写代码不用编辑器!Transformer八子之一:单卡5090复刻Transformer所有研究!AI耗尽万亿Token学概念,正在用“外星人逻辑”泛化
写代码不用编辑器!Transformer八子之一:单卡5090复刻Transformer所有研究!AI耗尽万亿Token学概念,正在用“外星人逻辑”泛化“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”
来自主题: AI资讯
7258 点击 2026-06-05 09:53
 搜索
搜索
“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”
一个有灵魂,有记忆的 Agent,一次任务的生命周期包括以下步骤

80分钟的拳击式辩论!Transformer联合发明人亲自下场为自己的作品辩护,对面三位挑战者直指五大死穴。这是AI架构十年来最硬的一次正面交锋。统治AI黄金十年的架构,地基是不是已经松了?

就在今天,阿里巴巴集团 CEO 吴泳铭发布全员信,宣布对集团 AI 相关业务进行大刀阔斧的调整。内部信显示,李飞飞出任阿里云 CTO,通义实验室升级为独立事业部,同时成立集团技术委员会统一统筹 AI 技术布局。作为阿里技术体系的核心老将,李飞飞此前主导了阿里云多个核心技术项目

Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。

终结Transformer的架构即将诞生!奥特曼最新访谈豪言,下一代AI架构彻底颠覆Transformer,LSTM的命运或将再次上演。

最近AI圈又多了一张硬核通行证,Anthropic刚刚在官网发布了Claude首个AI架构师认证。

最近的 Meta 可谓大动作不断,一边疯狂裁人,一边又高强度产出论文。

Transformer之父「叛逃」?8年前掀起AI革命的男人,如今嫌「自己孩子」太吵太卷!当资本狂飙、论文堆积如山,他却高喊:是时候放弃Transformer,重新找回好奇心了。
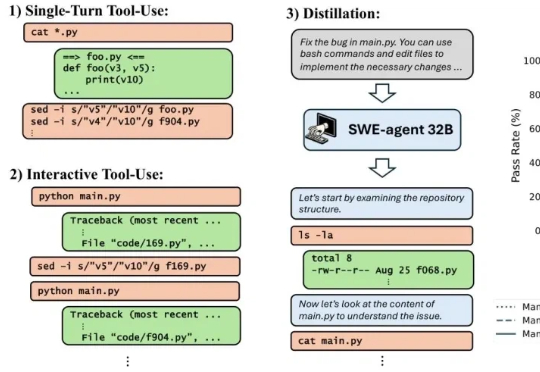
都说苹果AI慢半拍,没想到新研究直接在Transformer头上动土。(doge) 「Mamba+工具」,在Agent场景更能打!