比全球最强推理引擎还快2倍,斯坦福、普林斯顿破解大模型「串行魔咒」
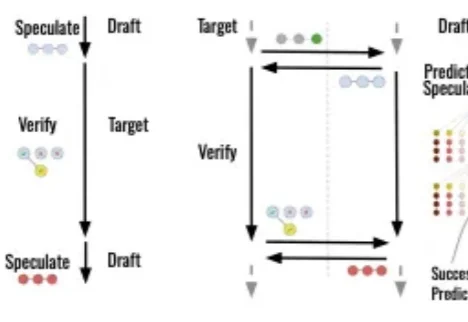
比全球最强推理引擎还快2倍,斯坦福、普林斯顿破解大模型「串行魔咒」在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。
来自主题: AI技术研报
8112 点击 2026-04-01 16:20
 搜索
搜索
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。
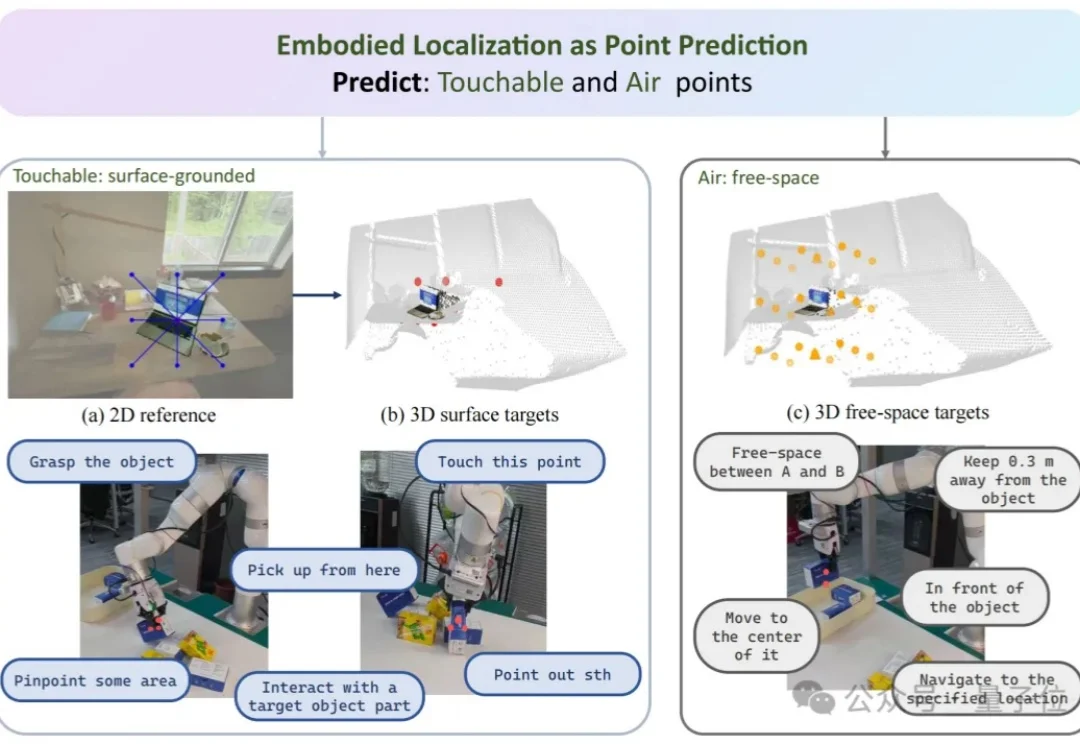
机器人能认出杯子,却看不懂杯口朝哪、离自己多远、该抓哪里。
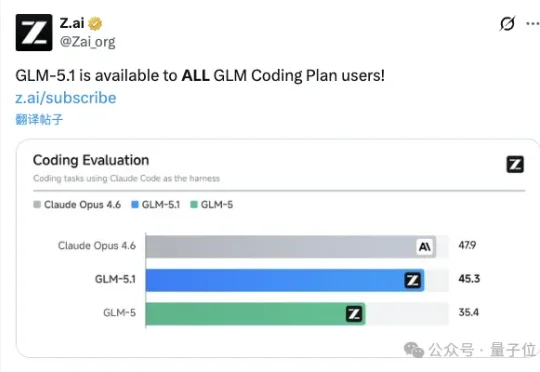
智谱GLM-5.1,突然上线!别的没再多说,只是默默甩出Coding Evaluation评测结果——在编程能力上相比上一代GLM-5直接飙升近10分。甚至嘛,距全球最强编程模型Claude Opus 4.6,也就只有2.6分之差??

据外媒The Information援引知情人士消息透露, Anthropic的高管们已经讨论过最早于今年第四季度进行该公司的IPO(首次公开募股),可能在IPO中筹集超过600亿美元(约合4146.9亿元人民币)的资金。

ACE 的起点,并不是把音乐生成做成一个更轻的娱乐玩具,而是从专业创作工作流里切进去。ACE Studio 2.0 于 2025 年 12 月正式发布,产品形态也从 AI vocal workstation 进一步扩展为 all in one AI music studio,开始把 AI 歌声、乐器、生成、编辑与 DAW 协同整合成一个AI 音乐创作系统。
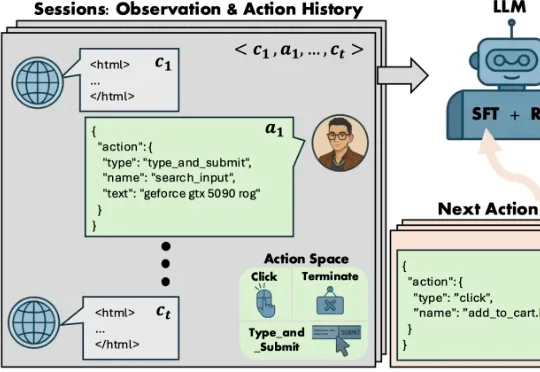
传统的 AI 购物助手更像是一个任务完成机器:接到指令,搜索,下单。他们或许能跑通流程,却完全无法理解用户为何在最后一刻因为一条关于 “夹耳朵” 的差评而放弃支付。简而言之,传统的电商 Agent 只是任务导向的(task-oriented),而不是模拟导向的(simulation-oriented)。为此,来自亚马逊(Amazon)的研究团队提出了名为 Shop-R1 的训练框架 。
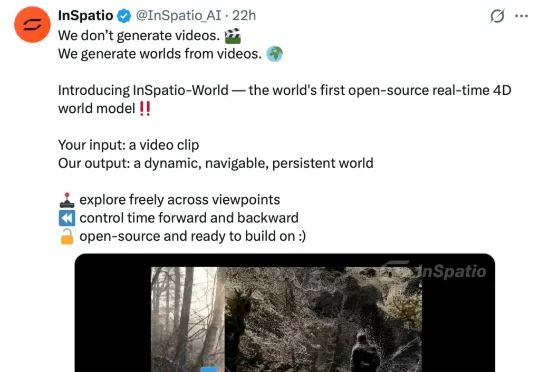
近日,影溯正式发布并开源世界模型 InSpatio-World,综合性能优异,在李飞飞牵头的权威世界模型榜单 WorldScore-Dynamic 中,力压其他实时 / 交互级推理速度的世界模型。它彻底摒弃了烧钱低效的纯 2D 视频路径,凭借更具第一性原理的 3D 空间架构,带来了可实时交互的动态世界。

最近,谷歌 NotebookLM 又出了个好玩好用的小功能:Cinematic Video Overviews(电影级视频概览)。与普通模板不同,这项功能可以根据我们上传的资料,自动生成定制化、沉浸式的视频讲解。

数学家陶哲轩,公开了AI新身份——SAIR Foundation联合创始人。之前,他是举世闻名的数学天才,年少成名的传奇数学家、13岁加冕IMO的最年轻金牌得主……24岁就成为加州大学洛杉矶分校(UCLA)史上最年轻的终身正教授。

一条X,直接引爆了机器人圈:装上OpenClaw的宇树人形机器人,竟开始理解空间与时间!机器人第一次拥有「世界记忆」,能记住人、物体和发生过的事——天网,真的要来了?