

奥特曼和量子计算奠基人讨论GPT-8
奥特曼和量子计算奠基人讨论GPT-8老天奶,奥特曼对GPT的谈论,都跨越好几代来到GPT-8了!最近他在一档节目上,和量子计算奠基人戴维・多伊奇(David Deutsch)展开对话,针对两人存在分歧的“AI能否发展为具备意识的超级智能”议题,奥特曼搬出GPT-8来试图说服多伊奇:
来自主题: AI资讯
9320 点击 2025-09-28 11:45
老天奶,奥特曼对GPT的谈论,都跨越好几代来到GPT-8了!最近他在一档节目上,和量子计算奠基人戴维・多伊奇(David Deutsch)展开对话,针对两人存在分歧的“AI能否发展为具备意识的超级智能”议题,奥特曼搬出GPT-8来试图说服多伊奇:
明星创业公司Thinking Machines,第二篇研究论文热乎出炉!公司创始人、OpenAI前CTO Mira Murati依旧亲自站台,翁荔等一众大佬也纷纷转发支持:论文主题为“Modular Manifolds”,通过让整个网络的不同层/模块在统一框架下进行约束和优化,来提升训练的稳定性和效率。
最近,一家叫 Numeral 的公司刚刚完成了 3500 万美元的 B 轮融资,由 Mayfield 领投,Benchmark、Uncork Capital、Y Combinator 和 Mantis 参与。这轮融资距离他们今年 3 月完成的 1800 万美元 A 轮仅仅过去了 6 个月,公司估值已经达到 3.5 亿美元。
在大模型训练时,如何管理权重、避免数值爆炸与丢失?Thinking Machines Lab 的新研究「模块流形」提出了一种新范式,它将传统「救火式」的数值修正,转变为「预防式」的约束优化,为更好地训练大模型提供了全新思路。
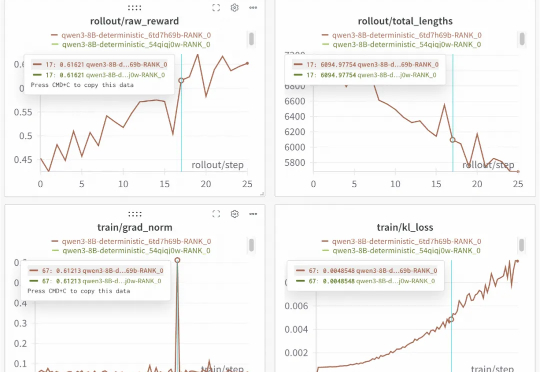
开源框架实现100%可复现的稳定RL训练!下图是基于Qwen3-8B进行的重复实验。两次运行,一条曲线,实现了结果的完美重合,为需要高精度复现的实验场景提供了可靠保障。这就是SGLang团队联合slime团队的最新开源成果。

来自德国癌症研究中心(DKFZ)、欧洲分子生物学实验室(EMBL)、哥本哈根大学等机构的研究团队开发了一款名为Delphi-2M的AI医疗大模型。该模型能通过分析用户的医疗记录和生活方式,并提供长达了20年,覆盖癌症、皮肤病和免疫疾病等1258种疾病的风险估计。

一家仅成立9个月的新公司——奇妙拉比MarveLab,在2025年8月推出的首款AI潮玩RAGUS&WHITE,凭借超过5000单的预售成绩,超200万的首发营收,迅速成为行业内的讨论热点。
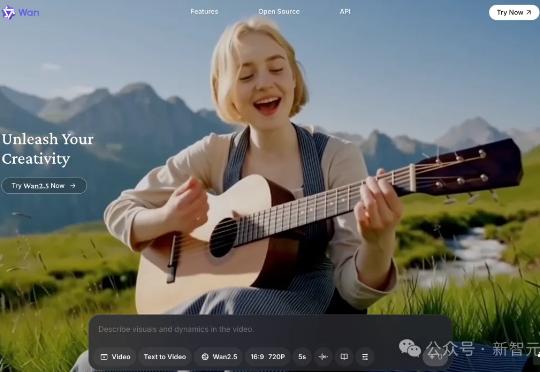
Veo 3真正对手,竟不是Sora 2!通义万相2.5全网首发,直接甩出王炸:一句话,直出10秒1080P电影级视频,首次实现音画精准同步。一键生成BGM、人声,全网实测玩疯。

AGI解放80%日常工作,ASI创造超级科学家——阿里巴巴首次公开ASI蓝图,通义千问家族模型性能飙升,超越GPT-5,开启全模态智能时代。

今年8月的一场小型AI应用内部会议上,近九成与会AI应用企业表示,已制定或正在推进出海计划。这些公司来自多个AI应用赛道,如AI玩具、AI眼镜、AI编程、AI影视、跨境电商、具身智能以及AI游戏等。