
OpenAI融资70亿,只剩孤家寡人?众人怒揭奥特曼真面目!
OpenAI融资70亿,只剩孤家寡人?众人怒揭奥特曼真面目!OpenAI CEO奥特曼,墙倒众人推? 惊人的高管离职潮,令外界对OpenAI的信任降至谷底—— 如果技术真的接近AGI,如果奥特曼真的是位好领导,眼看着公司就要变成「非营利」,他们怎么可能舍得走? 面对外界质疑,奥特曼急忙澄清:自己绝对没有拿7%的股份!
来自主题: AI资讯
5231 点击 2024-09-29 15:01
 搜索
搜索
OpenAI CEO奥特曼,墙倒众人推? 惊人的高管离职潮,令外界对OpenAI的信任降至谷底—— 如果技术真的接近AGI,如果奥特曼真的是位好领导,眼看着公司就要变成「非营利」,他们怎么可能舍得走? 面对外界质疑,奥特曼急忙澄清:自己绝对没有拿7%的股份!

《纽约时报》今天披露了很多关于 OpenAI 有意思的数据,根据其查阅的财务文件显示,OpenAI 8 月份的月收入达到 3 亿美元,自 2023 年初以来增长了 1700%,预计今年的年销售额约为 37 亿美元,而明年营收将增至 116 亿美元。
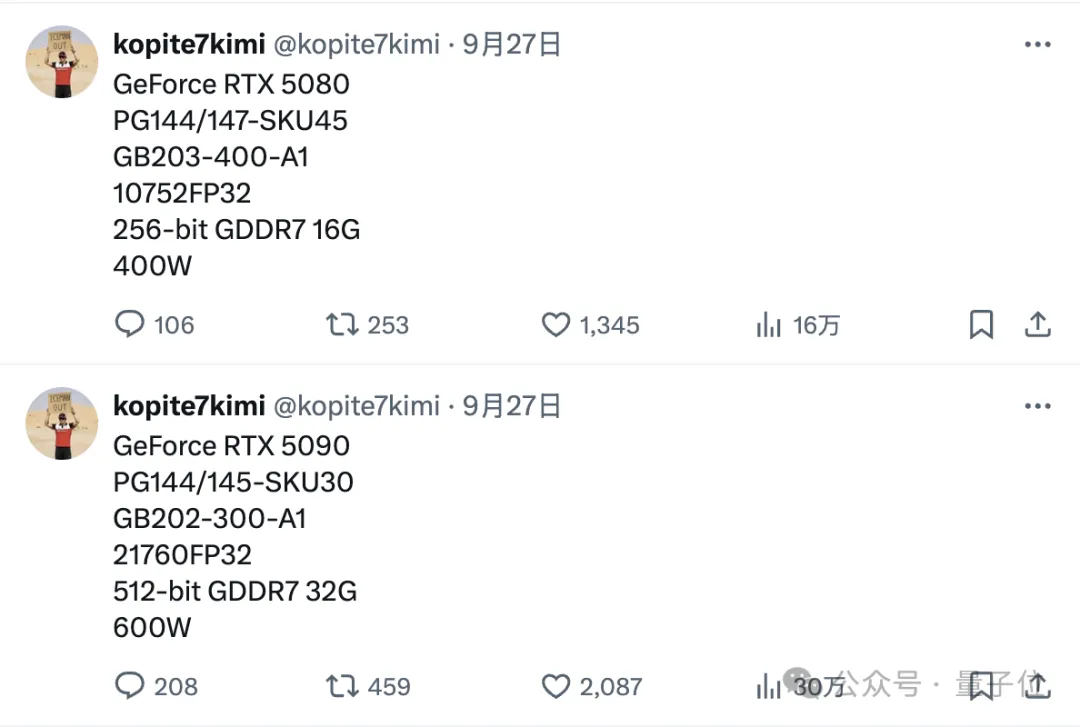
32GB GDDR7内存,CUDA核心数21760个——

人形机器人的此时此刻,恰如2019年自动驾驶爆发前夕。 在1927年上映的《大都会》中,全世界第一部包含人形机器人的角色Maria诞生。

7 月 31 日,Canva 宣布收购总部位于澳大利亚的 AI 生图产品 Leonardo.ai。据了解,此次收购金额可能会达到 3 亿美金,是去年 12 月 Leonardo.ai A 轮融资时估值的 4 倍。收购之后,Leonardo.ai 全部员工都将加入 Canva。
近期,全球知名投资人木头姐旗下的ARK Invest发布报告,预测AI陪伴市场将迎来爆发式增长,收入有望从目前的3000万美元飙升至2030年的700亿至1500亿美元。

Scale AI早早踩对了风口,如今终于一飞冲天了,公司的2024年年化收入预计达到近10亿美元。
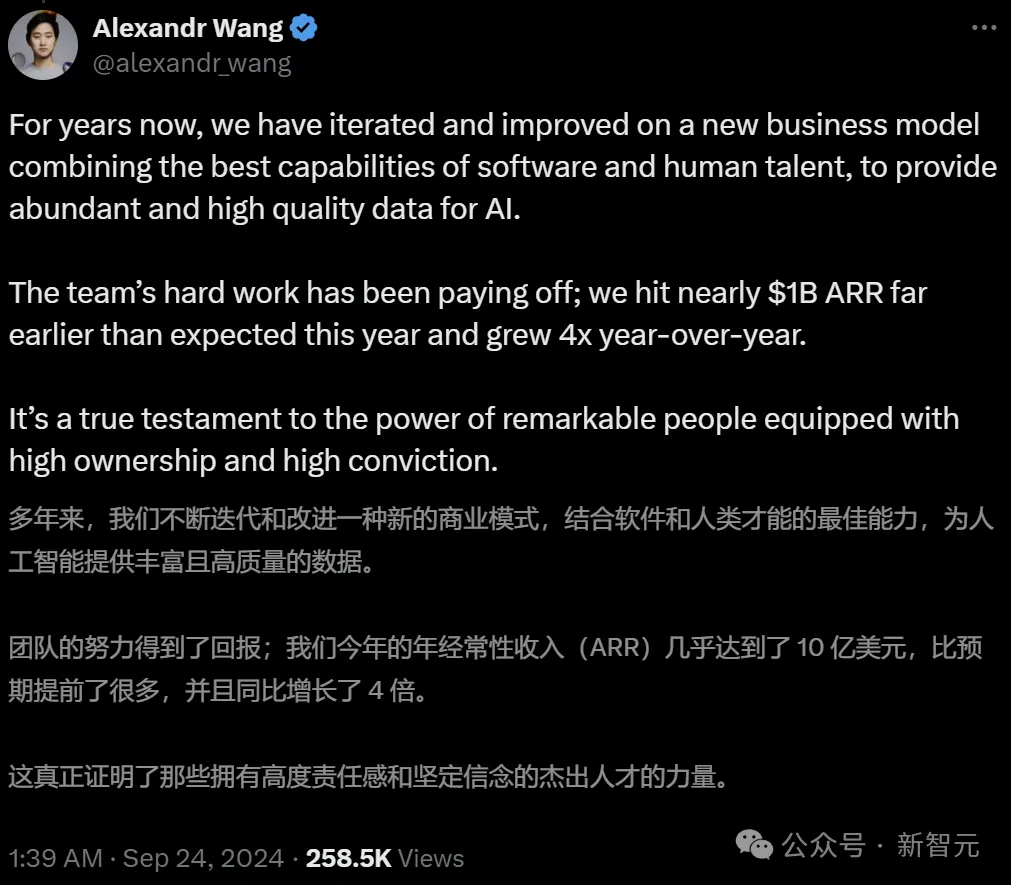
就在刚刚,创业成功的27岁亿万富翁Alexandr Wang宣布—— Scale AI的年化收入,几乎达到了10亿美元! 这个数字,足够震惊整个硅谷的。

AI时代来了,叠加经济下行,越来越多的独立开发者渴望ARR百万美元的故事。

Harmonic获7500万美元A轮融资,估值3.25亿美元。