
OpenAI联手PE砸下40亿美元,聊聊硅谷最火新职位FDE
OpenAI联手PE砸下40亿美元,聊聊硅谷最火新职位FDE最近硅谷最火的岗位,非FDE莫属。FDE全称“Forward Deployment Engineer”,可以直接翻译成“前线部署工程师”。他们既要懂模型和技术,也要理解客户的数据、流程和业务痛点,核心任务是把AI从demo变成各个职业自己的AI-native工作流。
来自主题: AI资讯
8381 点击 2026-07-01 09:51
 搜索
搜索
最近硅谷最火的岗位,非FDE莫属。FDE全称“Forward Deployment Engineer”,可以直接翻译成“前线部署工程师”。他们既要懂模型和技术,也要理解客户的数据、流程和业务痛点,核心任务是把AI从demo变成各个职业自己的AI-native工作流。

据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。

刚刚,DeepSeek V4 进行了一次更新。新推出了投机解码(Speculative Decoding)框架 DSpark,并同步开源了支撑该版本的全栈推测性解码框架 DeepSpec。DeepSeek-V4-Pro-DSpark 并非全新架构模型,而是在 DeepSeek-V4-Pro 基础上引入了推测性解码模块。此次更新的重点在于工程落地,而非模型能力本身的迭代。

带着这份遗憾与使命,Nico 创立了 AI 医疗平台 Telepatia。近日,该公司正式宣布完成 3300 万美元的 A 轮融资。值得瞩目的是,本轮融资由全球顶级风投巨头 a16z(Andreessen Horowitz)强势领投。
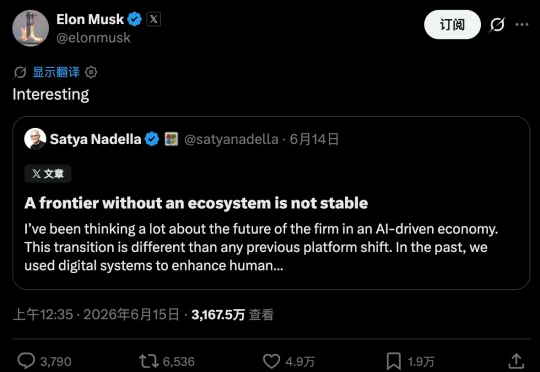
微软CEO 萨蒂亚·纳德拉,上周发的那篇《没有生态的前沿,立不住》(A frontier without an ecosystem is not stable),是近期挺有意思的一篇文章。不在于它提出了多少新概念,里面的很多要点,在近一年里大多已有讨论,而在于说它的不是旁观者,而是亲手运营着庞大 AI 基础设施的人,并且纳德拉用很朴素的语言,把两件非常重要的事情讲清楚了:
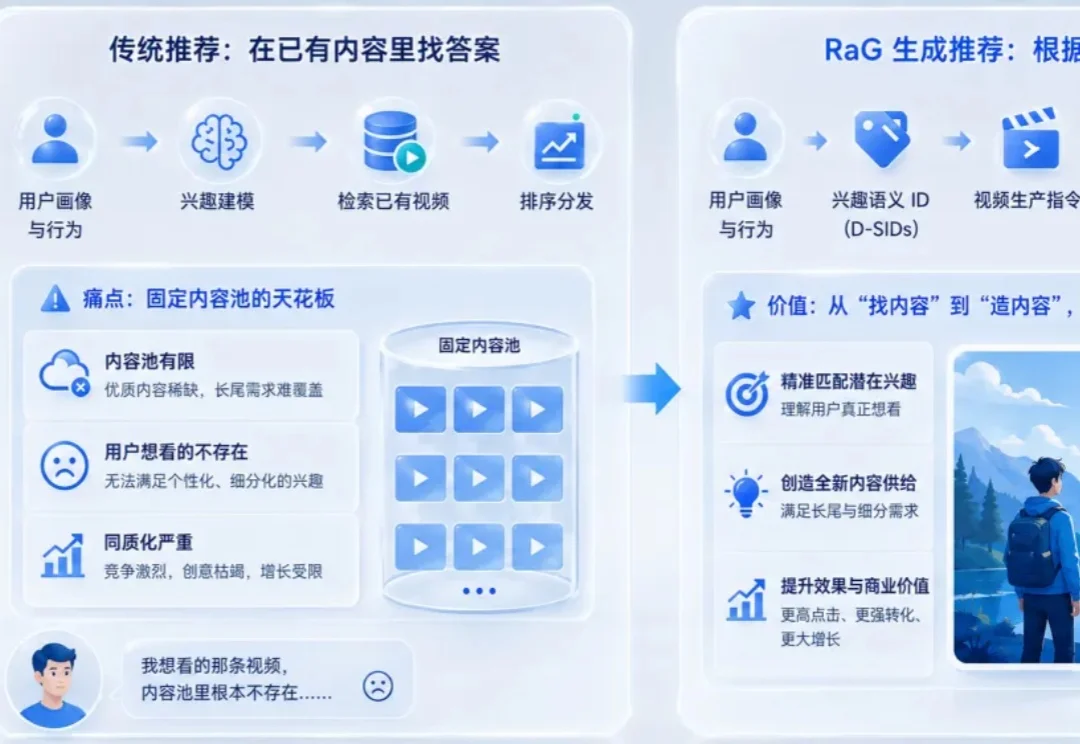
过去十年,推荐系统最核心的动作可以概括成一个字:找。

全球最强超算,易主了!
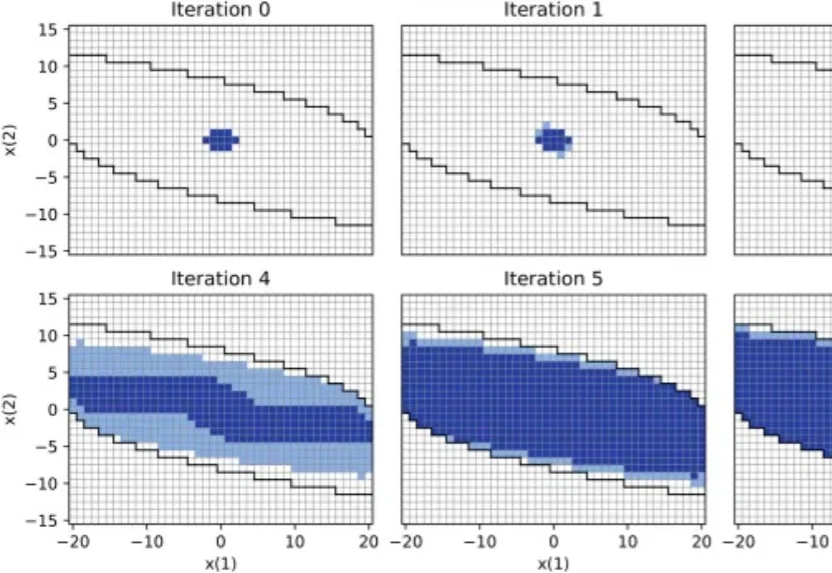
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。

近日,AI-Native科技潮玩品牌ZuzuZoos查无此园宣布完成数千万元Pre-A轮融资,由锦秋基金领投、上海复容投资跟投。这家成立于2025年的初创公司,定位于"AI陪伴机器人+AI潮玩"方向,试图将情感陪伴、AI交互与潮玩IP结合,打造一款会拥抱人的便携式AI伙伴。

如果要评选这轮 AI 狂潮里最魔幻的受益者,TOTO 大概率能拿到一个提名。