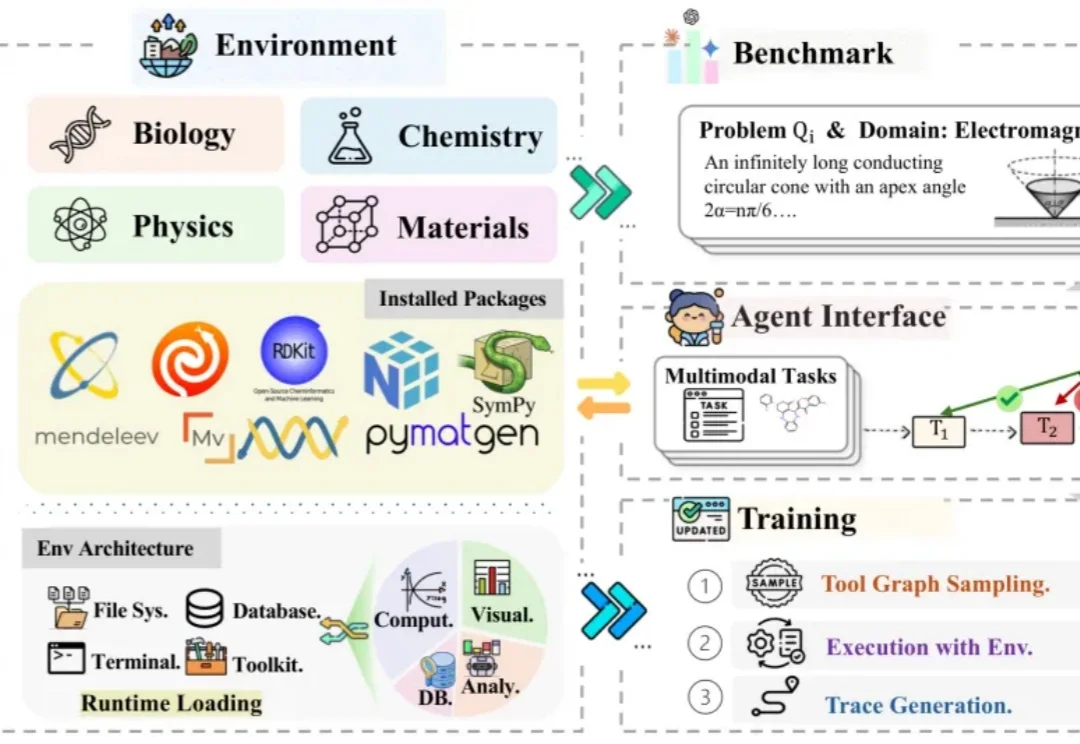
从答题到做实验:SciAgentGym让大模型进入科学工作流
从答题到做实验:SciAgentGym让大模型进入科学工作流DeepMind 联合创始人、2024 年诺贝尔化学奖得主 Demis Hassabis 曾谈到,他一直将 AI 视为推动知识前沿的重要工具。AI 可以帮助科学家处理复杂数据、发现隐藏模式,也可能在未来参与更深层的科学探索。
来自主题: AI技术研报
5506 点击 2026-07-02 10:35
 搜索
搜索
DeepMind 联合创始人、2024 年诺贝尔化学奖得主 Demis Hassabis 曾谈到,他一直将 AI 视为推动知识前沿的重要工具。AI 可以帮助科学家处理复杂数据、发现隐藏模式,也可能在未来参与更深层的科学探索。

走在风口浪尖,拥抱最新的技术。
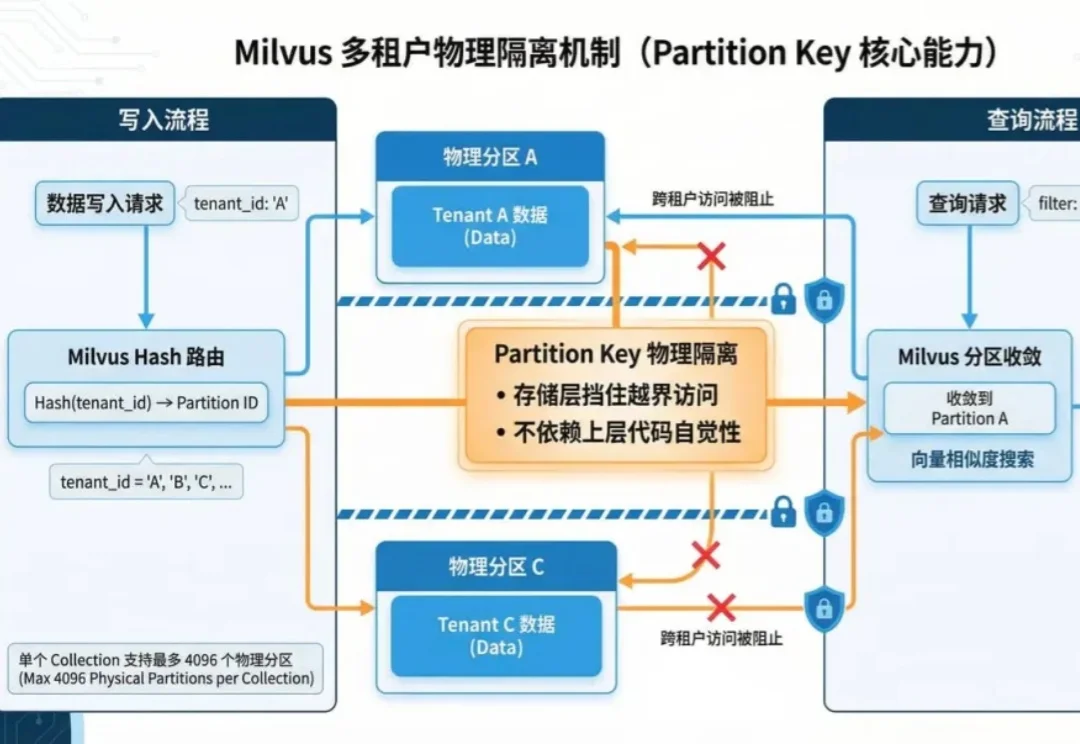
多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。

OpenAI首席研究官Mark Chen释放了一个强烈信号:OpenAI 并不认为scaling laws已经失效,恰恰相反,预训练、数据工程、推理训练和更长任务链条,仍是通向AGI的主干道路。

刚刚,Anthropic正式官宣:Fable 5回来了!就这简单的一句话,让全网奔走相告。苦等19天,所有人像过年一样冲回Claude,就为了亲眼确认那个熟悉的名字重新亮起。而且千万注意,一旦额度达上限,Fable 5跑起来的Token消耗远超Opus 4.8。

《南华早报》援引知情人士消息称,快手旗下视频生成业务“可灵AI”将完成一轮30亿美元(约合人民币203.8亿元)融资,投后估值将达到180亿美元(约合人民币1223亿元),较今年4月最初设定的200亿美元目标估值缩水20亿美元。腾讯参与了可灵AI本轮融资。

这两天codex虽然疯狂额度重置,但几乎可以确定它被降智了。 平时十几分钟能搞定的活,来来回回折腾。网友们整的一个专门监测codex智商的雷达站,曲线也明显往下掉。
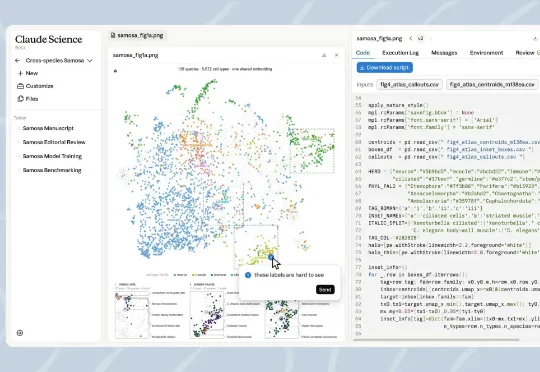
6月30日晚,AI龙头Anthropic推出了专为科学研究打造的新产品Claude Science,这是一款类似于编程工具Claude Code的AI工作台。简单来说,Claude Science是一套专门为科研需求打造的多智能体架构,能自动生成多个子代理并分配他们进行科研任务。
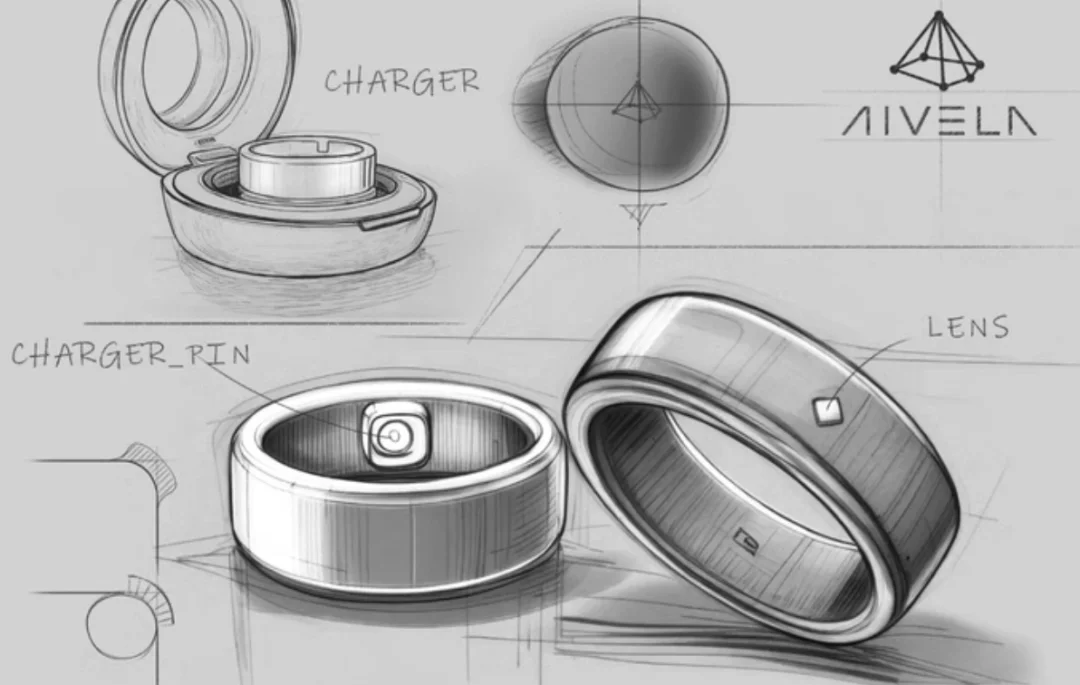
AIVELA 创始人李东豪北大元培毕业,康奈尔大学硕士,学生物出身,此前是电动自行车 Urtopia 的联合创始人。他告诉极客公园,决定 solo 智能戒指项目的原因是,「纯粹个人爱好,不想花公司钱」。于是,2024 年五六月份,李东豪一个人用业余时间开始了这个项目。

大模型公司在港股热度正酣,现在,卖Token的公司也开始冲刺了。硅基流动已向港交所提交上市申请,剑指港股「AI Token工厂第一股」。此前,硅基流动已完成7轮融资,估值77.4亿元。阿里、美团、商汤、蔚来、智谱等产业方和明星AI投资机构均有押注。