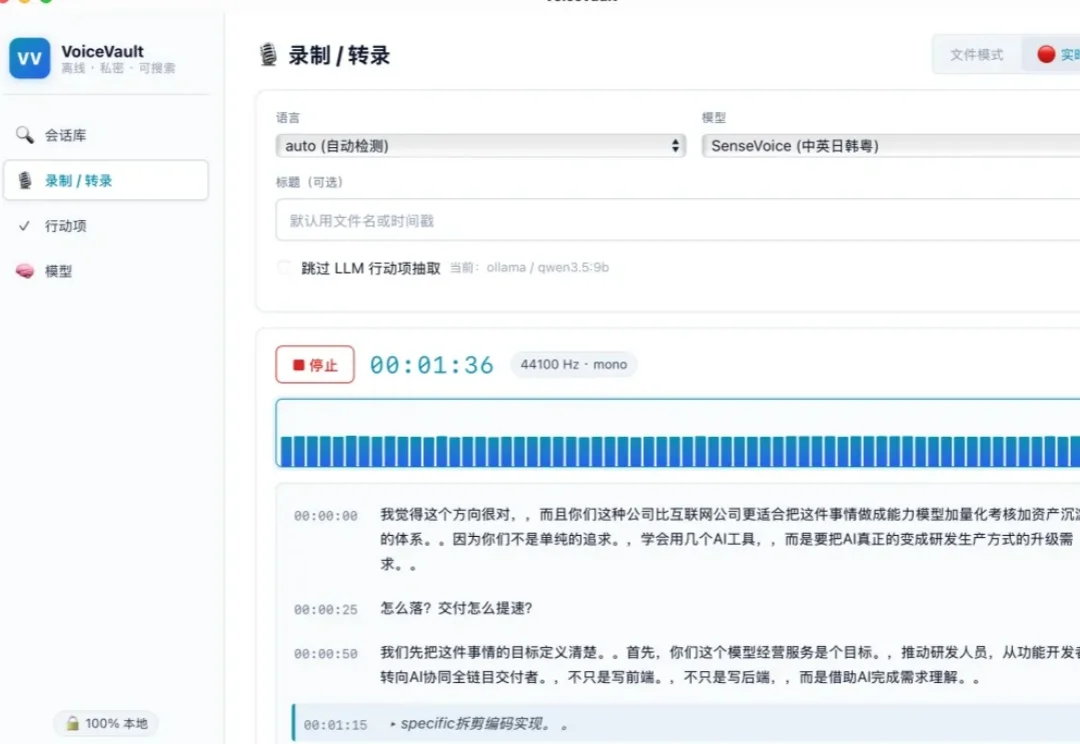
干掉 Whisper:我把 VoiceVault 迁移到 FunASR,本地转录加总结爽的飞起,已然是一枚离线录音加待办神器
干掉 Whisper:我把 VoiceVault 迁移到 FunASR,本地转录加总结爽的飞起,已然是一枚离线录音加待办神器把 VoiceVault 的转录引擎从 Whisper 迁移到 FunASR(sherpa-onnx),中文识别速度提升 3x,不再需要 500MB 的模型文件。但"切个后端"这件听起来很简单的事,让我在 GitHub Release 的 404、Tauri 白屏、trait object 生命周期和 CSP 策略里翻滚了一整天。
来自主题: AI技术研报
5757 点击 2026-06-18 15:28