
20岁写出Transformer的人,真开源2180亿大模型Command A+
20岁写出Transformer的人,真开源2180亿大模型Command A+刚刚,Cohere放出2180亿参数的MoE大模型Command A+,单张B200可跑,支持48种语言,还带原生引用能力。但这次发布最炸的,不在参数表上,而在那一个许可证:Apache 2.0。
来自主题: AI资讯
9088 点击 2026-05-22 16:01
 搜索
搜索
刚刚,Cohere放出2180亿参数的MoE大模型Command A+,单张B200可跑,支持48种语言,还带原生引用能力。但这次发布最炸的,不在参数表上,而在那一个许可证:Apache 2.0。

MoE模型的稀疏激活本是优势,却常陷通信瓶颈。NVIDIA以软件为利剑,通过程序化依赖启动和全对全通信革新,在三个月内将GB200的单GPU吞吐提升2.8倍,真正释放Blackwell硬件潜力。

今天早上,Cursor 在X上发布一条推文:“我们重建了 MoE 模型在 Blackwell GPU 上生成 Tokens 的方式,导致推理速度快了 1.84 倍。”

所有用英伟达Blackwell B200的人,都在花冤枉钱??

马斯克“巨硬计划”新消息,第三栋专属厂房已经买下来了,代号MACROHARDRR。果然更硬核,老马透露,其将具备2GW供电规模。若参照此前曝光的(200MW支持11万台GB200)的功耗密度与架构效率推算,可支持约110万台英伟达GB200 NVL72 GPU。

谷歌不再甘当「云房东」,启动激进的TPU@Premises计划,直接要把算力军火卖进Meta等巨头的自家后院,剑指英伟达10%的营收。旗舰TPU v7在算力与显存上彻底追平英伟达 B200,谷歌用「像素级」的参数对标证明:在尖端硬件上,黄仁勋不再寂寞。通过拥抱PyTorch拆解CUDA壁垒,谷歌正在用「私有化部署+同级性能」的组合拳,凿开万亿芯片帝国的坚固城墙。
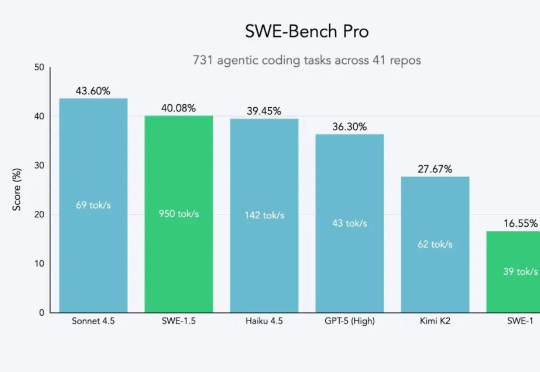
近日,开发出 Devin 智能体的知名人工智能公司 Cognition 推出其全新高速 AI 编码模型 SWE-1.5。据介绍,该模型专为在软件工程任务中实现高性能与高速度而设计,现已在 Windsurf 代码编辑器中开放使用。今年 7 月,Cognition 高调收购开发工具 Windsurf。
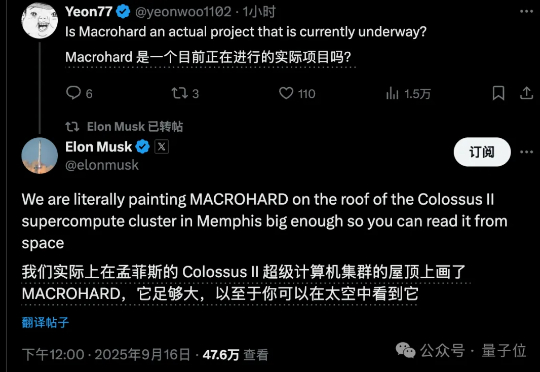
马斯克“巨硬计划”(MACROHARD)新动作曝光: 6个月从0建起算力集群,已完成200MW供电规模,足以支持11万台英伟达GB200 GPU NVL72。仅用6个时间,完成了OpenAI和甲骨文等合作花费15个月完成的工作,再次创造纪录。

“量子计算正在到达一个拐点。”

斯坦福Hazy实验室推出新一代低延迟推理引擎「Megakernel」,将Llama-1B模型前向传播完整融合进单一GPU内核,实现推理时间低于1毫秒。在B200上每次推理仅需680微秒,比vLLM快3.5倍。