
Loop世界模型论文登顶Hugging Face,来自中国一家初创,周鸿祎陆奇都投了
Loop世界模型论文登顶Hugging Face,来自中国一家初创,周鸿祎陆奇都投了Prompt还没退场,Loop已经开始接管AI叙事。
来自主题: AI资讯
8258 点击 2026-07-01 15:42
 搜索
搜索
Prompt还没退场,Loop已经开始接管AI叙事。

在世界模型这条路上,行业一直卡在一个几乎无解的矛盾里:想要更真实的长程模拟,就必须给模型更深的计算;可一旦把模型做得更深,部署成本、参数规模和误差累积又会迅速抬头。结果就是,大家都知道世界模型要 “想得更久”,却很难让它在现实系统里 “算得起、跑得稳”。
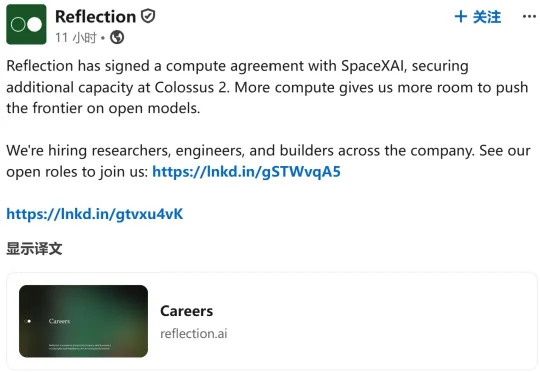
昨晚,美国开源AI初创公司Reflection AI宣布,已与SpaceXAI签署算力协议,将获得Colossus 2数据中心的额外算力支持,用于训练和迭代更强的开放模型。另据TechCrunch报道,Reflection AI将从2026年7月1日起,每月支付1.5亿美元(约合人民币10.2亿元),
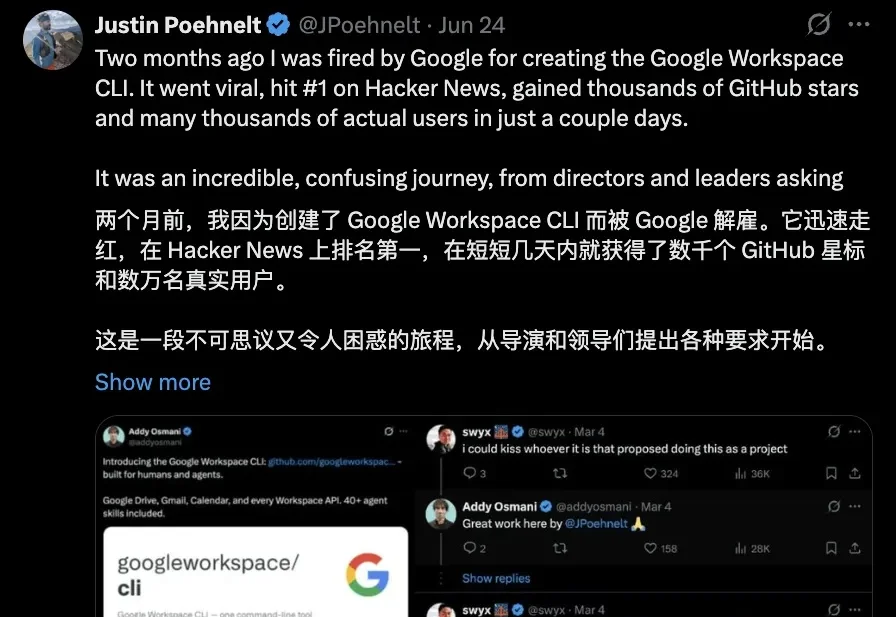
谷歌老兵干了七年,结果因为写了个2.8万星的CLI工具,人被开了。
什么?就因为做出了一个谷歌用户真正想要的工具,谷歌解雇了自家一位工程师。

据悉,AI 推理芯片公司上海淬思科技有限公司(Trace Intelligence,以下简称“淬思”)近日完成孵化轮融资,砺思资本(Monolith)与启盈同创基金联合领投。本轮资金将用于首款面向智能体(Agent)推理的专用芯片研发与流片,以及核心团队扩充。

昨夜,全球最大的 AI 开源社区 Hugging Face 官宣了一项前所未有的决定:自掏腰包为智谱 AI 最新开源的旗舰模型 GLM-5.2 提供长达 6 小时的全球免费算力支持。这是 Hugging Face 第一次真金白银为国产模型开这种 “专属 VIP 通道”,海外网友纷纷直呼这波 “倒贴” 好!

刚刚被 SpaceX 宣布以 600 亿美元收购的 Cursor,发布大模型了。本周二,Cursor 宣布了一个新的 1.5 万亿 + 参数模型,该模型在超过 10 万块 GPU 上进行了预训练。消息是在旧金山举行的 Cursor Compile 上宣布的,这是 Cursor 举办的首届旗舰大会。
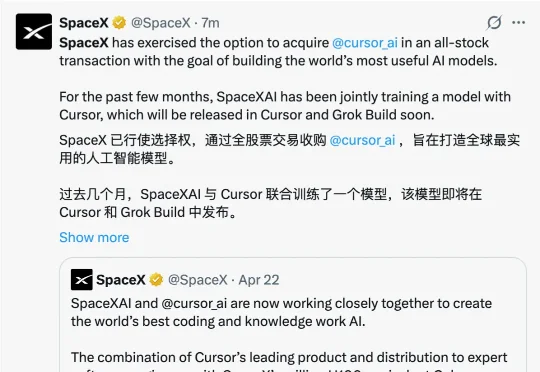
刚刚爆出,马斯克的SpaceX宣布以600亿美元收购Cursor母公司Anysphere,全股票交易,Cursor将成为SpaceX的全资子公司。SpaceX 和 Curosr创始人Truell同一时间在X上官宣。
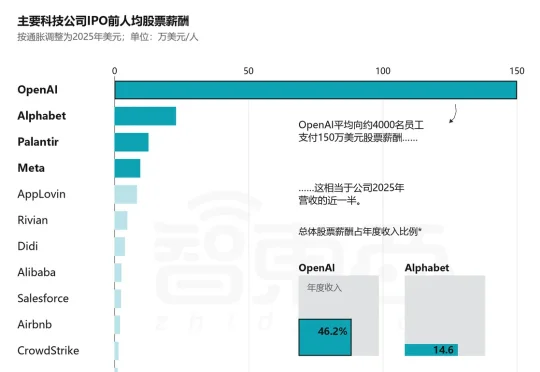
据外媒The Information昨日报道,过去5年间,OpenAI和Anthropic的早期员工及投资者已通过私下股份出售合计套现约140亿美元(约合人民币950亿元)。这一轮员工造富潮正值AI行业IPO竞赛全面升温。6月12日,SpaceX以1.75万亿美元估值登陆纳斯达克,成为这波超级IPO潮中第一个落地的案例。而在此之前,SpaceX至少已连续5年安排员工减持。