
刚刚,Fable 5全球复活!限时7天,额度砍半
刚刚,Fable 5全球复活!限时7天,额度砍半刚刚,Anthropic正式官宣:Fable 5回来了!就这简单的一句话,让全网奔走相告。苦等19天,所有人像过年一样冲回Claude,就为了亲眼确认那个熟悉的名字重新亮起。而且千万注意,一旦额度达上限,Fable 5跑起来的Token消耗远超Opus 4.8。
来自主题: AI资讯
8917 点击 2026-07-02 09:31
 搜索
搜索
刚刚,Anthropic正式官宣:Fable 5回来了!就这简单的一句话,让全网奔走相告。苦等19天,所有人像过年一样冲回Claude,就为了亲眼确认那个熟悉的名字重新亮起。而且千万注意,一旦额度达上限,Fable 5跑起来的Token消耗远超Opus 4.8。
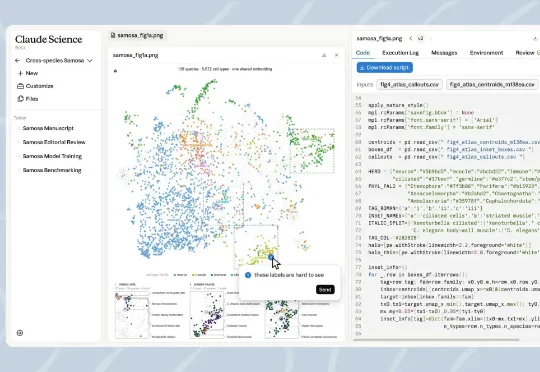
6月30日晚,AI龙头Anthropic推出了专为科学研究打造的新产品Claude Science,这是一款类似于编程工具Claude Code的AI工作台。简单来说,Claude Science是一套专门为科研需求打造的多智能体架构,能自动生成多个子代理并分配他们进行科研任务。

Anthropic偷偷把隐形代码藏在Claude Code,持续3个月余。被抓包后,Claude Code负责人辩解称:都是误会,马上移除!刚刚,Anthropic承认Claude Code存在「木马」,明天就回滚。
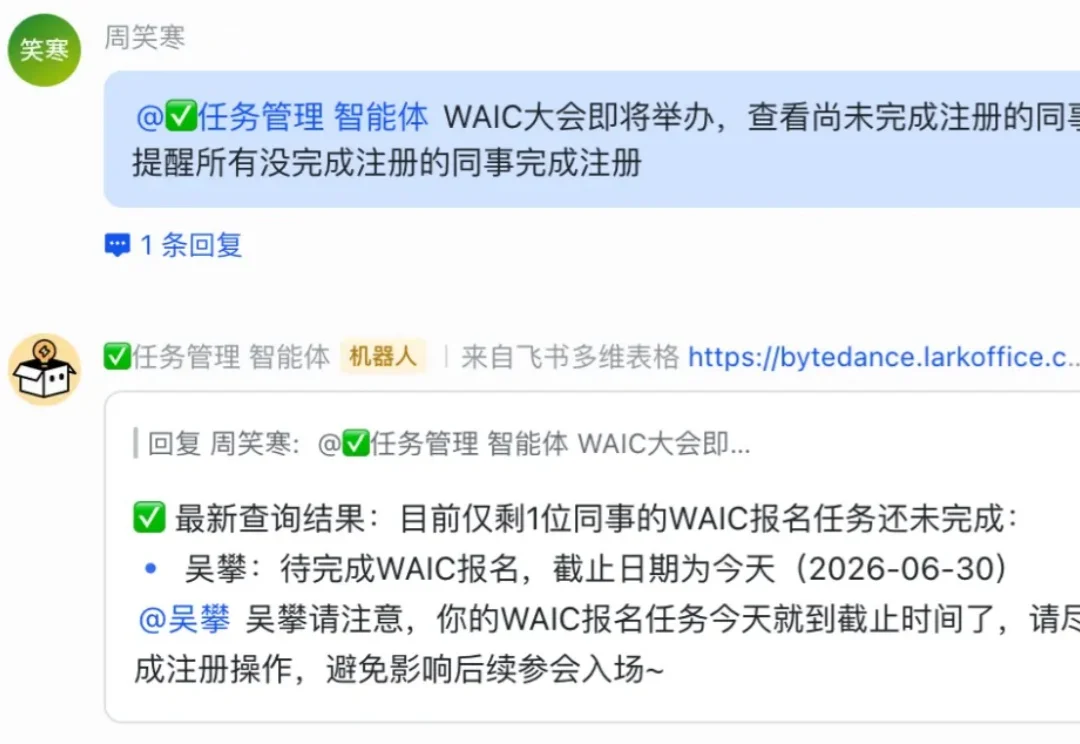
6 月 23 日,Anthropic 发布了一个叫 Claude Tag 的东西。

6月30号,《科创板日报》独家报了个消息:Kimi上一轮融资刚交割完,新一轮已经启动了。上一轮投后估值200亿美元,新一轮投前315亿美元。今天的中国一级市场,已经默认了一件事,Kimi应该继续融资,OpenAI和Anthropic也应该继续融资。

18天后,AI圈终于迎来了一场狂欢!今天,Anthropic官宣:美国商务部正式撤销对Anthropic旗下神级模型Fable 5(以及Mythos 5)的出口管制,明天恢复访问。
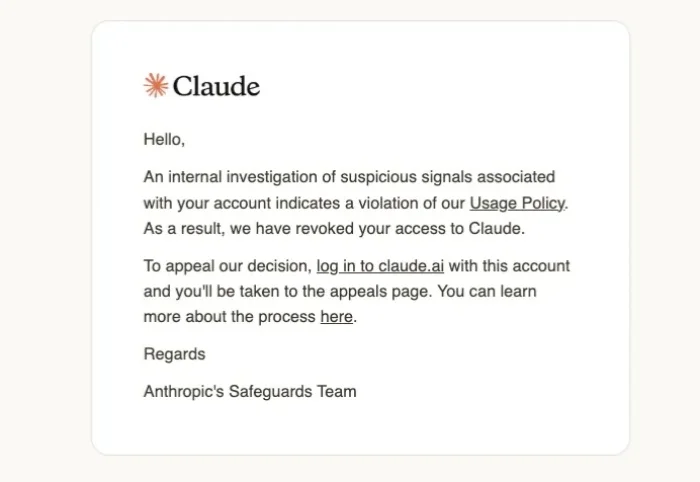
这两天,Claude大面积封号。

就在刚刚,Claude Sonnet 5来了!代号Fennec,耳廓狐,撒哈拉沙漠里体型最小的狐狸。相较于上一代Sonnet 4.6,Sonnet 5在推理、工具使用、编程和知识工作任务中,性能显著提升。

都说AI会写代码了,程序员的饭碗就保不住。但Anthropic的Boris Cherny却说:真正重要的从来不是岗位,而是你这一刻在扮演哪种角色。

AI能提效不假,但账单却越来越看不懂了。