
Anthropic自曝下一代Claude训练内幕!有人专职研究「性格」
Anthropic自曝下一代Claude训练内幕!有人专职研究「性格」Claude 100%编码Claude,这在圈内早已不是秘密。但Claude「自我造物」全过程,始终是Anthropic严防死守的核心机密。就在今天,Anthropic产品负责人Alex Albert在一场35分钟的访谈中,首次毫无保留地曝光了全细节!
来自主题: AI资讯
8902 点击 2026-05-23 11:16
 搜索
搜索
Claude 100%编码Claude,这在圈内早已不是秘密。但Claude「自我造物」全过程,始终是Anthropic严防死守的核心机密。就在今天,Anthropic产品负责人Alex Albert在一场35分钟的访谈中,首次毫无保留地曝光了全细节!
01 那个问题 ::: 什么是游戏? 这个问题比听起来要难。画面逼真不算,操控流畅不算,连开放世界都不算——你还需要有目标,有规则,有「我死了」和「我赢了」的判断。 Alberto Hojel 在 X
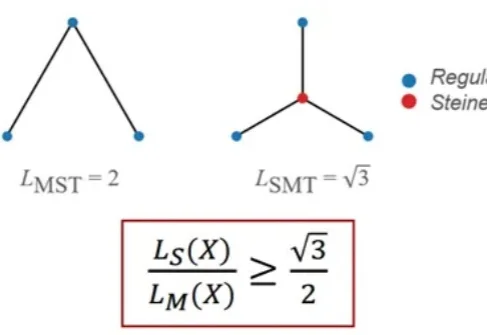
近期,LLM 已经在 IMO 上取得了很好的成绩,在一些研究级数学上(如短程证明、组合构造)也有所进展。但如果真正让 LLM 去处理提出数十年的数学猜想,结果会是如何?
中国AI研究员的性格、魅力和真诚……让人倍感亲切。这是艾伦研究所(Ai2)的研究员Nathan Lambert,在最近结束中国之行后,发自内心的一番感慨。在Nathan眼里,国内的LLM圈子简直是天堂,大家彼此尊重、即便立场不同也客客气气的。
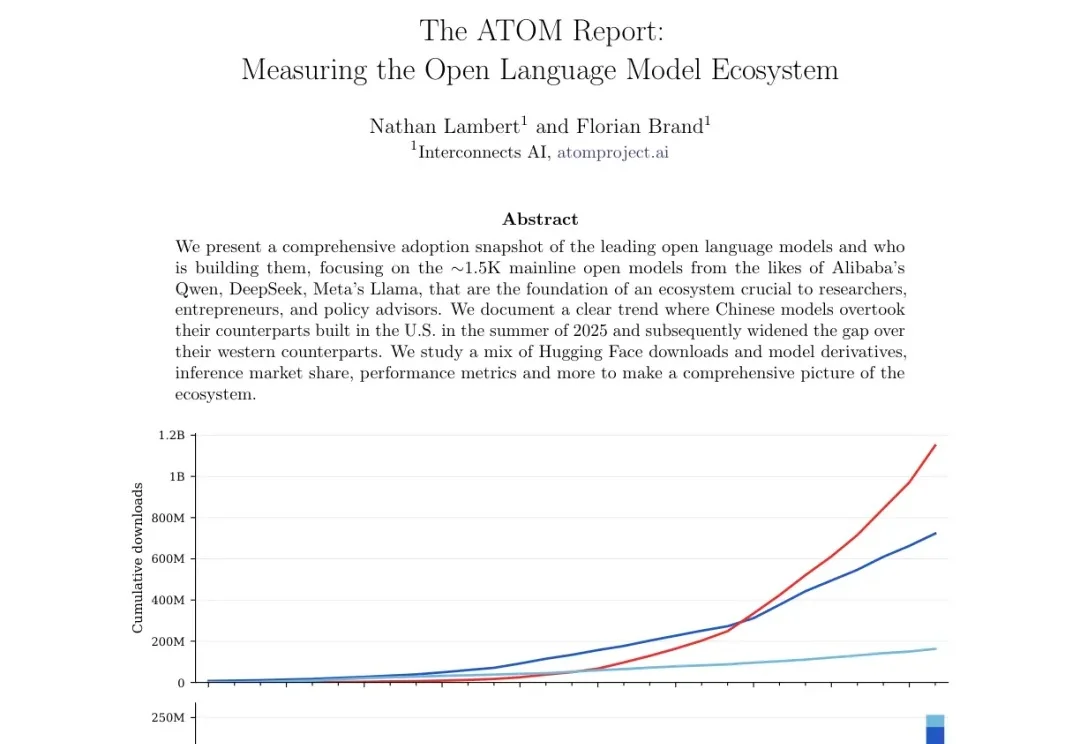
2026 年 4 月,Nathan Lambert 和 Florian Brand 发布了 The ATOM Report,一份关于开源语言模型生态的综合采纳度快照。这份报告追踪了约 1500 个主线开源模型的下载量、衍生模型、推理市场份额和性能数据,覆盖 2023 年 11 月到 2026 年 3 月
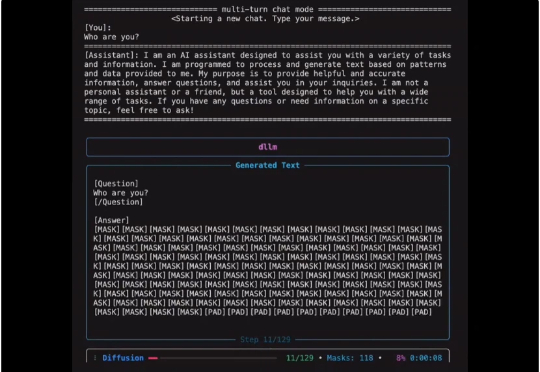
扩散式语言模型(Diffusion Language Model, DLM)虽近期受关注,但社区长期受限于(1)缺乏易用开发框架与(2)高昂训练成本,导致多数 DLM 难以在合理预算下复现,初学者也难以真正理解其训练与生成机制。

谷歌遗珠与IBM预言:一文点醒Karpathy,扩散模型或成LLM下一步。
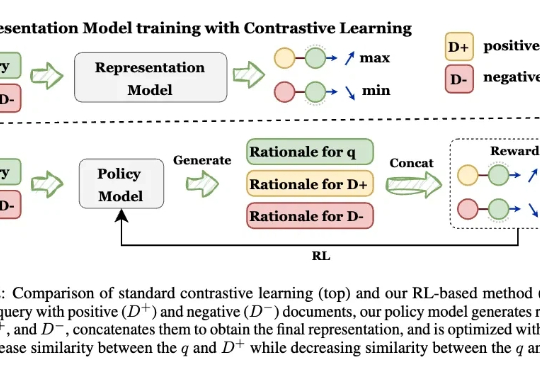
让模型先解释,再学Embedding! 来自UIUC、ANU、港科大、UW、TAMU等多所高校的研究人员,最新推出可解释的生成式Embedding框架——GRACE。过去几年,文本表征(Text Embedding)模型经历了从BERT到E5、GTE、LLM2Vec,Qwen-Embedding等不断演进的浪潮。这些模型将文本映射为向量空间,用于语义检索、聚类、问答匹配等任务。
Thinking Machines Lab发布首个产品:Thinker,让模型微调变得像改Python代码一样简单。也算是终于摘掉了“0产品0收入估值840亿”的帽子。Tinker受到了业界的密切关注。AI基础设施公司Anyscale的CEO Robert Nishihara等beta测试者表示,尽管市面上有其他微调工具,但Tinker在“抽象化和可调性之间取得了卓越的平衡”
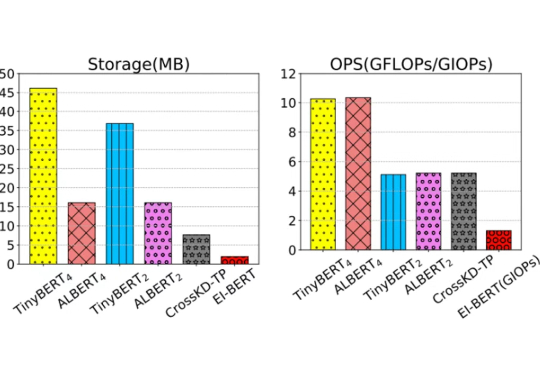
在移动计算时代,将高效的自然语言处理模型部署到资源受限的边缘设备上面临巨大挑战。这些场景通常要求严格的隐私合规、实时响应能力和多任务处理功能。