
跨越落地鸿沟!清华长三院发布首个真实场景AI竞技场,实战谁是最佳?
跨越落地鸿沟!清华长三院发布首个真实场景AI竞技场,实战谁是最佳?攻克AI落地难题,清华团队推出RWAI框架与真实场景竞技场,通过标准化人机交互、任务集机制与人类反馈体系,显著提升产业应用效率。平台已实现落地周期缩短70%以上,并为AI开发者和企业提供了可复制的最佳实践。
来自主题: AI技术研报
6841 点击 2026-05-20 09:52
 搜索
搜索
攻克AI落地难题,清华团队推出RWAI框架与真实场景竞技场,通过标准化人机交互、任务集机制与人类反馈体系,显著提升产业应用效率。平台已实现落地周期缩短70%以上,并为AI开发者和企业提供了可复制的最佳实践。

AI竞技场开始清场。

数据在AI时代的重要性已经不言而喻,但悬而未决的是—— 如何精确量化这些数据的价值、辨别其优劣? 为此,上海人工智能实验室OpenDataLab团队在数据领域持续深耕,正式推出了开放数据竞技场OpenDataArena。

AI模型排行榜分两类:以高考式标准化测试衡量特定能力的客观基准测试(如AAII、MMLU-Pro),以及用户匿名盲测、根据偏好对答案投票排名的人类偏好竞技场(如LMArena)。两者各有优劣和局限性,且排行榜本质是门生意。用户应基于实际需求而非榜单名次选择模型,实用性至上。

单个模型的优缺点也能分析
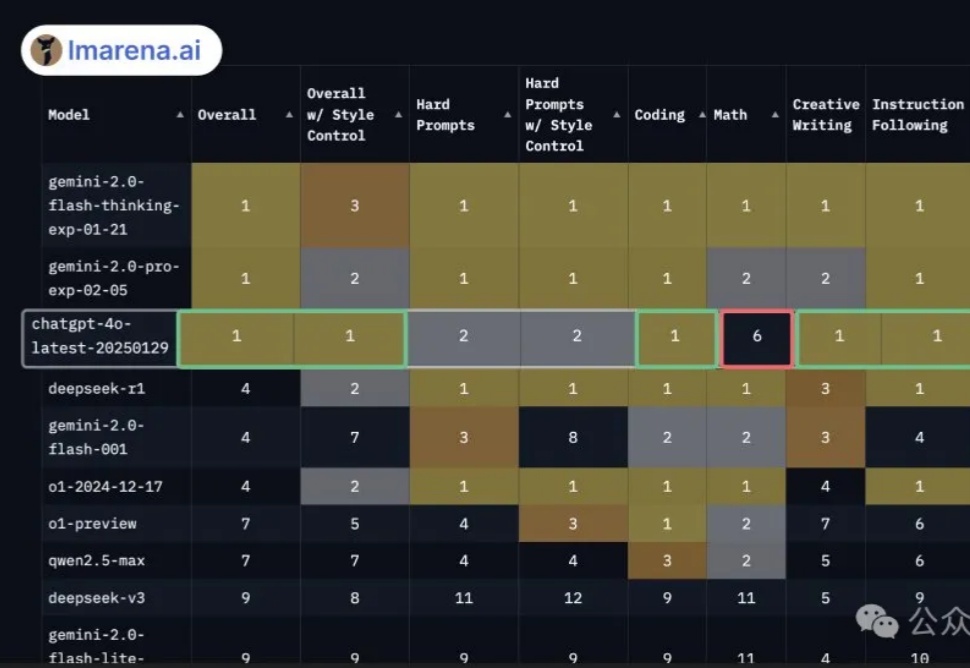
GPT-4o悄悄更新版本,在大模型竞技场超越DeepSeek-R1登上并列第一。
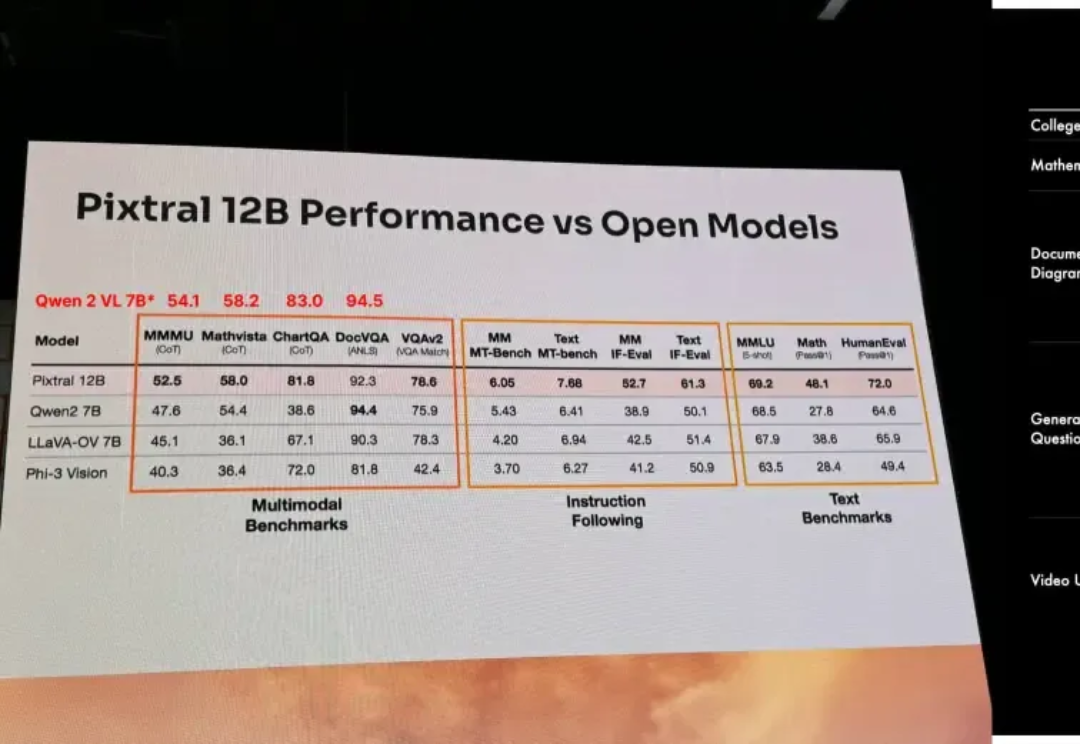
以开源极客之姿杀入江湖的Mistral AI,在9月份甩出了自家的首款多模态大模型Pixtral 12B,如今,报告之期已至,技术细节全公开。

未来的 AI 模型的能力将不仅局限于逻辑推理,它还应该具备自主计划和行动的能力。

奥运会不仅见证了人类挑战物理极限的精神,也见证了人类挑战技术极限的努力。

字节跳动的扣子(coze.cn),给国产大模型们组了个大局—— 在同一个“擂台”上,两个大模型为一组,直接以匿名的方式PK效果!