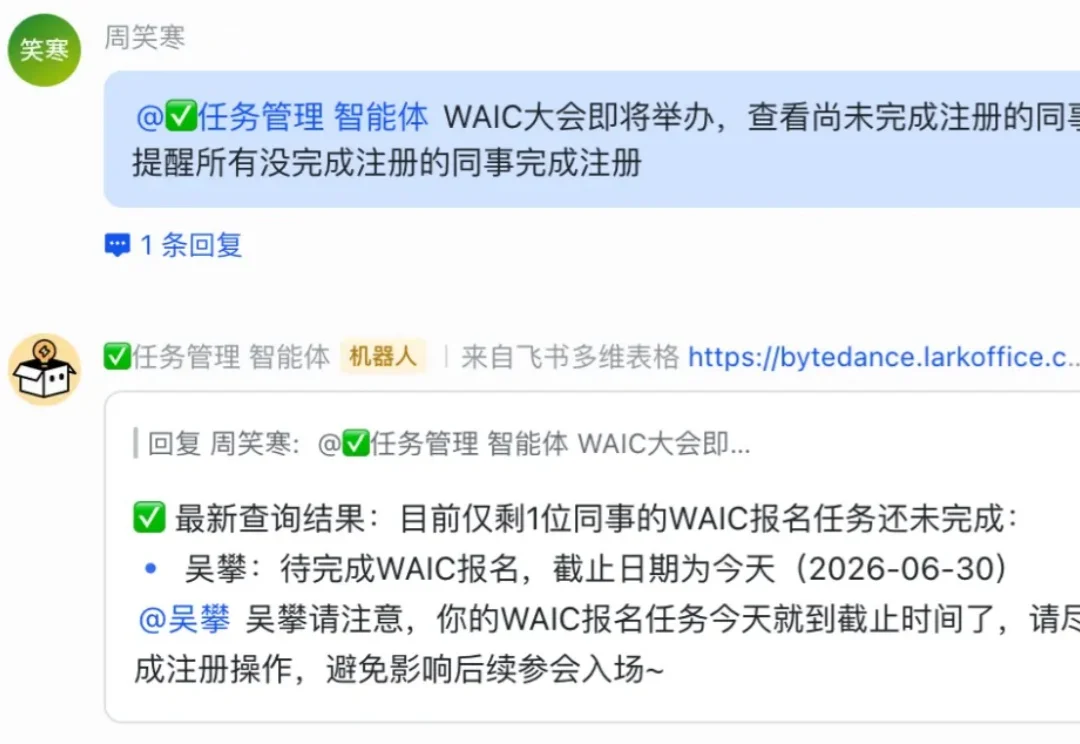
飞书让表格变成「AI同事」加入群聊,不打开表就能用表
飞书让表格变成「AI同事」加入群聊,不打开表就能用表6 月 23 日,Anthropic 发布了一个叫 Claude Tag 的东西。
来自主题: AI资讯
6897 点击 2026-07-01 16:22
 搜索
搜索
6 月 23 日,Anthropic 发布了一个叫 Claude Tag 的东西。

AI 视频初创公司 Higgsfield AI 正在与投资者洽谈,筹资 3 亿美元至 5 亿美元,投资前估值为 50 亿美元,据两位知情于此次筹资活动的人士透露。Higgsfield 制作了一个用于 AI 图像和视频生成的平台,允许用户从文本创建视觉内容,并编辑视频的运动控制、音频和其他组件。
去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。

Prompt还没退场,Loop已经开始接管AI叙事。
这几天,全国高考成绩陆续放榜。1290万考生查到了自己的分数,无数家庭的目光,再次聚焦在一张分数条、一道分数线上——在大多数人的认知里,这仍是通往未来最重要、甚至唯一的那条路。

本篇文章根据我在本月 43 Talks 线下活动中的分享整理而成。主理人李继刚邀请我时,给的主题词只有一个:Context。我想从 Agent 的视角出发,讨论一个判断:随着模型和 Harness 逐步趋同,真正决定 Agent 能力边界的,会越来越是 Context。

Yann LeCun的JEPA架构很可能不会work,但至少证明了隐空间比像素或文本空间具备更强的泛化能力;
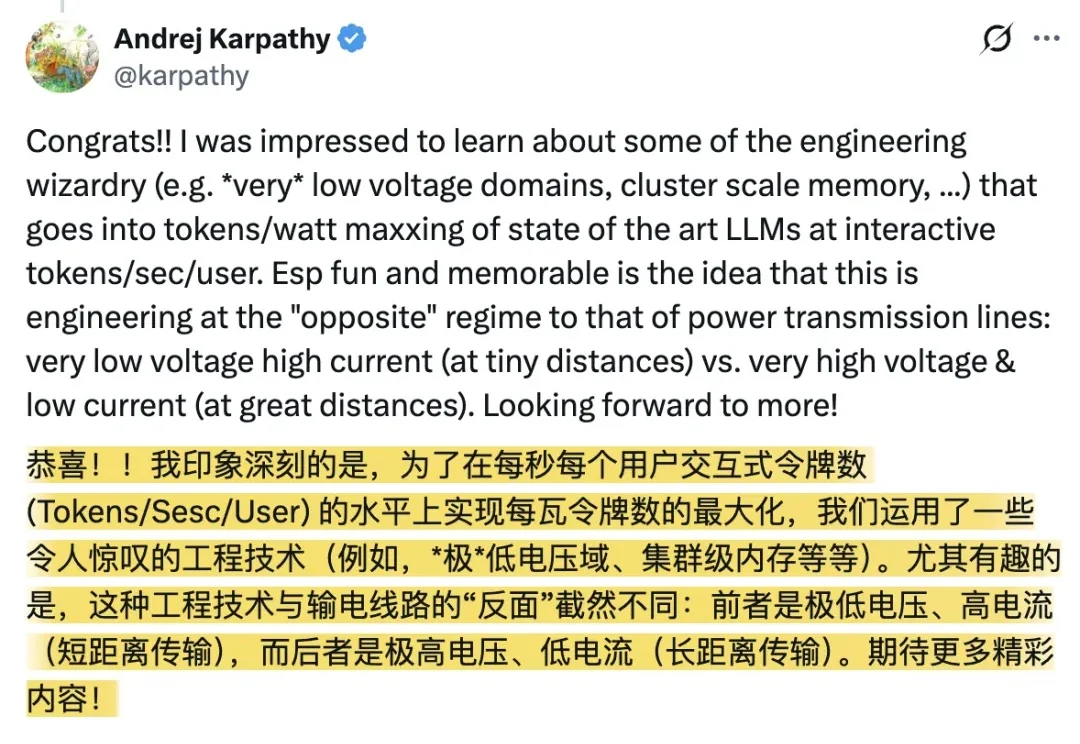
一家只做Transformer专用芯片的创业公司成功流片,连带官宣了一串大进展: 不仅筹集到了8亿美元的资金,还喜滋滋获得了10亿美元的客户大单。
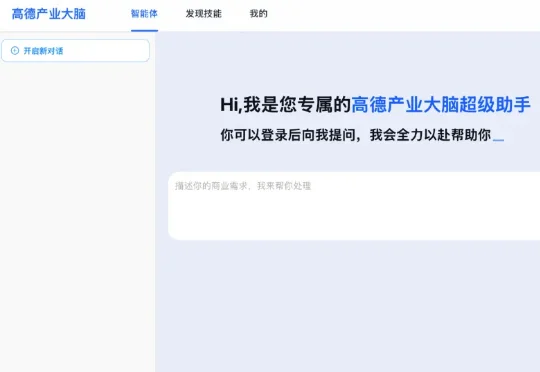
行业消息人士向《读佳》透露,高德已开启首款面向B端产业场景的AI助手产品内测,推出企业级AI操作系统“高德产业大脑”,正式布局企业组织智能化、数字化提效赛道。 据了解,高德产业大脑定位为企业级底层AI
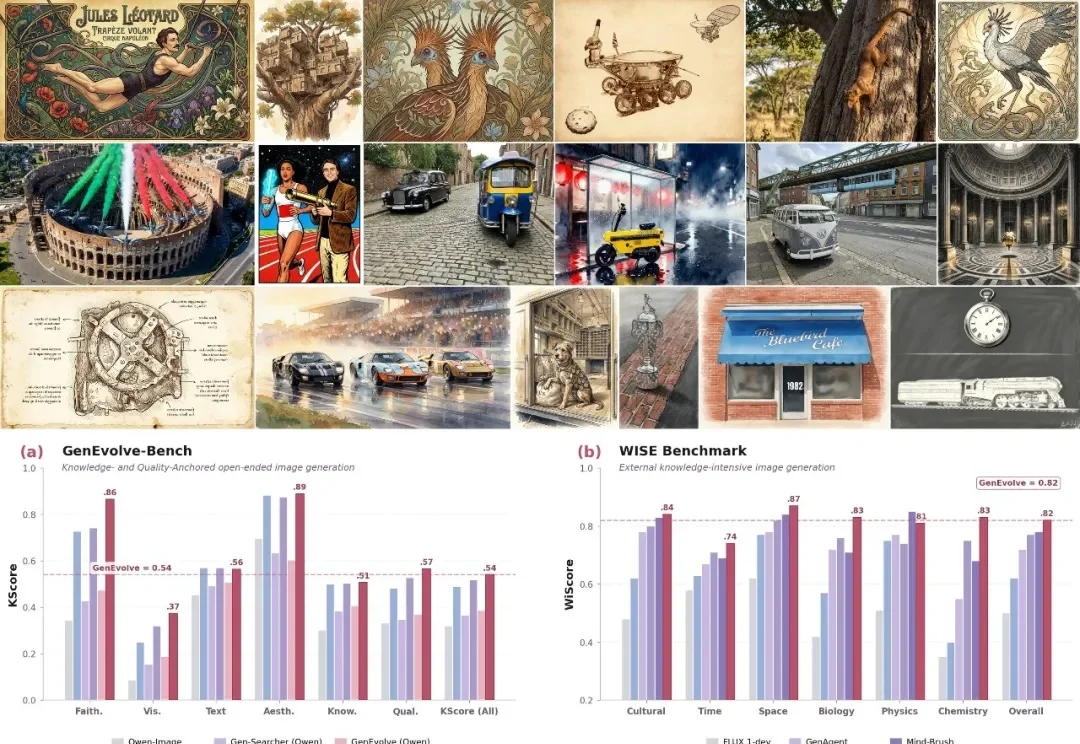
图像生成正在从「一句话生成一张图」,走向更接近真实创作流程的开放任务。