
独家 | Robopoet 完成亿元级 Pre-A 轮融资,芙崽开始走向全球化
独家 | Robopoet 完成亿元级 Pre-A 轮融资,芙崽开始走向全球化FounderPark 独家获悉,AI 潮玩品牌珞博智能(Robopoet)宣布于 2026 年初完成亿元级 Pre-A 轮融资。本轮融资新增华映资本、广和通、涂鸦智能三大新股东,同时老股东红杉中国、
来自主题: AI资讯
8956 点击 2026-07-13 10:40
 搜索
搜索
FounderPark 独家获悉,AI 潮玩品牌珞博智能(Robopoet)宣布于 2026 年初完成亿元级 Pre-A 轮融资。本轮融资新增华映资本、广和通、涂鸦智能三大新股东,同时老股东红杉中国、

张咋啦 Zara 应该是中美 AI 圈子里几乎最出名的 Builder 了。

2026年,AI安全终于被推到了台前。
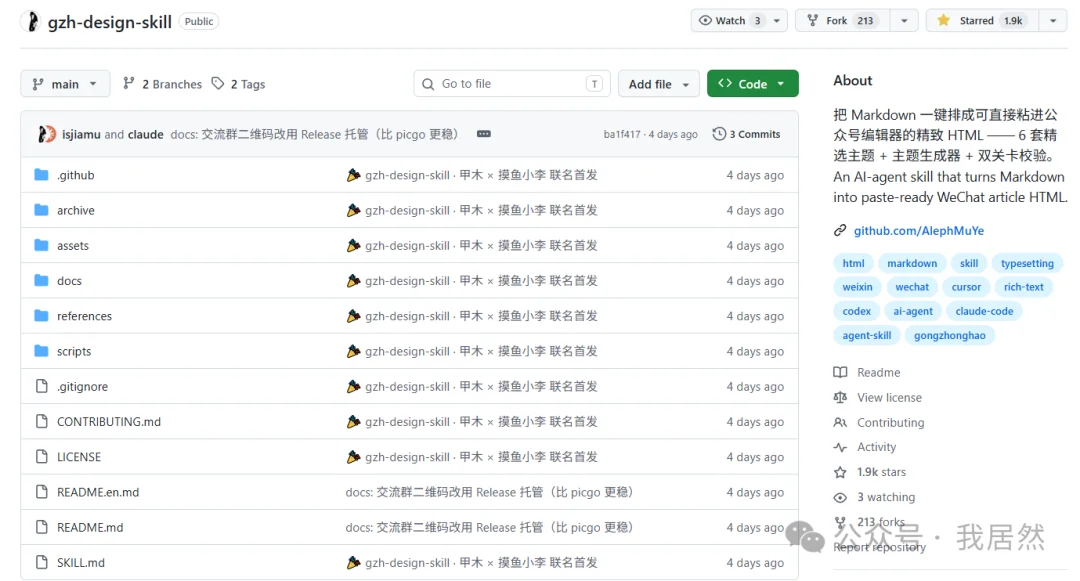
前几天在 github 上有个开源项目非常的火爆,就是 甲木 × 摸鱼小李 大佬联名首发的公众号排版 Skill ,不仅是设计有美感,而且又简约清新,不到几天,就斩获了 1.9k 的 stars
WorkBuddy最近很火,实测下来的体感是,harness层似乎搭建得还不错,而且对国内模型的兼容度都做得很好,少有的国内应用厂商做出来的、基于国产模型的可用Agent产品。 这篇文章来自 Work

就在这届Bilibili World上,英伟达首次面向大众玩家展示了搭载RTX Spark超级芯片的笔记本电脑。这款芯片专为个人智能体打造,不仅搭载了Blackwell RTX GPU,连CPU也是出自英伟达的Grace CPU。
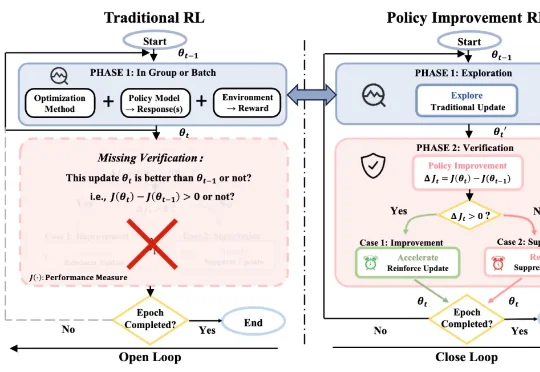
来自北航、北大、美团的研究团队提出了Policy Improvement Reinforcement Learning, PIRL,以及对应的落地算法 PIPO。这项工作关注的是大模型 RL 后训练中一个非常基础、但长期被默认跳过的问题:一次更新在当前数据上看起来优化了学习信号,是否就真的说明模型策略变强了?

研究团队提出了 XG-Guard (eXplainable and fine-Grained safeGuarding framework), 一个基于 GAD 且兼具可解释性和细粒度检测能力的无监督安全防护框架。目前工作已被 ACL 2026 Main Conference 接收。
AI招聘公司Metix AI(原OpenJobs AI)近期完成300万美元的种子+轮融资。本轮融资由Rsquared Investment领投,该公司也是东南亚知名AI招聘平台Bossjob的战略投资方。Metix AI创立于硅谷,致力于用AI技术重塑全球人才招聘流程。其旗舰产品 Mira 是一款能够独立管理企业全周期招聘流程的AI招聘官。

今天 AI 圈的国际头版头条,比往常还要激烈。前有收获不少好评的 Grok-4.5,后有虎视眈眈的 GPT-5.6。结果就在刚刚,Meta 超级智能实验室 (MSI) 杀出, 甩出新模型 Muse Spark 1.1。