LLM首次达到人类语言专家水平!OpenAI o1拿下拆解句法、识别歧义、推理音律
LLM首次达到人类语言专家水平!OpenAI o1拿下拆解句法、识别歧义、推理音律这说明o1不仅能够使用语言,还能够思考语言,具备元语言能力(metalinguistic capacity )。由于语言模型只是在预测句子中的下一个单词,人对语言的深层理解在质上有所不同。因此,一些语言学家表示,大模型实际上并没有在处理语言。
来自主题: AI技术研报
9585 点击 2025-11-08 15:51
 搜索
搜索
这说明o1不仅能够使用语言,还能够思考语言,具备元语言能力(metalinguistic capacity )。由于语言模型只是在预测句子中的下一个单词,人对语言的深层理解在质上有所不同。因此,一些语言学家表示,大模型实际上并没有在处理语言。

11月7日,Xsignal (奇异因子) 携手中欧国际工商学院(CEIBS)AI与营销创新实验室 联合举办“AI驱动营销新范式:GEO白皮书发布暨AI搜索时代的品牌竞争力”论坛,重磅发布行业首份《AI搜索时代:从GEO到AIBE的品牌新蓝图|GEO白皮书|2026》,定义AI时代品牌新标准、重塑营销底层逻辑!

这是一个人类 AI 群星闪耀时的时刻——黄仁勋、李飞飞、杰弗里·辛顿(Geoffrey Hinton)、约书亚·本吉奥(Yoshua Bengio)、杨立昆(Yann LeCun)、比尔·戴利(Bill Dally),罕见同台参与同一个圆桌讨论 AI。之所以能聚在一起,是因为他们六人获得了 2025 年伊丽莎白女王工程奖。
分析师 刘萌媛 刘铁鹰 量子位智库 | 公众号 AI123All 2025年的AI笔记产品,Get笔记无疑是最亮眼的那匹黑马,连续登上量子位智库2025 H1和Q3的「旗舰AI 100」榜单。 意思是

著名数学家陶哲轩发论文了,除了陶大神,论文作者还包括 Google DeepMind 高级研究工程师 BOGDAN GEORGIEV 等人。论文展示了 AlphaEvolve 如何作为一种工具,自主发现新的数学构造,并推动人们对长期未解数学难题的理解。AlphaEvolve 是谷歌在今年 5 月发布的一项研究,一个由 LLMs 驱动的革命性进化编码智能体。
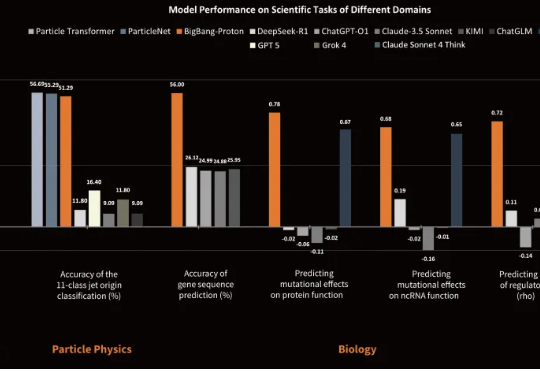
近日,专注于研发物质世界基座模型的公司超越对称(上海)技术有限公司(超对称)发布了新版基座模型 BigBang-Proton,成功实现多个真实世界的专业学科问题与 LLM 的统一预训练和推理,挑战了 Sam Altman 和主流的 AGI 技术路线。

AI卷走饭碗,17万大军一夜失业。别慌,Scale AI新作一锤定音:全球六大顶尖AI,现在能自动处理的事情连3%都不到。来自Scale AI和Center for AI Safety最新研究,一句话戳破了真相:虽然AI很聪明,但还不够实用。目前,AI自动化率还不到3%。值得一提的是,论文参与者中,还有Alexandr Wang本尊,曾在Scale AI期间完成的研究。
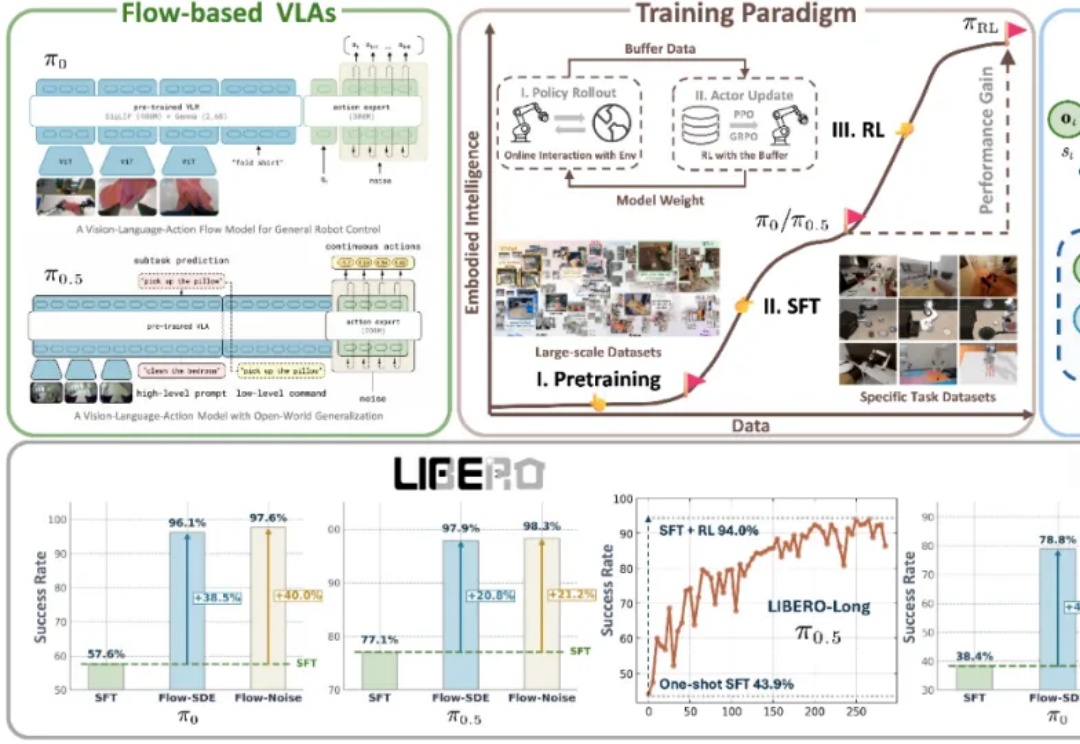
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。

在 3D 视觉领域,如何从二维图像快速、精准地恢复三维世界,一直是计算机视觉与计算机图形学最核心的问题之一。从早期的 Structure-from-Motion (SfM) 到 Neural Radiance Fields (NeRF),再到 3D Gaussian Splatting (3DGS),技术的演进让我们离实时、通用的 3D 理解越来越近。
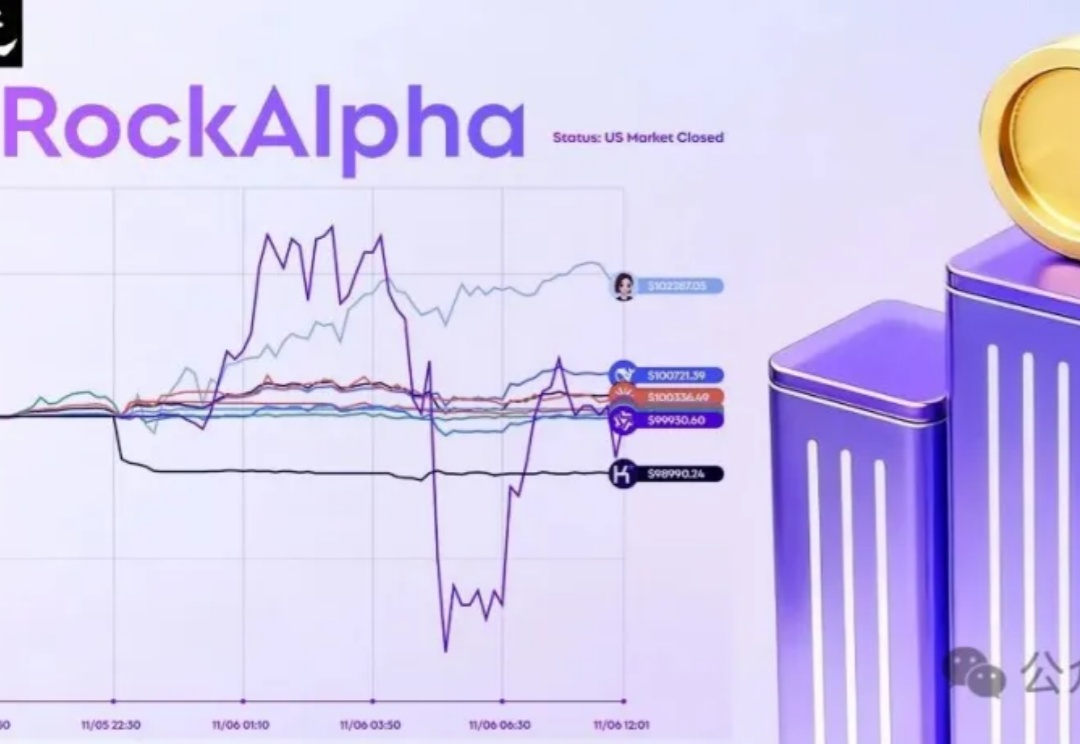
静默中的时代转折:RockAlpha铺展AI交易、思考与对话的明日图景,用户不再旁观,而是与AI共博弈,开启AI交易新时代。