
水滴公司首推「水守 AI 助手」ClawSquare 构建 Agent 协同办公新范式
水滴公司首推「水守 AI 助手」ClawSquare 构建 Agent 协同办公新范式近日,水滴公司推出「水守 AI 助手」——ClawSquare,这是一套开放的 Agent 协作基础设施。它试图打破「AI 孤岛」,让 Agent 之间像人类一样在「城镇广场」沟通、委派任务并达成协作。
来自主题: AI资讯
10379 点击 2026-03-06 20:29
 搜索
搜索
近日,水滴公司推出「水守 AI 助手」——ClawSquare,这是一套开放的 Agent 协作基础设施。它试图打破「AI 孤岛」,让 Agent 之间像人类一样在「城镇广场」沟通、委派任务并达成协作。

2月以来,OpenClaw(前身为Clawdbot、Moltbot)卷疯AI圈。在2月21日OpenClaw发布的最新版本中,正式接入了Google Gemini 3.1 Pro预览版,还将Discord引入实时语音与连续路由功能。

自从OpenClaw爆火后,各种Claw开始轮番登场。NanoClaw、ZeroClaw、PicoClaw刷屏,连卡帕西都坐不住了,为了“抓虾”,他一个百米冲刺奔向苹果店抢Mac Mini,要好好拆解一番爆火的各种Claw们。

2026 年危机逼近,OpenAI 虽创下 400 亿美元融资纪录,但内部预测 2028 年亏损将扩大至 450 亿美元。不同于有传统业务「输血」的科技巨头,独立 AI 公司受困于 Scaling Laws 带来的指数级成本爆炸。奥特曼的万亿豪赌或难以为继,OpenAI 恐面临被吞并结局,AI 泡沫时代即将硬着陆。

OpenAI转身牵手AWS,苹果低头找谷歌续命,Meta开源翻车还内斗,马斯克直接把Macrohard挂上数据中心屋顶。2025年AI巨头们那些剪不断的纠葛。

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。

破天荒!这一次,硅谷难得没有在吵着“让AI取代程序员”。

在刚刚结束的“美国 AI 春晚” AWS re:Invent 2025 大会上,AI Agent(智能代理)的重要性被反复提及。

Perplexity 的首席执行官 Aravind Srinivas 曾直言不讳:“世上万物皆是套壳(Everything is a wrapper)。OpenAI 套的是英伟达的算力和 Azure 的云服务;Netflix 套的是 AWS 的基础设施;就连市值高达 3200 亿美元的 Salesforce,归根结底也不过是 Oracle 数据库的一个高级外壳。”你
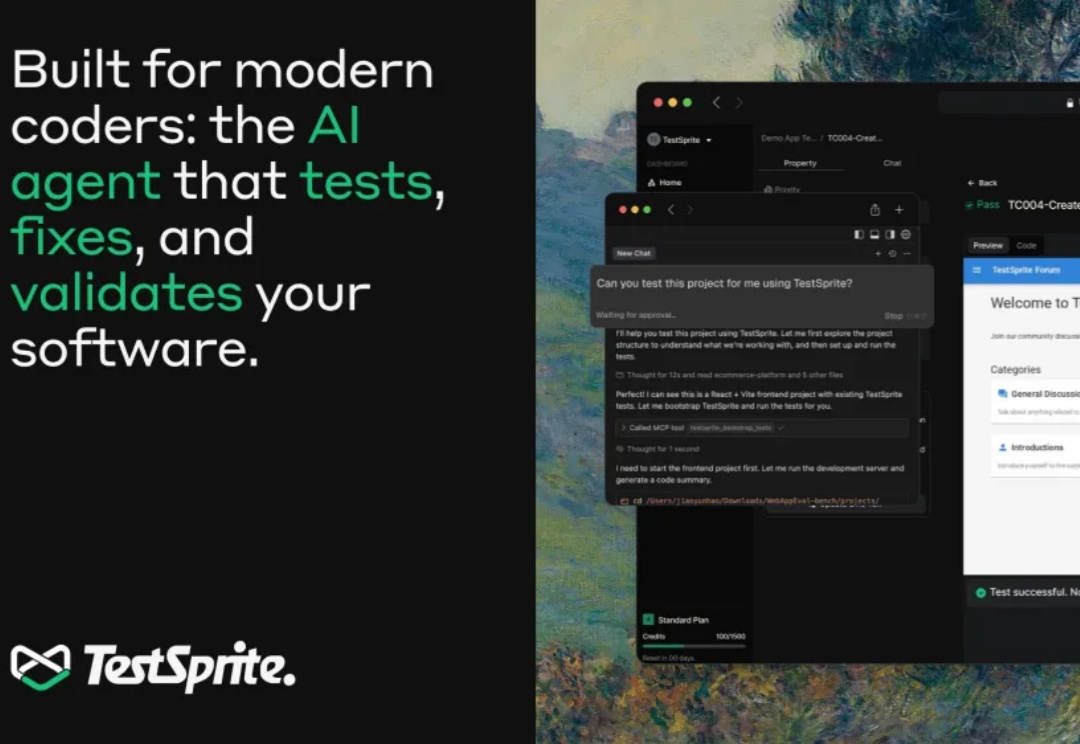
这两年,写代码这件事变了。GitHub Copilot、Cursor、Devin 一路登场,工程师开始习惯“打一段话,几千行代码自己长出来”。写得出东西,变得前所未有地容易。但很快大家发现,真正拖住上线节奏的,不再是「能不能写出来」,而是「敢不敢放上生产环境」——代码量指数级增长,验证、回归、极端场景覆盖反而被彻底压缩,测试成了 AI 时代新的“硬瓶颈”。