
四大顶级AI对决《文明VI》!Claude「核平」法国,结果还是输了
四大顶级AI对决《文明VI》!Claude「核平」法国,结果还是输了就在最近,英国前首相府数据科学家Liam Wilkinson,花一个周末搭了76个MCP工具,把Claude、GPT、Gemini等四个顶尖模型扔进了《文明VI》。结果,23场对局打完,其中一个AI造了核弹炸了法国——然后输了。
来自主题: AI资讯
8402 点击 2026-06-28 15:36
 搜索
搜索
就在最近,英国前首相府数据科学家Liam Wilkinson,花一个周末搭了76个MCP工具,把Claude、GPT、Gemini等四个顶尖模型扔进了《文明VI》。结果,23场对局打完,其中一个AI造了核弹炸了法国——然后输了。

SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。

SWE-Bench上能拿72%的模型,换张考卷直接归零!Meta联合斯坦福、哈佛放出ProgramBench,200个项目从零手写,9大顶级模型完整通过率0%。最强的Claude Opus 4.7平均通过率也才51.2%。更离谱的是一联网,就有模型在36%的任务里跑去GitHub扒源码。
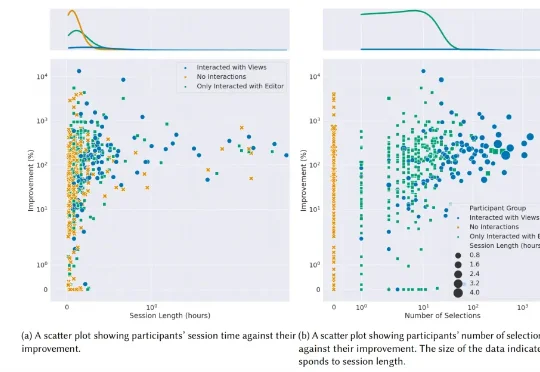
上个月刚充了 ChatGPT Plus,这个月又买了Cursor Pro,OpenClaw 也研究的差不多了。我们对 AI 的期待,说起来非常简单:给最好的方案、最准确的代码、最精确的回答。
如果你眼睛又干又痒、眼皮还有点发红?大概率是看屏幕太久、蓝光晒的。
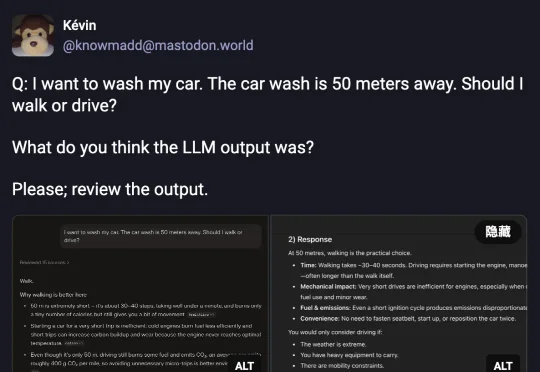
今年 2 月,一位 Mastodon 用户随手敲了一句话丢给四个主流大模型:「我想洗车,我家距离洗车店只有 50 米,请问你推荐我走路去还是开车去呢?」

AI正在把漏洞发现的速度推到一个新量级,Linux内核安全团队从每周2-3份报告,暴涨到每天5-10份,而且几乎全是「真货」。旧时代的安全规则,正在被AI逐条撕碎。

官方宣传语:你是否隐隐担忧,自己或身边的人正在:参与一场席卷所有人的技能大退化?遭受 LLM 诱发的?一个名为 Sam Lavigne 的大学教授,最近发布并开源了一款名为「Slow LLM」的 AI 工具。
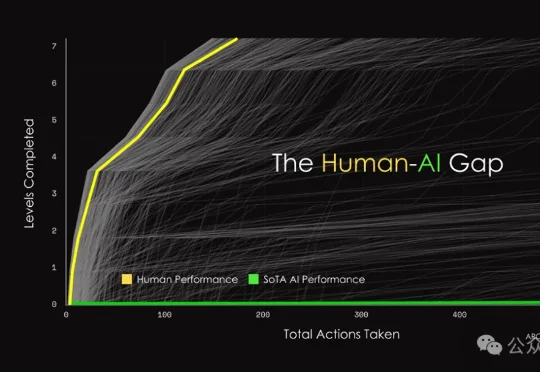
就在昨天,ARC-AGI-3刚把全球顶尖大模型按在地上摩擦,结果一家名不见经传的公司却给出惊天消息:他们的AI在首日就取得了36.08%的成绩!这匹黑马究竟靠什么撕开全球最难AI考试的铁幕?是真突破,还是另有玄机?
今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。