这套题,GPT-5.5、Opus 4.7加起来没考到「1分」,人类却拿了满分100?
这套题,GPT-5.5、Opus 4.7加起来没考到「1分」,人类却拿了满分100?近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。
来自主题: AI技术研报
9205 点击 2026-05-02 15:00
 搜索
搜索
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。
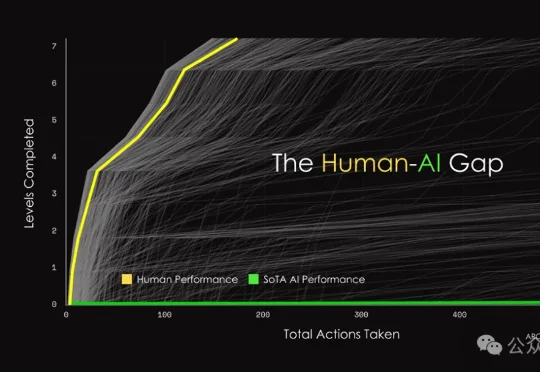
就在昨天,ARC-AGI-3刚把全球顶尖大模型按在地上摩擦,结果一家名不见经传的公司却给出惊天消息:他们的AI在首日就取得了36.08%的成绩!这匹黑马究竟靠什么撕开全球最难AI考试的铁幕?是真突破,还是另有玄机?
今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。

当地时间 2 月 19 日,Google 曝光 Gemini 3.1 Pro 最新模型。在 ARC-AGI-2 这个公认的推理基准测试中,Gemini 3.1 Pro 拿到了 77.1% 的分数。什么概念?它的前辈 Gemini 3 Pro 只有 31.1%,就连专门用来「深度思考」的 Gemini 3 Deep Think 也只有 45.1%。
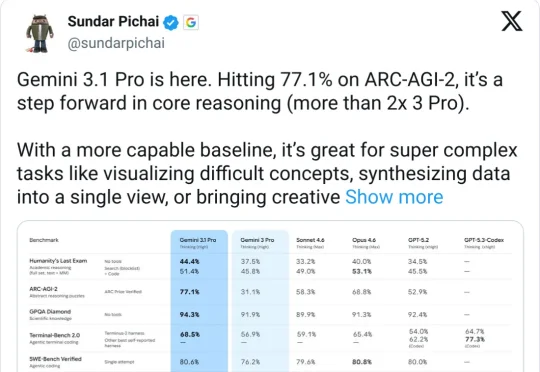
今天凌晨,Google 发布 Gemini 3.1 Pro。核心提升在推理能力,ARC-AGI-2(抽象推理基准)从 3 Pro 的 31.1% 跳到 77.1%,翻了一倍多,GPQA Diamond(科学知识推理)从 91.9% 提到 94.3%
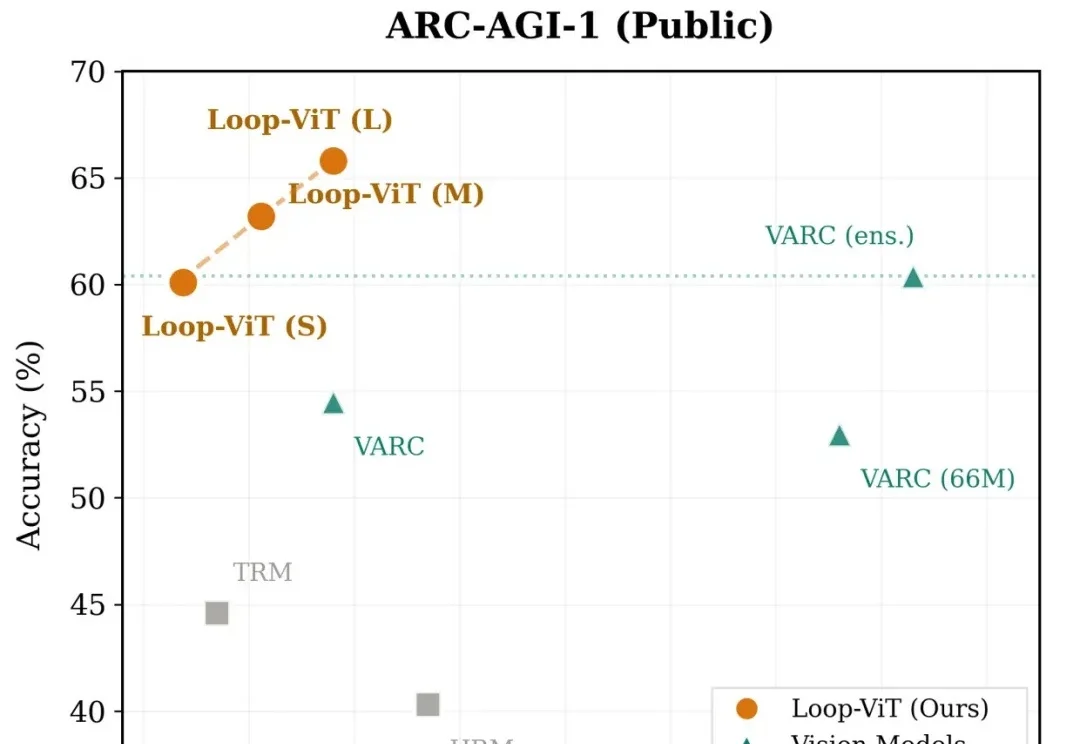
当我们解一道复杂的数学题或观察一幅抽象图案时,大脑往往需要反复思考、逐步推演。然而,当前主流的深度学习模型却走的是「一次通过」的路线——输入数据,经过固定层数的网络,直接输出答案。
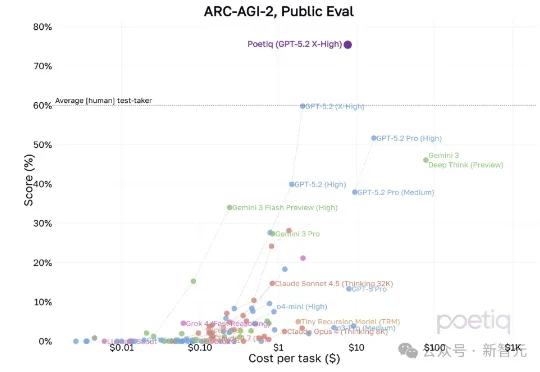
刚刚,GPT-5.2刷新了一项新纪录!OpenAI联合创始人Greg Brockman发帖称使用GPT-5.2在ARC-AGI-2基准测试上,表现超过了人类基线水平。

什么?决定 AI 上限的已不再是底座模型,而是外围的「推理编排」(Orchestration)。
压缩即智能,又有新进展!

6位前DeepMind成员以元系统重塑大模型调用方式,该系统推出的Gemini 3 Pro优化技术在ARC-AGI-2上以54%的成绩夺得榜首,而成本仅为此前最优方法的一半。