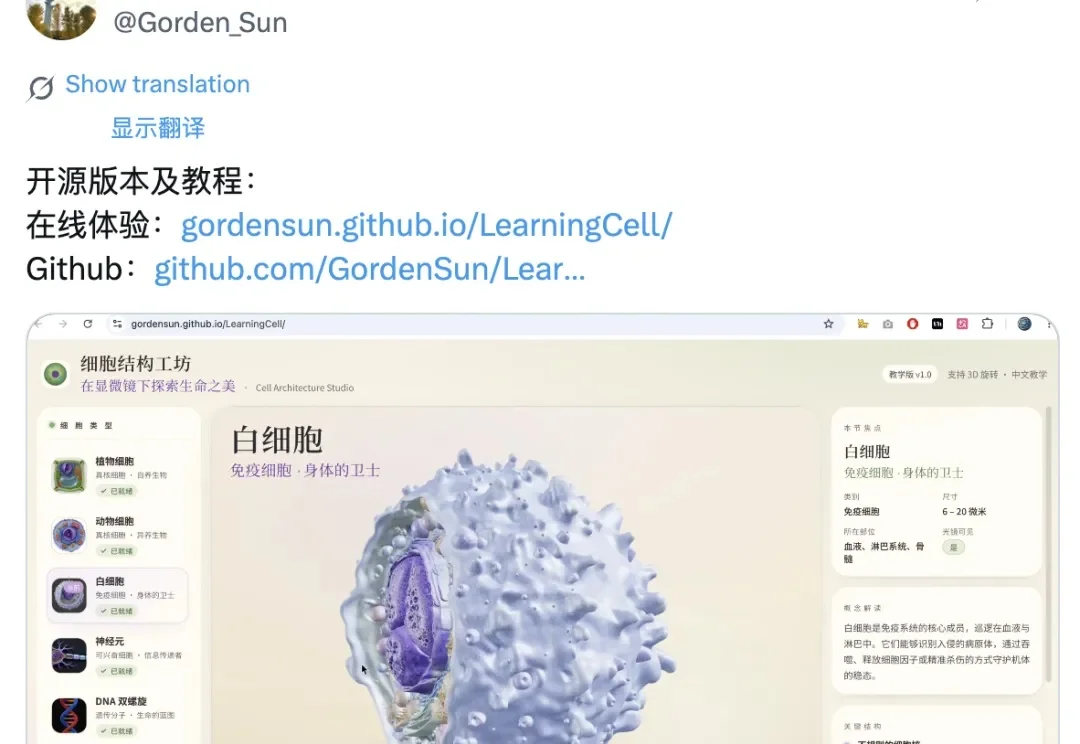
如何用 Codex + Blender,做出全网爆火的 3D 人体模型教科书?
如何用 Codex + Blender,做出全网爆火的 3D 人体模型教科书?这两天刷 X 的时候,发现一类项目特别火,就是用 Codex + Blender + 3D 生成工具做的交互式 3D 模型网站。
来自主题: AI技术研报
7036 点击 2026-05-22 09:58
 搜索
搜索
这两天刷 X 的时候,发现一类项目特别火,就是用 Codex + Blender + 3D 生成工具做的交互式 3D 模型网站。
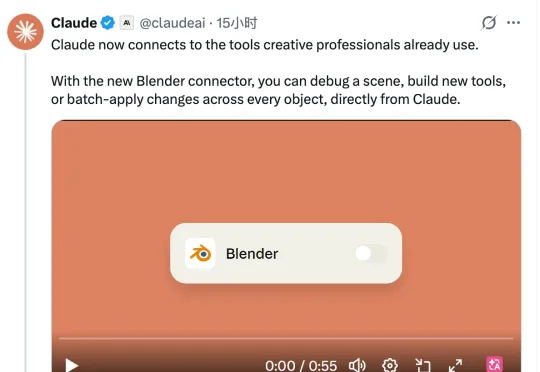
今天,Anthropic一口气甩出9个设计师专属连接器,以后可以直接在Blender、Photoshop、Premiere这些专业设计软件中使用Claude了。与先前推出的Claude Design不同,这次Anthropic不是要在自家软件里大包大揽,而是把Claude塞进了各大设计软件,用户可以用自然语言在Claude中使用这些专业设计软件,实现对3D模型、平面设计以及音乐等文件的创造和修改。

Anthropic今天宣布与Blender、Autodesk、Adobe、Ableton、Splice等多家合作伙伴联合推出一批连接器,涵盖了3D建模、平面设计、音乐制作和现场视觉等多个领域的创意工具,让Claude能够直接在创意专业人士日常使用的软件中运行。

曾几何时,用文字生成图像已经变得像用笔作画一样稀松平常。
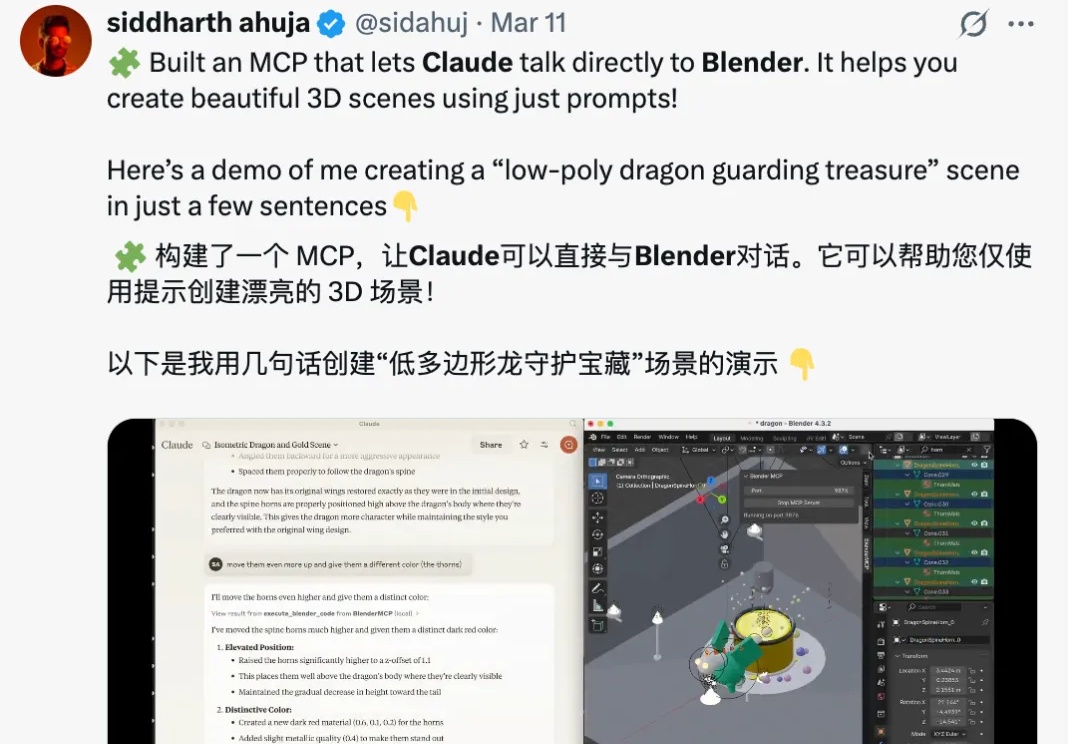
最近在推特上刷到一条视频,特别火爆,彻底把我看呆了。
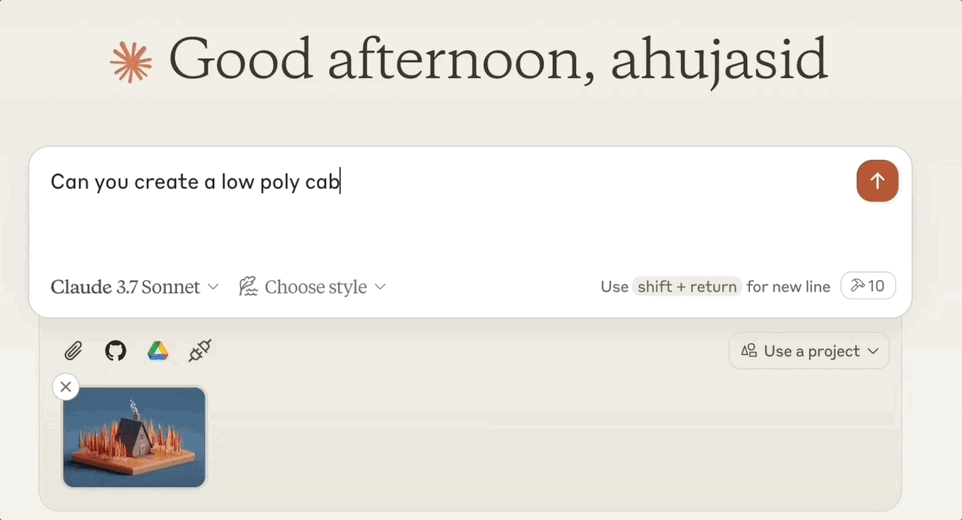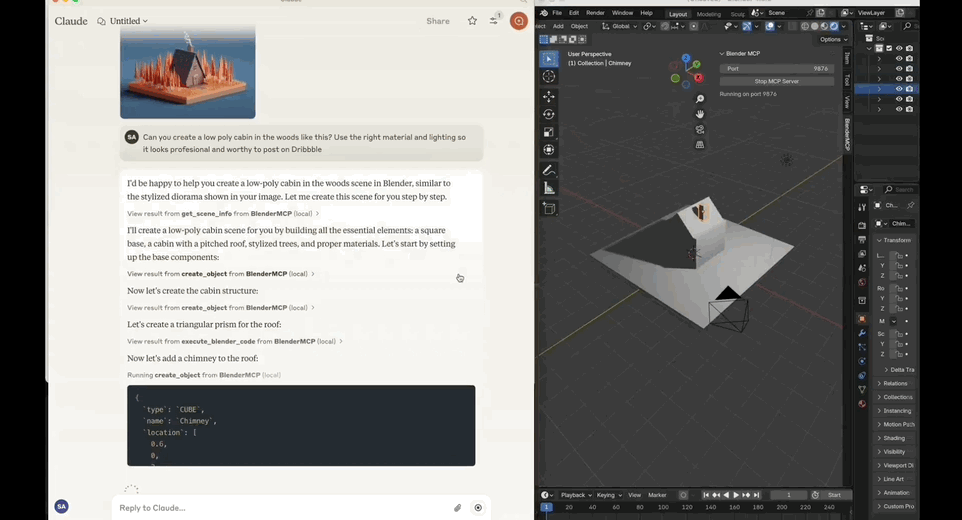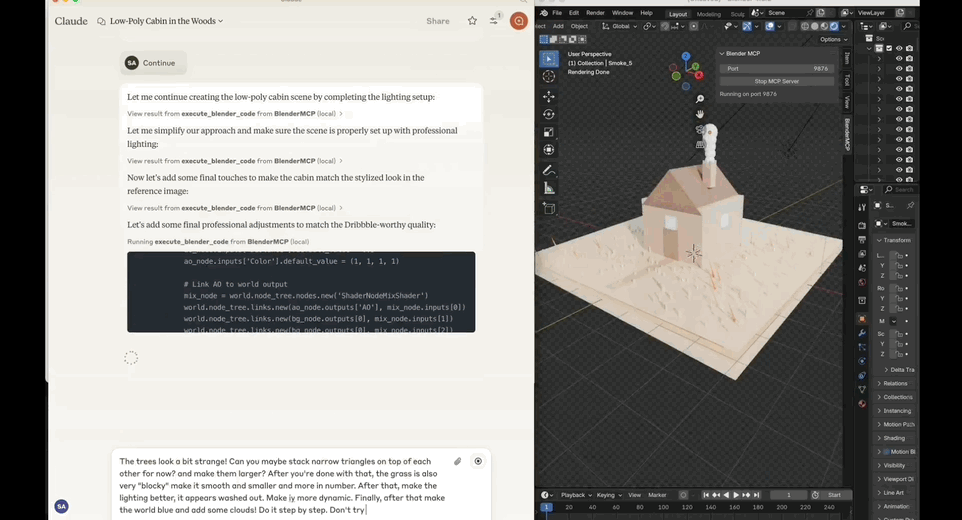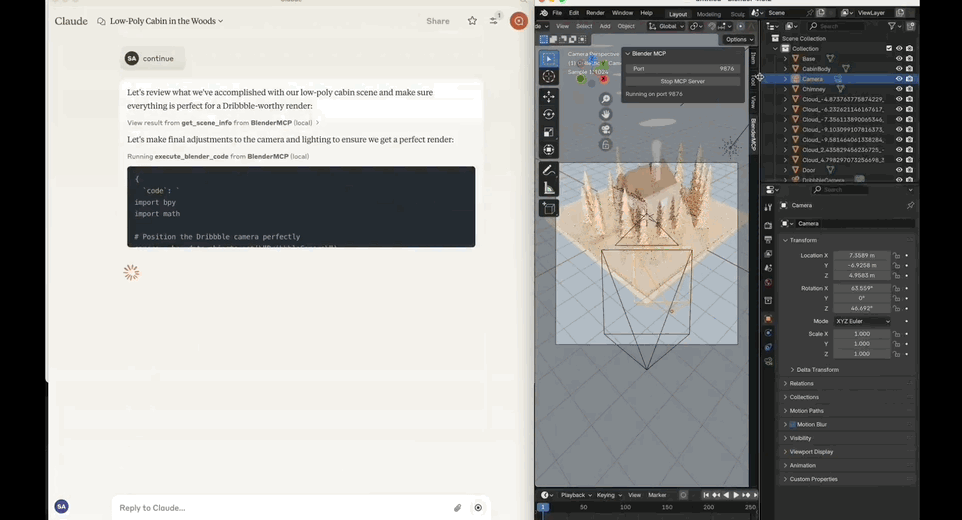
一句话提示,Claude自动化打开Blender将2D图片转为3D建模。背后关键还是最近大火的MCP(Model Context Protocol)——复刻Manus的重要诀窍。将这套协议和Blender打通,即可获得如上效果。该开源项目BlenderMCP,上线短短3天,GitHub标星已达3.8k。

来自中国科学院深圳先进技术研究院、中国科学院大学和 VIVO AI Lab 的研究者联合提出了一个无需训练的文本生成视频新框架 ——GPT4Motion。GPT4Motion 结合了 GPT 等大型语言模型的规划能力、Blender 软件提供的物理模拟能力,以及扩散模型的文生图能力,旨在大幅提升视频合成的质量。

Blend是一家英国初创公司,它正在利用人工智能来穿越噪音,帮助购物者找到适合他们风格、预算和尺码的个性化产品推荐。