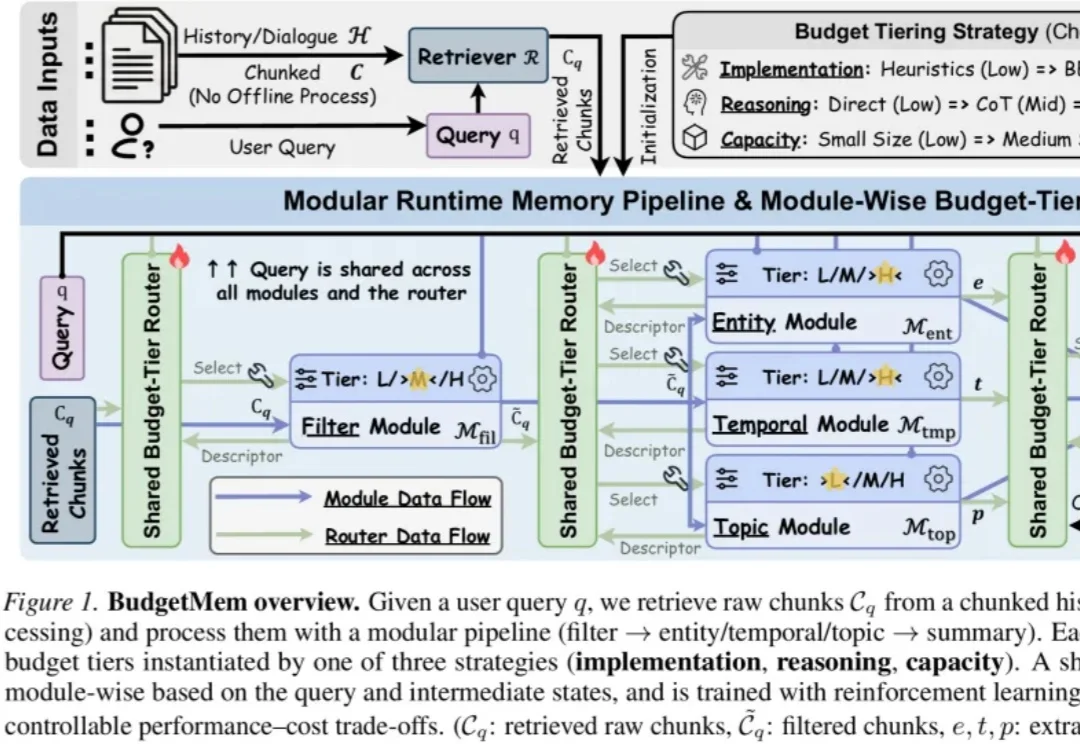
BudgetMem:给Runtime Agent Memory装上「预算路由器」,让记忆系统学会按需分配运行成本
BudgetMem:给Runtime Agent Memory装上「预算路由器」,让记忆系统学会按需分配运行成本当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。
来自主题: AI技术研报
8961 点击 2026-06-15 09:20
 搜索
搜索
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。

多模态长记忆在“看得准、找得到、想得清”三大环节的底层逻辑与工程避坑指南。

奥特曼官宣ChatGPT记忆重大升级!全新Dreaming V3架构正式上线:ChatGPT会在后台「做梦」,首次向数亿免费用户开放。这一次升级,「做梦」功能向十亿人免费开放,Plus和Pro记忆容量直接翻倍。
今天起,ChatGPT 的记忆系统更像人了。OpenAI 刚刚推出了一套全新的记忆系统,底层基于 Dreaming 技术。它会在长期对话中自动整理你的偏好、项目、设备、旅行计划和生活安排,并在回答时判断哪些信息仍然有用,哪些已经过时。

过去半年,几乎所有Agent框架都在补长期记忆能力。最常见的做法,是给系统接一个向量数据库,把历史对话、用户偏好、项目经验、工具调用结果、失败案例都存进去。看起来,只要把“记忆”这块补上,Agent就能从一次性对话工具变成长期协作伙伴。

博尔赫斯笔下有个记住一切的人,21 岁被记忆压到窒息而死。尼采说没有遗忘就不可能活下去。现在,数亿人每天使用的 AI 助手正在获得完美记忆,而这个能力的真正代价,可能是人类翻篇的自由。
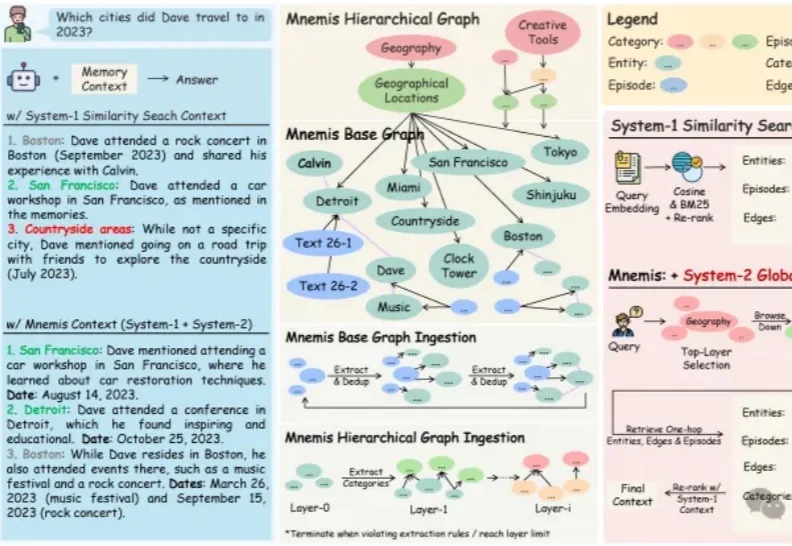
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。

你是否在使用Agent工作或者写代码时,总感觉上下文不够用?或者感觉反复使用Agent时并没有变得更聪明?感觉目前的记忆方案仍然不够用?今日,香港中文大学联合浙江大学发布的一篇论文关注了这个问题,并引起了学术界广泛讨论:你以为Agent在「记忆」,其实只是在记备忘录。
TencentDB Agent Memory 全球正式开源

EverMind 想做点不一样的。这家由盛大集团孵化的公司,定位是为所有AI Agent提供一个通用的"记忆层"(Memory Layer)。它的核心产品EverOS是一套开源的长期记忆系统,开发者可以把它接入自己的Agent,让AI不仅能记住用户的历史对话和偏好,还能像人一样对记忆进行整理、更新,甚至从过去的经验中学习和进化。