
本周 AI 项目推荐:Link、Agentic Wallets、Token Pay......Token支付底座长啥样
本周 AI 项目推荐:Link、Agentic Wallets、Token Pay......Token支付底座长啥样什么是AI原生支付?随着全世界个体token的消耗量猛增,越来越多的大玩家和初创公司开始瞄准AI支付机制和基础设施的问题。
来自主题: AI资讯
7483 点击 2026-06-29 10:20
 搜索
搜索
什么是AI原生支付?随着全世界个体token的消耗量猛增,越来越多的大玩家和初创公司开始瞄准AI支付机制和基础设施的问题。

阿里云正式宣布,Apache Flink 3.0全面进入Agentic Streaming For AI时代,并推出全模态数据流处理能力。这是业界第一次,把视频、音频、图像、文本这四类数据,统一放进同一条流式pipeline里调度,让AI能够实时感知、实时理解、实时回应。

刚刚,在维也纳落幕的机器人顶会ICRA 2026上,最佳论文奖(自动化方向)颁给了一支中国团队。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。
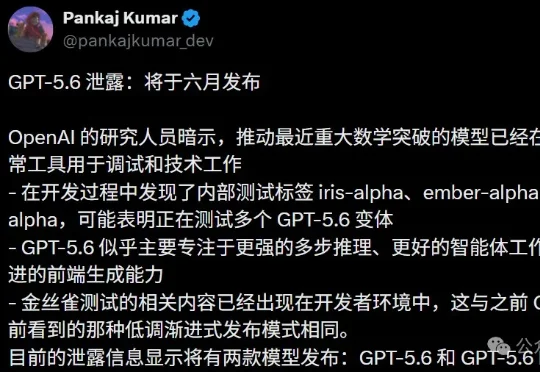
GPT-5.6本月上桌,agentic编码据称已反超Anthropic Mythos!三家旗舰模型撞进同一个6月,两大AI巨头同时冲刺IPO,奥特曼却在内部抛出了一个更大的变量:如果AI先学会自我改进,上市反而不急。
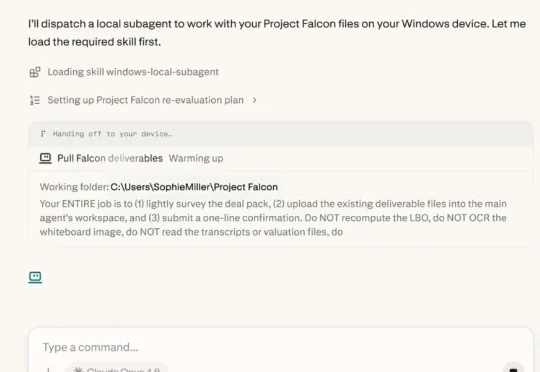
当地时间 6 月 2 日,Perplexity 在 Computex 2026 的 Intel 主题演讲上,做了一个很多人没太在意、但可能改变整个 AI 应用行业走向的演示。不是新模型,不是更快的搜索,而是一套「任务路由」系统。

近日,「智能知识」(Human Intelligence)完成天使轮融资,由耀途资本、锦秋基金联合投资。本轮融资资金将用于两个方向:前沿数据品类扩张:深耕 Coding、Enterprise Office(GDPVal)、Agentic Tool Use 等高价值数据,并积极探索 AI4Math、AI4Science、AutoResearch 等新场景;

今日,在2026阿里云峰会上,阿里云正式亮出Agentic时代 “超级算力地基”。阿里云正式发布磐久AL128超节点服务器,搭载平头哥首次亮相的自研训推一体AI芯片真武M890,搭配自研互联芯片ICN Switch 1.0,单机柜128张AI芯片紧密耦合,组成一台“计算机”。
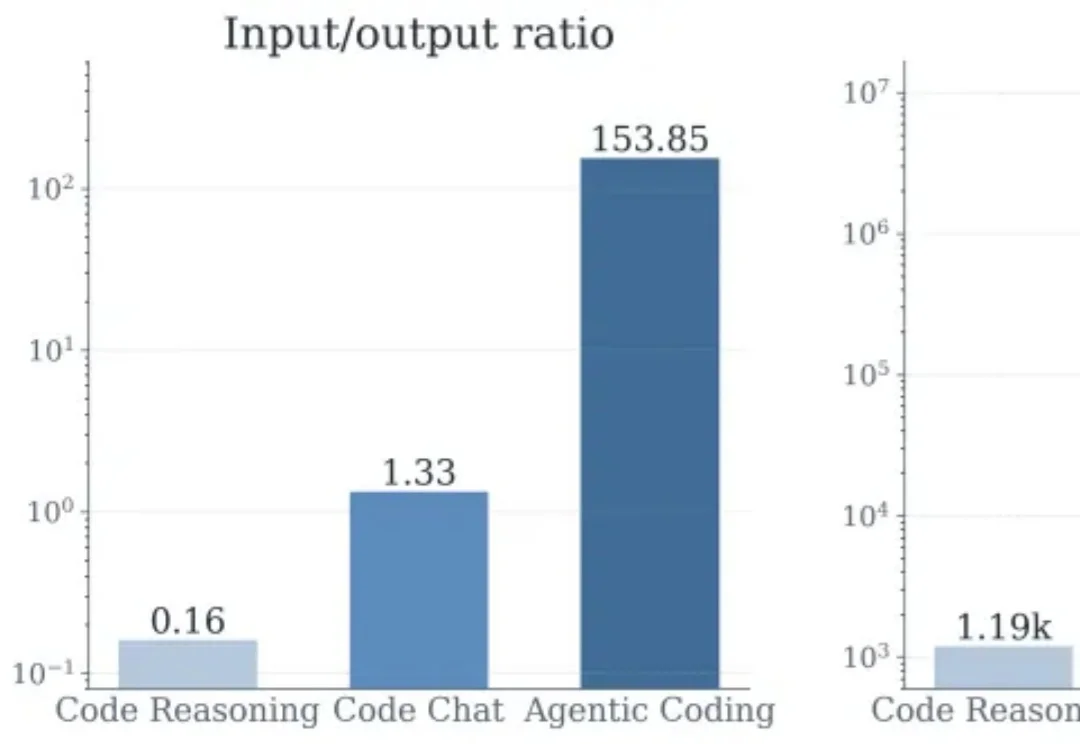
如今的 AI Agent 正在大规模落地,其中应用最广且最受关注的当数 Claude Code,Codex,Cursor 这类 coding agent。过去的一年里,这类 coding agent 产品迭代迅速,在一年内将在 swe-bench- verified 的准确率提高到了 78%+。
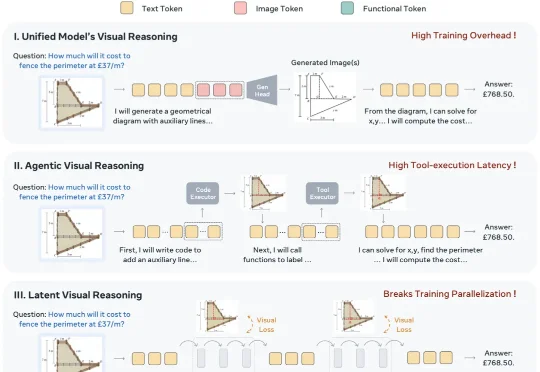
近日,Meta AI 与香港中文大学颠覆性提出了一种全新的视觉推理范式 ATLAS,不用外部工具,不显式生成中间图像,没有视觉监督信号,只用一个离散 word,首次颠覆性地代替 Agentic 和 Latent Visual Reasoning。