
华人一作!Meta等复刻AlphaZero神话,AI甩开人类自修成神
华人一作!Meta等复刻AlphaZero神话,AI甩开人类自修成神当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。
来自主题: AI技术研报
10616 点击 2025-12-29 09:06
 搜索
搜索
当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。
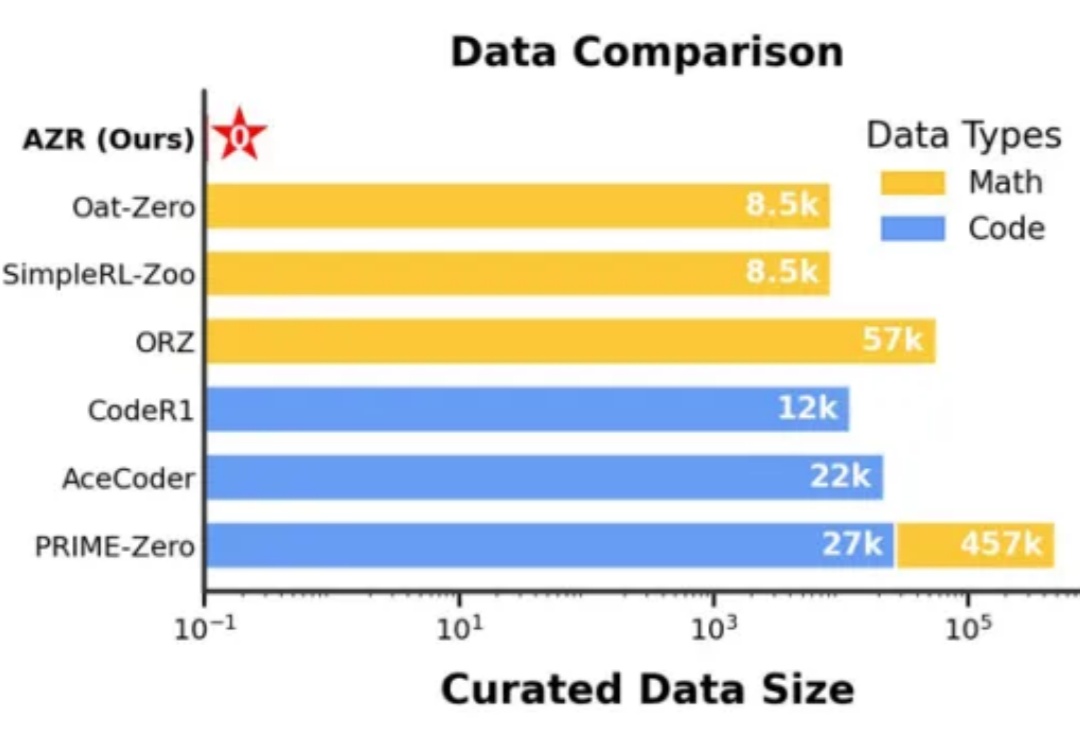
在人工智能领域,推理能力的进化已成为通向通用智能的核心挑战。近期,Reinforcement Learning with Verifiable Rewards(RLVR)范式下涌现出一批「Zero」类推理模型,摆脱了对人类显式推理示范的依赖,通过强化学习过程自我学习推理轨迹,显著减少了监督训练所需的人力成本。

人和智能体共享奖励参数,这才是强化学习正确的方向?

如果说有一类游戏贯穿AI发展的始终,围绕其诞生的Thinking Game至今仍影响着最前沿AI技术的发展,那么答案很显然: 棋类游戏。
从 AlphaGo、AlphaZero 、MuZero 到 AlphaCode、AlphaTensor,再到最近的 Gemini 和 AlphaProof,Julian Schrittwieser 的工作成果似乎比他的名字更广为人知。

在陈思诚导演、上映一个多月便揽下3亿票房的谍战片《解密》中,主人公容金珍是一位民国时期的数学天才,大学毕业后本已开始从事“机器人脑”的研究工作,却在机缘巧合之下被谍报机关招募,自此一生奉献给了密码破译。