o3通关「俄罗斯方块」,碾压Gemini夺冠!UCSD新基准击碎宝可梦
o3通关「俄罗斯方块」,碾压Gemini夺冠!UCSD新基准击碎宝可梦UCSD等推出Lmgame Bench标准框架,结合多款经典游戏,分模块测评模型的感知、记忆与推理表现。结果显示,不同模型在各游戏中表现迥异,凸显游戏作为AI评估工具的独特价值。
来自主题: AI资讯
8077 点击 2025-07-01 16:15
 搜索
搜索
UCSD等推出Lmgame Bench标准框架,结合多款经典游戏,分模块测评模型的感知、记忆与推理表现。结果显示,不同模型在各游戏中表现迥异,凸显游戏作为AI评估工具的独特价值。
大模型推理,无疑是当下最受热议的科技话题之一。

为什么必须像评估劳动力一样评估LLM代理,而不仅仅是评估软件。
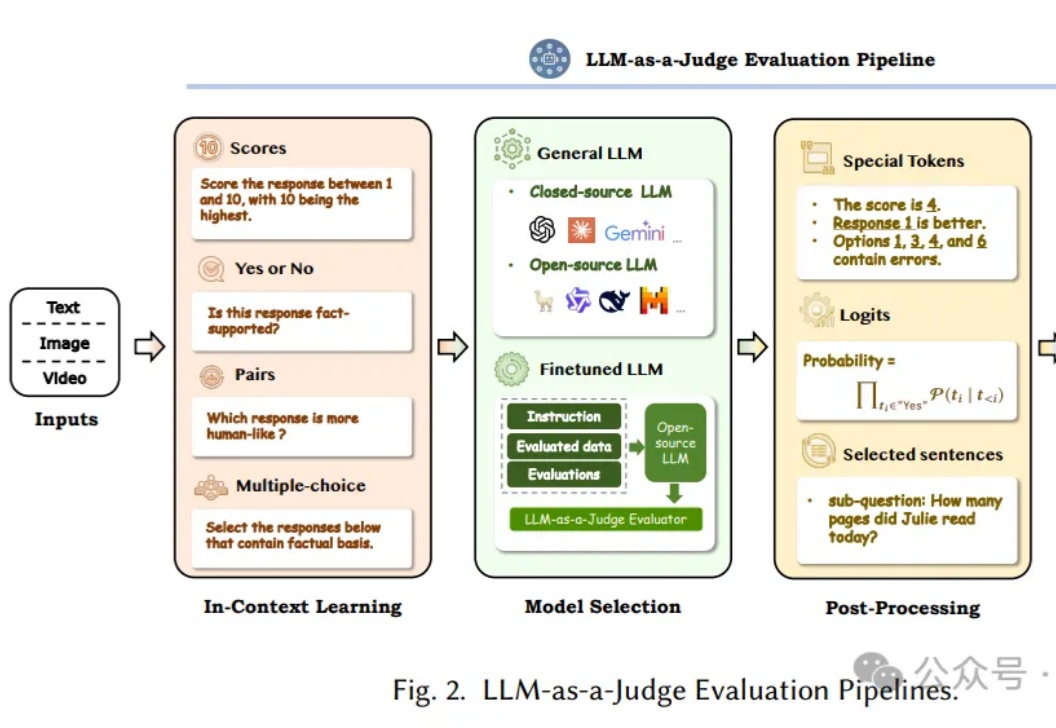
让AI来评判AI,即利用大语言模型(LLM)作为评判者,已经成为近半年的Prompt热点领域。这个方向不仅代表了AI评估领域的重要突破,更为正在开发AI产品的工程师们提供了一个全新的思路。

AI评估AI可靠吗?来自Meta、KAUST团队的最新研究中,提出了Agent-as-a-Judge框架,证实了智能体系统能够以类人的方式评估。它不仅减少97%成本和时间,还提供丰富的中间反馈。

Maitrix.org 是由 UC San Diego, John Hopkins University, CMU, MBZUAI 等学术机构学者组成的开源组织,致力于发展大语言模型 (LLM)、世界模型 (World Model)、智能体模型 (Agent Model) 的技术以构建 AI 驱动的现实。

在AI的世界里,模型的评估往往被看作是最后的「检查点」,但事实上,它应该是确保AI模型适合其目标的基础。
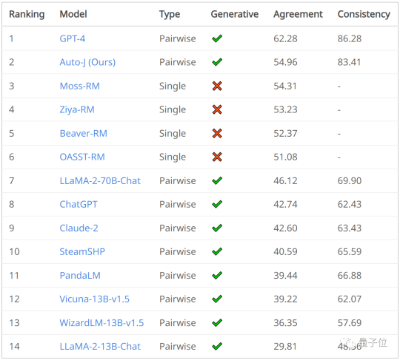
评估大模型对齐表现最高效的方式是?在生成式AI趋势里,让大模型回答和人类价值(意图)一致非常重要,也就是业内常说的对齐(Alignment)。

世界最强AI——ChatGPT可以通过各种考试,甚至输出回答让人难以辨别真假。